多数据集多属性模型相似性比较方法
本发明属于人工智能领域,涉及多数据集多属性模型相似性比较方法。
背景技术:
1、当深度学习模型作为开放服务并能够通过接口访问时,不少的恶意者无授权使用模型损害其知识产权。现今,许多互联网公司在大量数据和昂贵的硬件设备的支持下训练获得模型,并将模型作为服务来盈利。但与此同时,这些开放服务本身与模型以及训练他的数据的机密性之间存在矛盾。恶意者可以通过多种方式无授权使用模型,像是模型提取攻击和迁移学习等手段。然而,现阶段深度学习的可解释性差特点,这一特点使得人们在发现这些无授权使用行为上变得困难。无授权使用行为的难以发现使得模型拥有者受到的损害难以确定。在只能访问模型接口,无法获知模型更多的信息时,想要判断给定两个模型的相似程度是存在困难的。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种多数据集多属性模型相似性比较方法。可以实现对两个模型的相似性比较,解决了在只访问模型接口的情况下,比较两个给定模型的相似度。能够在一定程度上实现对深度学习模型的知识产权的保护。
2、为达到上述目的,本发明提供如下技术方案:
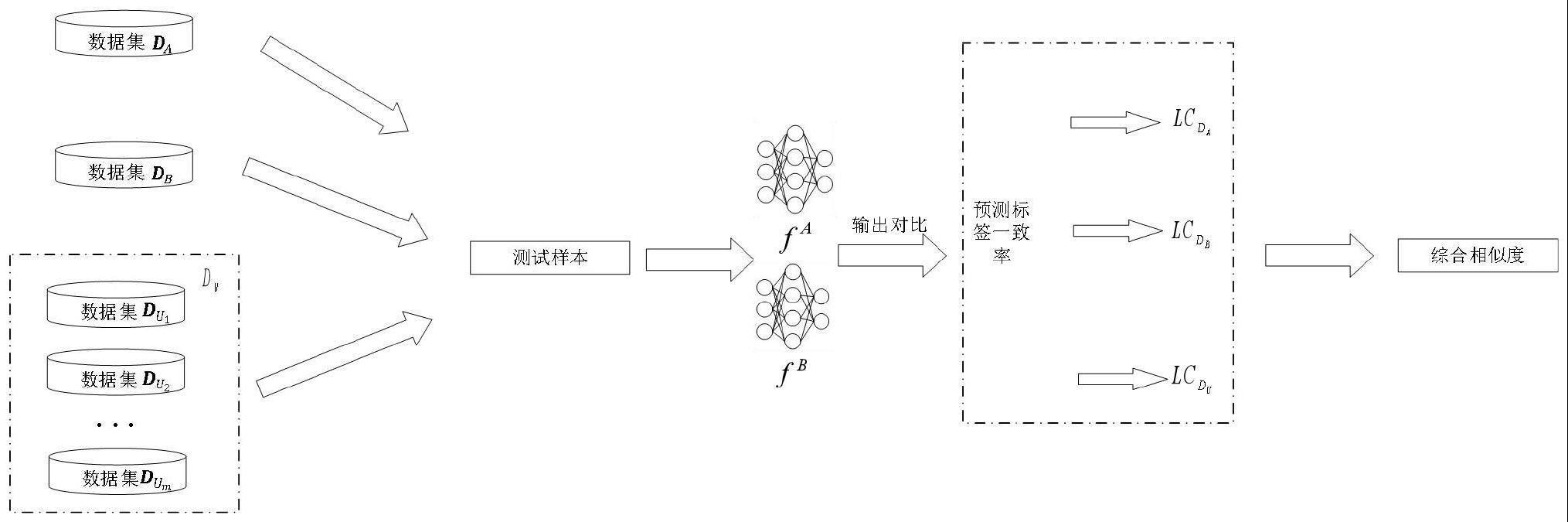
3、多数据集多属性模型相似性度量方法,对于给定的两个模型fa和fb,需判断模型fa和fb的功能是否相似,其包括以下步骤:
4、第一步,获取相应训练集。模型fa的所有者甲方提供其模型的训练数据集da,模型fb的所有者乙方提供其模型的训练数据集db。
5、第二步,选择与甲乙双方所有模型的分类标签语义相关性较弱的数据集du。与待比较模型分类标签语义相关性较弱的数据集du按照以下两个原则筛选,一是之间相互独立,二是内的样本要能够均匀分布在模型的决策空间内,即,
6、p(x)~u(drf)
7、其中x表示的样本集合,drf为测试模型的决策空间。具体的通过预测试,筛选du中能够符合上式的样本集合作为测试样本。
8、第三步,获取测试样本相应的输出;将前两步中获得的合适测试样本分别输入甲乙两方所有模型中获得相应的输出。具体的,甲方所有模型分别在数据集da,数据集db以及与其模型分类标签语义相关性较弱的数据集集合du上得到每个样本对应的预测标签。同理,乙方所有模型获得测试样本对应的预测标签。
9、第四步,比较模型,通过上一步的输出对比两个模型之间的预测标签一致率。具体的甲乙双方所属模型分别在数据集da,数据集db以及与其模型分类标签语义相关性较弱的数据集集合du的输出计算预测标签一致率。预测标签一致率表示为:
10、
11、
12、其中fa(xi)表示模型fa对于样本xi的预测标签,同样的,fb(xi)表示模型fb对于样本xi的预测标签。基于部分训练集测试可以得到抽样预测标签一致率,当样本量足够大时,根据中心极限定理,抽样预测标签一致率的分布表现为正态分布。那么抽样预测标签一致率服从以下分布,即,
13、
14、其中lc为基于部分训练集测试所得预测标签一致率,从而可以估计模型fa和fb在数据集da上对应的总体预测标签一致率,记为其在1-α的置信水平下为,
15、
16、同样的,模型fa和fb在数据集db上得到对应的预测标签一致率,记为
17、模型fa和fb分别在du中的m个数据集上测试得到m个预测标签一致率{lc1,lc2,…,lcm},其中lcj表示模型fa和fb在第j个数据集上的预测标签一致率。为了避免测试过程中由于上述情况产生的异常值,于是计算模型fa和fb在m个数据集上的预测标签一致率的均值,即
18、
19、最后得到待比较模型fa和fb在m个与原模型分类标签语义特征相关性较弱的数据集上的预测标签一致率
20、第五步,形成模型的综合相似度,将上一步计算得到的对应的预测标签一致率值和以及在m个数据集上测试计算得到的预测标签一致率采用多属性固权决策方法,计算其综合相似度φ,即,
21、
22、本发明的有益效果在于:该方法对于给定两个深度学习模型fa和fb,采用不同来源的多个数据集,包括模型fa的全部或部分训练集da、模型fb的全部或部分训练集db以及m个与待比较模型双方分类标签语义特征相关性较弱的数据集。这些数据集可以保证测试样本的多样性以及测试样本之间的独立性。进一步计算多个数据集上的预测标签一致率并综合多来源测试样本形成综合相似性度。解决了在只能访问模型接口,无法获知模型结构信息的情况下,对两个给定的深度学习模型之间的相似度比较。
23、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:
1.多数据集多属性模型相似性比较方法,其特征在于:该方法包括以下步骤:
2.根据权利要求1所述的多数据集多属性模型相似性比较方法,其特征在于:所述s1中,获取相应训练集,的含义如下:
3.根据权利要求1所述的多数据集多属性模型相似性比较方法,其特征在于:所述s2具体为:
4.根据权利要求1所述的多数据集多属性模型相似性比较方法,其特征在于:所述s3中,获取测试样本相应的输出,其含义如下,
5.根据权利要求1所述的多数据集多属性模型相似性比较方法,其特征在于:所述s4中,比较模型的含义如下:
6.根据权利要求1所述的多数据集多属性模型相似性比较方法,其特征在于:所述s5中,形成模型的综合相似度,其含义如下:
技术总结
本发明涉及多数据集多属性模型相似性比较方法,属于人工智能领域。本发明通过同分布输入在对比模型上的输出分布差异来度量模型之间的相似性。本发明选择使用待比较模型双方对应的全部或部分训练集,另筛选合适的与待比较模型双方分类标签语义特征相关性较弱的数据集,将这几个数据集中的样本作为测试样本。然后将合适的测试样本分别输入待比较的两个模型中,获得相应的输出。进一步利用预测标签一致率对比模型,并通过多个来源的数据集以及多个与待比较模型双方分类标签语义特征相关性较弱的数据集综合多数据集多属性形成综合相似度。本发明解决了在无法获取模型结构和参数信息的情况下难以比较判断两个模型的相似度的问题,以达到发现无授权使用深度学习模型行为的目的。
技术研发人员:陈龙,欧阳柳,董振兴
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!