一种大规模图数据高效查询方法
本发明涉及数据处理,特别是一种大规模图数据高效查询方法。
背景技术:
1、随着rdf数据规模的日益增长,设计高性能的大规模图数据高效查询方法,以支持复杂的业务需求是一个亟待解决的问题。rdf数据在逻辑上是基于节点与关系的图结构,图中的语义结构以及聚类信息非常关键,在分布式存储时,如果将关联密切的数据存储在同一分区,就可以减少跨分区查询的次数,从而提高查询效率。合理的存储模型不仅能为上层应用提供快速的查询服务,也能便于对数据和系统进行维护,例如负载均衡与动态更新。此外,查询和存储密切相关,互相影响,在考虑如何分布式存储时,应该以查询效率最高为目标。sparql是查询rdf数据的有效工具,因此要解决rdf高效查询的问题,需要结合存储模型,设计一种高效的sparql查询引擎处理各种复杂的查询请求。
2、现有技术方案:
3、安徽华云安科技有限公司的专利申请“基于知识图谱集群的数据查询方法和装置”(专利申请号:cn202211617863.4),其特征在于,包括:响应于接收到当前数据查询请求,将所述当前数据查询请求添加至查询请求消息队列;根据所述目标数据查询请求,在图数据库中确定对应的索引;根据确定的索引,在关系数据库中确定对应的数据本体,将所述数据本体添加至消息输出队列。缺点是:查询方法和装置需要大量的计算资源和存储资源,因此需要投入大量的资金和人力成本;集群需要定期维护和更新,否则就会出现数据不准确或查询结果不完整等问题,这需要专业的技术人员进行维护。
4、抖音视界有限公司的专利申请“基一种图数据查询方法及装置”(专利申请号:cn202210991887.x),其特征在于,包括:响应于数据查询请求,确定所述数据查询请求指示的查询语句;按照预定义顺序依次解析所述查询语句中的各个查询字段,若为设置的入口类型的目标字段,则调用目标字段解析器的目标查询指令;根据查询指令从所述图数据中进行数据查询,生成所述查询语句对应的查询结果。缺点是:图数据库需要存储大量的节点和关系信息,占用了大量的存储空间,对于大规模数据的查询,可能需要更大的存储空间,增加了成本和难度;
5、杭州悦数科技有限公司的专利申请“一种加速图数据库数据查询的方法、系统、装置和介质”(专利申请号:cn202210957310.7),其特征在于,所述方法包括:当图数据写入到所述图数据库中的存储节点后,将所述图数据同步到所述拓扑节点;通过所述拓扑节点存储所述图数据的图拓扑关系,基于所述拓扑节点中存储的图拓扑关系完成查询请求。缺点是:需要依赖专门的硬件设备,例如图处理器或者加速卡等。这些设备成本较高,且需要专业技术人员进行维护和管理;受限于数据大小,当数据集非常大时,查询速度可能仍然很慢。
技术实现思路
1、鉴于此,本发明提供一种大规模图数据高效查询方法,以解决上述技术问题。
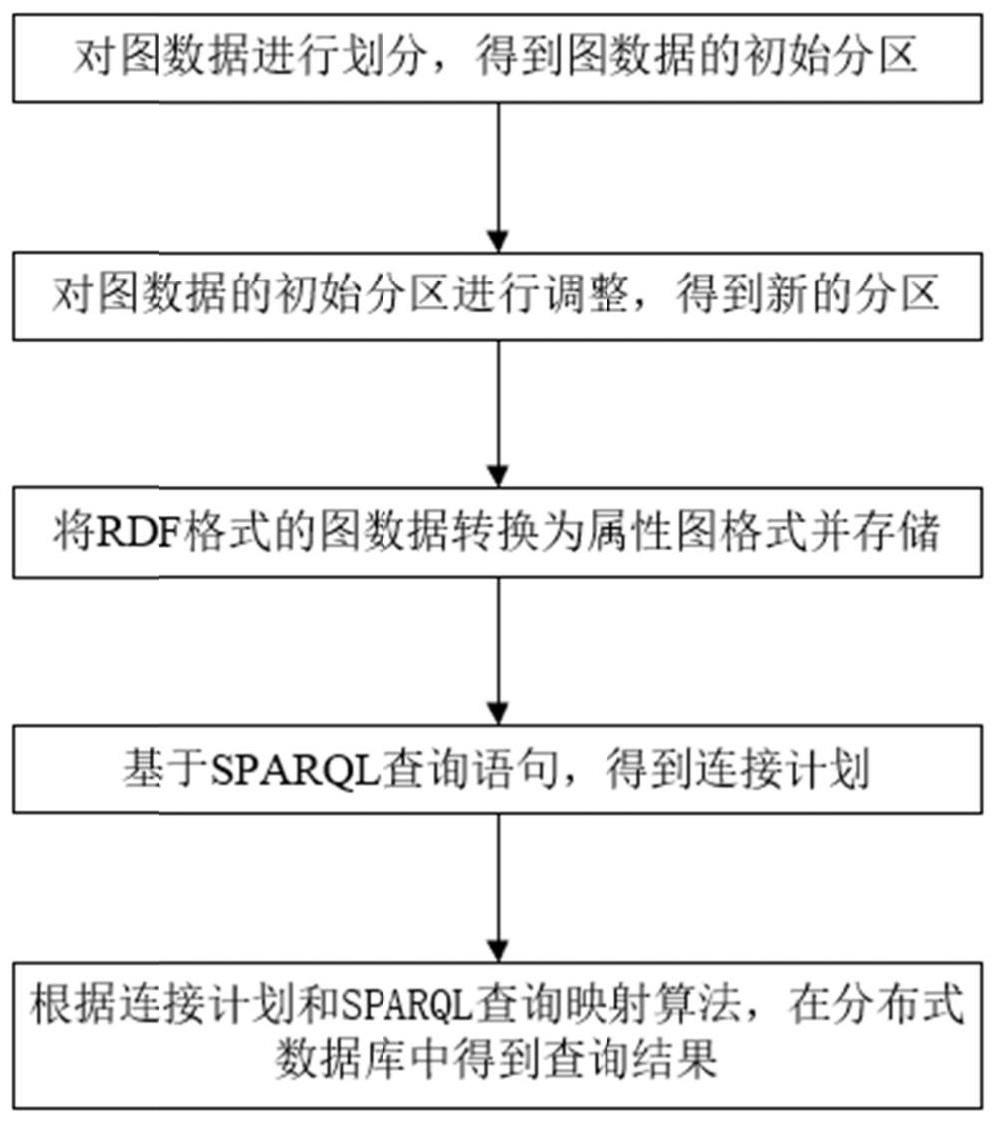
2、本发明公开了一种大规模图数据高效查询方法,应用于对分布式数据库中图数据的查询,其包括:
3、步骤1:对图数据进行划分,得到图数据的初始分区;其中,所述初始分区包括每个顶点向量的二进制签名以及对应的哈希桶;
4、步骤2:对图数据的初始分区进行调整,得到新的分区;
5、步骤3:将rdf格式的图数据转换为属性图格式并存储;
6、步骤4:基于sparql查询语句,得到连接计划;
7、步骤5:根据连接计划和sparql查询映射算法,在分布式数据库中得到查询结果。
8、进一步地,所述步骤1具体包括:
9、选取word2vec作为向量化工具,将每个顶点的各个属性表示为词向量,利用加权平均模型计算出顶点向量;
10、将所有顶点向量作为局部敏感哈希算法的输入,得到每个顶点向量的二进制签名以及对应的哈希桶;
11、所述步骤2包括:
12、假设现有图数据的初始分区包括k个分区结果p={p1,p2,...,pk},每个分区的最大负载maxsize;现有图数据为g=(v,e),v={v1,...,vn}为顶点集合,e={e1,...,em}为边集合,|v|=n,|e|=m;
13、分别计算vi在pi中的scoreadjacent得分;
14、将pi中的所有vi按照scoreadjacent大小排序;
15、当从scoreadjacent得分最小的vi开始,分别计算vi在其他分区的scoremove(vi,p)得分,将所有得分排序并取出vi得分最大的分区pj;
16、当取出vi得分次大的分区pj;否则,将vi分配给pj并且更新pi以及缓存表;
17、最终输出调整后的分区。
18、进一步地,所述步骤3包括:
19、将rdf格式转换为属性图格式,然后以顶点为存储粒度,作为hbase的每一行,存储与该顶点相关的属性与关系。
20、进一步地,所述步骤3具体包括:
21、分别针对每条三元组数据<s,p,o>,根据resource确定顶点的类型,将uri作为顶点的一个属性;
22、若o是文字,则将p作为顶点的属性名,o作为顶点属性值;
23、若o是资源,则将p映射为边,对p进行唯一编号,p的值作为属性值;将s和o的uri也作为p的属性,代表p连接的两个顶点。
24、进一步地,所述步骤4包括:
25、步骤41:解析sparql查询语句,得到每个主语变量的三元组模式集合plan={t1,t2,…tp};所述sparql查询语句包含n个三元组模式t={t1,t2,…tn};
26、步骤42:从包含三元组模式最多的集合开始遍历,依次删除前面已经遍历过的三元组模式,得到连接计划,所述连接计划包含m个集合plan={t1,t2,…tm},每个集合代表一个三元组模式子集。
27、进一步地,所述步骤42具体包括:
28、在plan={t1,t2,…tp}中依次遍历ti:
29、若ti中包含主语已知的三元组模式tj,则将tj排在第一个位置并将ti标记为type-s;
30、若ti中包含谓词和宾语已知的三元组模式tj,则将tj排在第一个位置并将ti标记为type-po;
31、若ti中不包含主语以及谓词和宾语已知的三元组模式tj,将tj中的子句首先按照变量个数从小到大排序;如果出现tj和tk的变量个数相同,则已知谓词的排在前面;如果tj和tk都已知谓词,则在二级索引表中扫描,将结果集小的排在前面;
32、遍历结束后,得到连接计划。
33、进一步地,通过spark的并行计算能力执行生成连接计划:
34、在生成连接计划的任务提交给spark之后,假设一个查询语句由两个三元组模式{t1,t2}组成,经过分析两个子句并行执行:
35、首先在hbase中查询到两个三元组模式对应的数据,并分别抽取变量的值,形成新的结果集,再与抽取出的变量的值进行连接操作,形成最终的结果集;
36、然后再次从最终的结果集中提取所需的键或者值;
37、最终将所需的键或者值转换为内存数组。
38、进一步地,所述步骤5包括:
39、初始化当前的rdd为第一次循环的结果;rdd为key-value键值对,key表示要连接的变量,value表示迭代过程中的非连接变量;
40、在连接计划包含的m个集合plan={t1,t2,…tm}中开始遍历:
41、若ti有标识type-sortype-po,则通过sparql查询映射算法执行ti中的第一个语句得到结果rows;根据rows将ti中剩余的子句变量进行绑定;将所有结果合并,形成newrdd并保存在内存中;否则,在ti中对tj进行遍历:通过sparql查询映射算法得到结果集;根据查询条件调整key-value,将结果转换为newrdd;将newrdd与上一步的rdd连接形成新的newrdd并保存在内存中;
42、所有的遍历结束后,取出结果集中的需要的值,即得到查询结果。
43、进一步地,所述sparql查询映射算法为:
44、在输入三元组数据<s,p,o>之后,
45、当s已经绑定,则在hbase主表中查询;
46、当s未绑定,若p已经绑定且s是变量,则在索引表中查询;
47、若s和p均未绑定,扫描主数据表;
48、最终得到扫描结果集。
49、进一步地,在所述当s已经绑定时,则在hbase主表中查询中:
50、当p已经绑定,若p是属性,则在row中查找属性值;否则,在row中查找关系的另一端顶点;
51、当p未绑定且o已经绑定,若o是属性值,则在属性值列族中过滤出属性名;否则,在关系列族中过滤出关系;
52、当p和o均未绑定,取出row中和s相关的所有p和o过滤;
53、在当s未绑定,若p已经绑定且s是变量,则在索引表中查询中:
54、若o已经绑定,则定位到谓词对应的row,再通过宾语进行过滤。
55、由于采用了上述技术方案,本发明具有如下的优点:
56、1.本发明提出的基于图划分的海量知识分布式存储模型,并在分布式存储的基础上,提出了sparql查询优化方法,提高了海量语义数据的访问效率。
57、2.针对大规模rdf数据分区存储未充分考虑数据的语义关联,导致查询时通信开销较大的问题,提出了一种结合语义信息与拓扑结构的rdf数据划分算法,提高划分速度并优化划分结果。
58、3.为进一步提高执行效率,采用spark构建sparql查询引擎,提出了sparql查询映射算法,将sparql查询语句中的三元组模式提交为hbase的行键查询,高效地执行查询任务。
- 还没有人留言评论。精彩留言会获得点赞!