在推断期间中对图形处理器的协调和增加利用的制作方法
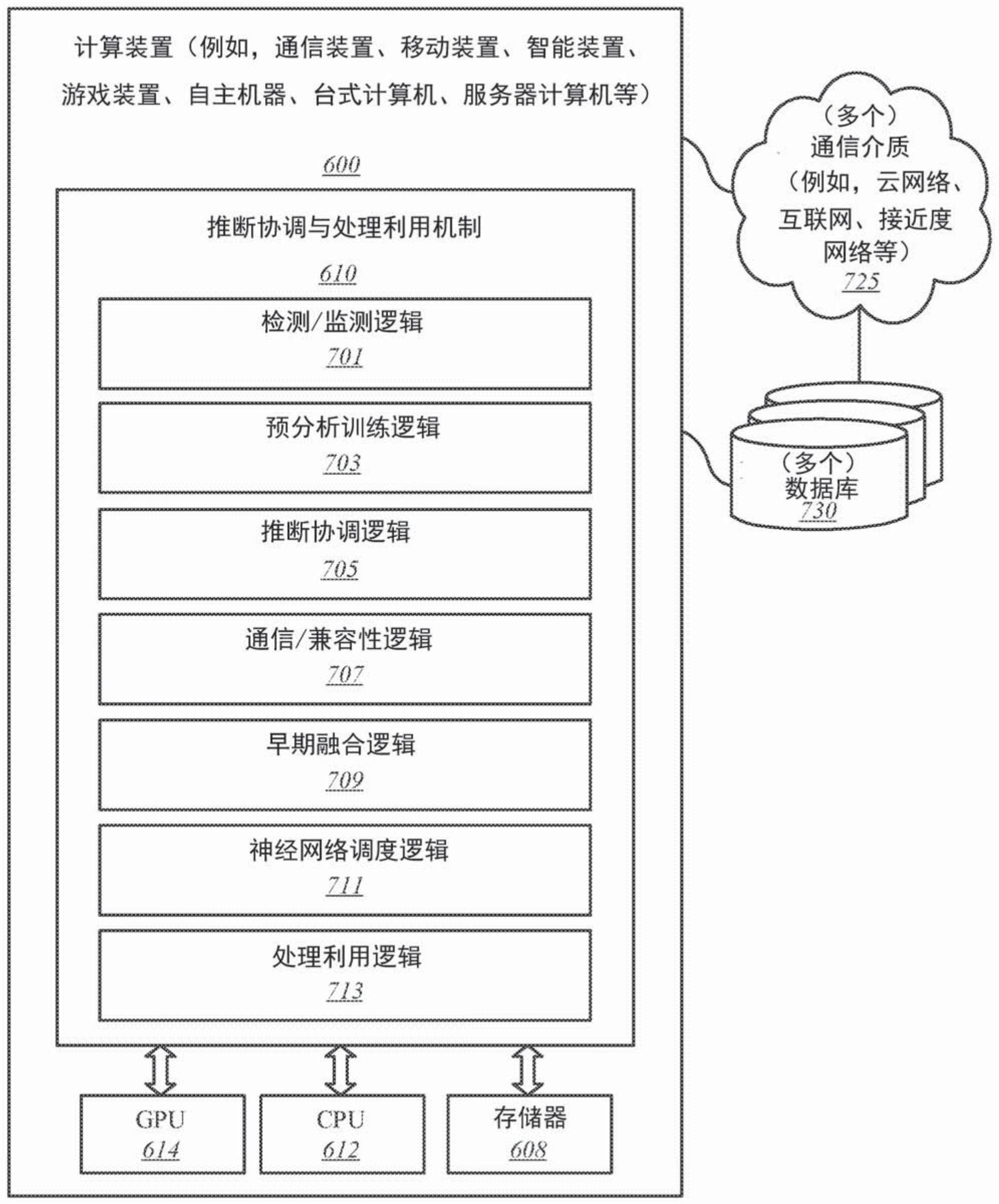
本文所描述的实施例总体上涉及数据处理,并且更具体地涉及促进一种用于在推断期间对图形处理器进行协调和增加利用的工具。
背景技术:
1、当前的并行图形数据处理包括被开发用于对图形数据执行特定操作的系统和方法,诸如,例如线性插值法、曲面细分、栅格化、纹理映射、深度测试等。传统上,图形处理器使用固定函数计算单元来处理图形数据,然而近来,图形处理器的多个部分已经可编程,从而使得此类处理器能够支持用于处理顶点和片段数据的更广泛种类的操作。
2、为了进一步提高性能,图形处理器通常实现诸如流水线操作的处理技术,这些处理技术尝试贯穿图形流水线的不同部分并行地处理尽可能多的图形数据。具有单指令多线程(simt)架构的并行图形处理器被设计成使图形流水线中的并行处理量最大化。在simt架构中,多组并行线程尝试尽可能经常地一起同步执行程序指令,以提高处理效率。用于simt架构的软件和硬件的一般性概述可以在以下两者中找到:shane cook的cuda编程(cudaprogramming),第3章,第37到51页(2013年)和/或nicholas wilt的cuda手册(gpu编程的综合指南(a comprehensive guide to gpu programming)),章节2.6.2到3.1.2(2013年6月)。
3、机器学习在解决很多种任务方面已经成功。在训练和使用机器学习算法(例如,神经网络)时产生的计算使其本身自然地用于有效的并行实施。因此,诸如通用图形处理单元(gpgpu)的并行处理器在深度神经网络的实践实施中起到重要作用。具有单指令多线程(simt)架构的并行图形处理器被设计成使图形流水线中的并行处理量最大化。在simt架构中,多组并行线程尝试尽可能经常地一起同步执行程序指令,以提高处理效率。由并行机器学习算法实施提供的效率允许使用大容量网络并且使得那些网络能够在更大数据集上进行训练。
4、常规技术并未提供推断输出与负责提供输入的传感器之间的协调;然而,此类常规技术没有提供推断输出的准确性。此外,在图形处理器上使用推断相当少,而其余图形处理器未被利用。
技术实现思路
技术特征:
1.一种非暂态机器可读存储介质,具有存储于其上的可执行计算机程序指令,所述可执行计算机程序指令当由一个或多个机器执行时,使所述一个或多个机器执行包括以下各项的操作:
2.如权利要求1所述的存储介质,其中,一个或多个上下文对所述多个流处理器的使用被部分地限制以提高所述多个流处理器的利用率。
3.如权利要求2所述的存储介质,进一步包括当由所述一个或多个机器执行时使所述一个或多个机器执行包括以下各项的操作的可执行计算机程序指令:
4.如权利要求2所述的存储介质,其中,所述操作附加地包括部分地基于控制目标和来自调度器的需求来调整对用于所述一个或多个上下文的线程的限制。
5.如权利要求1所述的存储介质,其中,所述多个流处理器包括单指令多线程simt架构。
6.如权利要求5所述的存储介质,其中,所述simt架构包括硬件多线程。
7.如权利要求1所述的存储介质,其中,所述多个流处理器中的每一个耦合到数据高速缓存。
8.如权利要求7所述的存储介质,其中,数据端口耦合到所述数据高速缓存以针对经由所述数据端口的存储器访问对数据进行高速缓存。
9.一种非暂态机器可读存储介质,具有存储于其上的可执行计算机程序指令,所述可执行计算机程序指令当由一个或多个机器执行时,使所述一个或多个机器执行包括以下各项的操作:
10.如权利要求9所述的存储介质,其中,对用于所述一个或多个上下文的线程的所述限制被至少部分地提供以提高所述多个流处理器的利用率。
11.如权利要求10所述的存储介质,其中,所述多个流处理器的利用率由所述系统监测。
12.如权利要求10所述的存储介质,其中,所述操作附加地包括部分地基于控制目标和来自调度器的需求来调整对用于所述一个或多个上下文的线程的所述限制。
13.如权利要求9所述的存储介质,其中,所述多个流处理器包括单指令多线程simt架构。
14.如权利要求13所述的存储介质,其中,所述simt架构包括硬件多线程。
15.如权利要求9所述的存储介质,其中,所述多个流处理器中的每一个耦合到数据高速缓存。
16.如权利要求15所述的存储介质,其中,数据端口耦合到所述数据高速缓存以针对经由所述数据端口的存储器访问对数据进行高速缓存。
17.一种系统,包括:
18.如权利要求17所述的系统,其中,对用于所述多个上下文的线程的所述限制至少部分地由所述系统提供以提高所述多个流处理器的利用率。
19.如权利要求18所述的系统,其中,所述系统进一步用于监测所述多个流处理器的利用率。
20.如权利要求17所述的系统,其中,所述多个流处理器包括单指令多线程simt架构。
21.如权利要求20所述的系统,其中,所述simt架构包括硬件多线程。
22.如权利要求17所述的系统,其中,所述多个流处理器中的每一个耦合到数据高速缓存。
23.如权利要求22所述的系统,其中,数据端口耦合到所述数据高速缓存以针对经由所述数据端口的存储器访问对数据进行高速缓存。
技术总结
本申请公开了在推断期间中对图形处理器的协调和增加利用。描述一种用于促进自主机器处的机器学习的推断协调与处理利用的机制。如本文所描述,实施例的一种方法包括:在训练时根据与包括图形处理器的处理器相关的训练数据集来检测与将要执行的一个或多个任务相关的信息。所述方法还可以包括:分析所述信息以确定能够支持所述一个或多个任务的与所述处理器相关的硬件的一个或多个部分;以及将所述硬件配置成预先选择所述一个或多个部分来执行所述一个或多个任务,而所述硬件的其他部分保持可用于其他任务。
技术研发人员:A·R·阿普,A·考克,J·C·韦斯特,M·B·麦克弗森,L·L·赫德,S·S·巴格索克希,J·E·高茨施里奇,P·萨蒂,C·萨科斯维尔,马立伟,E·乌尔德-阿迈德-瓦尔,K·辛哈,J·雷,B·文布,S·加哈吉达,V·兰甘纳坦,D·金
受保护的技术使用者:英特尔公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!