一种基于类间学习进行失败测试用例合成的方法
本发明涉及缺陷定位,特别涉及一种基于类间学习进行失败测试用例合成的方法。
背景技术:
1、软件测试是软件工程中一项重要但资源密集型的任务。同时,软件开发和维护中普遍存在的缺陷修复导致了高昂的测试成本。自动缺陷定位技术可以减少软件开发人员在此过程中的时间和精力。
2、自动缺陷定位技术通过运行测试套件中的每个测试用例来收集覆盖信息和测试结果,然后将覆盖信息和测试结果分别表示为覆盖矩阵和标签。覆盖矩阵和标签是缺陷定位技术的原始数据。在原始数据中,覆盖矩阵的每一行代表一个测试用例,每一列对应一个语句在所有测试用例中的覆盖率信息。每个单元格指示相应语句是否由该条测试用例执行。如果语句被执行,则该单元格的值为1;否则,其值为0。每一条测试用例对应一个标签,若该条测试用例执行成功,则该标签对应为0;若该测试用例执行失败,则对应标签为1。例如,假设有一个程序p包含n个语句,这个程序的测试用例集t包含了m个测试用例,其中至少有一个失败的测试用例。xij=1表示测试用例i执行了语句j,xij=0表示测试用例i没有执行语句j。矩阵m×n记录了测试用例集t中每条语句的执行信息,我们称这个矩阵为覆盖矩阵。标签yi表示第i个测试用例对应的标签,yi=1,表示第i个测试用例是失败的测试用例,yi=0,表示第i个测试用例是通过的测试用例。我们将搜集到的覆盖矩阵与标签称为原始数据(如图一),在获取原始数据后,许多缺陷定位技术将它们用作分析和评估每个缺陷实体的可疑性的输入,例如,两种最流行的fl技术:基于频谱的缺陷定位(sbfl),和基于深度学习的缺陷定位(dlfl)。
3、然而,不管是sbfl技术还是dlfl技术,其定位结果的好坏均受原始数据质量的影响。有研究发现,当原始数据中成功的测试用例和失败的测试用例数量相等时,最有利于缺陷定位技术找到缺陷在程序中的位置。但是真实存在的原始数据中,成功测试用例的数量远远大于失败的测试用例,这会影响到缺陷定位技术的准确性。
技术实现思路
1、针对现有技术存在的上述问题,本发明的要解决的技术问题是:如何解决缺陷定位技术原始数据中存在的数据不平衡性问题。
2、为解决上述技术问题,本发明采用如下技术方案:一种基于类间学习进行失败测试用例合成的方法,包括如下步骤:
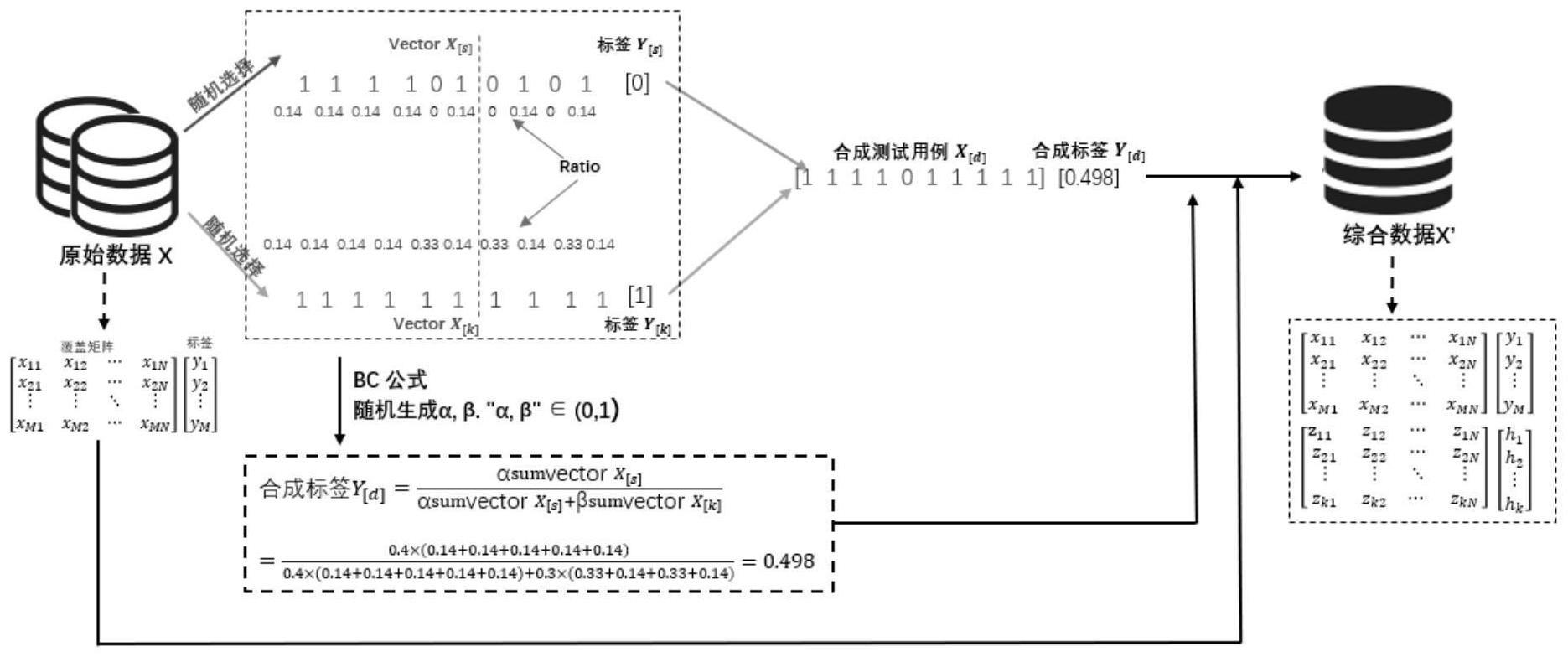
3、s100:从原始数据中随机选择两个标签不一致的测试用例(也称为两个向量),记:vector x[s],vectorx[k];
4、s200:为两个向量中的每一条语句分配权重ratio。
5、s210:找出在失败测试用例中执行过却未在成功测试用例中执行过的语句,计算它们的数量并为其分配权重,权重计算公式如下:
6、
7、其中,count是在失败测试用例中执行却未在成功测试中执行的语句数量。ratio是为上述语句分配的权重值。
8、s220:为剩下的语句分配权重,其中,无论是在失败的测试用例中还是成功的测试用例中,未执行的语句均赋值为0。执行的语句分配权重的计算公式如下:
9、
10、其中,ratio′为被执行过的语句(无论是在成功的测试用例中还是在失败的测试用例中),count′为该语句对应测试用例中,除count以外的被执行语句总数。
11、s300:随机获取一个切割位置n,n介于0-测试用例语句总数之间。
12、s400:将向量vector x[s]的0-n条语句的执行情况,与vectorx[k]的n+1到最后一条语句的执行情况拼接起来,得到新的测试用例(也可称为新的向量)vectorx[d].
13、s500:计算vectorx[d].对应的标签y[d],计算公式如下:
14、
15、其中,α,β为0-1之间的随机数,sumxs,sumxk为对应测试用例中,被截取到的每条语句的权重总和,其计算方式如下:
16、
17、a为测试用例被截取的起始位置,b为测试用例被截取到的结束位置。
18、s600:将合成测试用例加入原始数据中,称其为综合数据。检查综合数据中标签为1的测试用例和标签不为1的测试用例数量是否一致,若一致则进行s700,否则重复s100-s600。
19、一种基于类间学习获取平衡数据的应用,所述基于类间学习获取平衡数据采用杉树的方法获得,将所述基于类间学习获取的综合数据作为综合数据作为sbfl和dlfl技术的输入,用于进行缺陷定位。
20、相对于现有技术,本发明至少具有如下优点:
21、1.本发明利用bc公式对缺陷定位技术的原始数据进行合成,得到新的有利于缺陷定位技术的合成测试用例。通过本发明方法可以获得的数据中,失败的测试用例与成功测试用例的数量相等,从而大大提升缺陷定位技术的性能。
22、2.本发明方法只利用原有的测试用例进行拆分和组合,对测试用例对应的标签只需要用公式进行计算,另外,该方法设计出来的公式,是自己根据测试用例的特征设计的。例如,对于在失败测试用例中执行的语句具有更高的可疑性。
23、3.当原始数据中的成功测试用例与失败测试用例数量相等时,最有利于缺陷定位技术的准确性,这是因为成功的测试用例和失败的测试用例都包含对缺陷定位技术有利的信息。然而在真实世界中生成失败测试用例耗费的时间、金钱数量巨大。本发明通过合成测试用例的方法,既节省了时间金钱,又能够得到对缺陷定位技术有用的测试用例。
技术特征:
1.基于类间学习进行失败测试用例合成的方法,其特征在于,包括如下步骤:
技术总结
本发明公开了一种基于类间学习进行失败测试用例合成的方法,该方法首先抽取出两条结果不同的测试用例。之后对这两条测试用例中的语句分配不同的权值,然后随机生成一个切割位置,合成新的测试用例,利用BC公式计算合成测试用例对应的标签。最后,将新的合成测试用例和对应的标签加入原数据集中,作为缺陷定位方法的输入。该方法基于类间学习合成对缺陷定位方法有用的合成测试用例,更有利于实际工程中的应用。
技术研发人员:雷晏,刘春燕,徐春香,谢欢,李茂锦
受保护的技术使用者:重庆大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!