一种面向多传感器数据融合需求的三维场景感知方法
本发明属于计算机领域,具体涉及一种面向多传感器数据融合需求的三维场景感知方法。
背景技术:
1、三维人体重建方法可以作为三维感知方法的一部分,因为人体是三维世界中的主要元素之一。人体的位置、形状、姿态和动作等信息对于很多应用都是非常重要的,比如虚拟现实、智能监控、医学诊断等领域。通过三维人体重建方法,可以从图像、视频、深度相机等传感器数据中获取人体的三维位置、形状和运动信息,从而实现对人体的三维感知。
2、传感器技术和深度学习的最新进展导致三维场景感知方法取得了重大进展。然而,大多数现有方法都依赖于来自特定传感器的数据,由于个体传感方式的固有局限性,这些数据可能不可靠。虽然现有的多模态融合方法通常需要根据特定的传感器组合或设置进行定制设计,但灵活性有限。
3、但是,组合多模态信息并不容易。早期的激光雷达-相机融合方法采用点到图像投影,通过逐元素相加或逐通道级联来组合点云和rgb图像像素值。这些方法严重依赖于点云和图像之间的投影关系,如果其中一种模式受到损害或失败,这种关系可能会崩溃。最近,已经提出了几种定制的基于transformer的结构用于多模态融合。然而,这些融合框架需要针对不同的传感器配置进行专门设计,这很难扩展到其他传感器组合。尽管有各种融合方法,但如何以与模式无关的方式整合来自不同传感器设置和组合的信息仍未开发。特别是,为不同的传感器组合采用专门的算法和对齐功能需要大量努力。
4、近年来,基于transformer的融合方法受到了广泛关注。具体来说,deepfusion使用可学习的对齐机制激光雷达信息与最相关的图像动态关联起来,但是deepfusion方法缺少全局特征,从而减少了融合阶段的全局交互。tokenfusion裁剪单模态transformer层中的特征标记以保留更好的信息,然后重新利用裁剪后的标记进行多模态融合,但tokenfusion方法无法适应不利环境,因此在光线不好的环境中表现出较差的性能。transfusion采用软关联方法来处理劣质图像情况。
技术实现思路
1、本发明目的在于针对现有实验均使用特定模态数据的场景以及现有多模态数据融合方法不能解决现有问题,提出一种面向多传感器数据融合需求的三维场景感知方法。
2、本发明的目的是通过以下技术方案实现的:
3、一种面向多传感器数据融合需求的三维场景感知方法,该方法包括以下步骤:
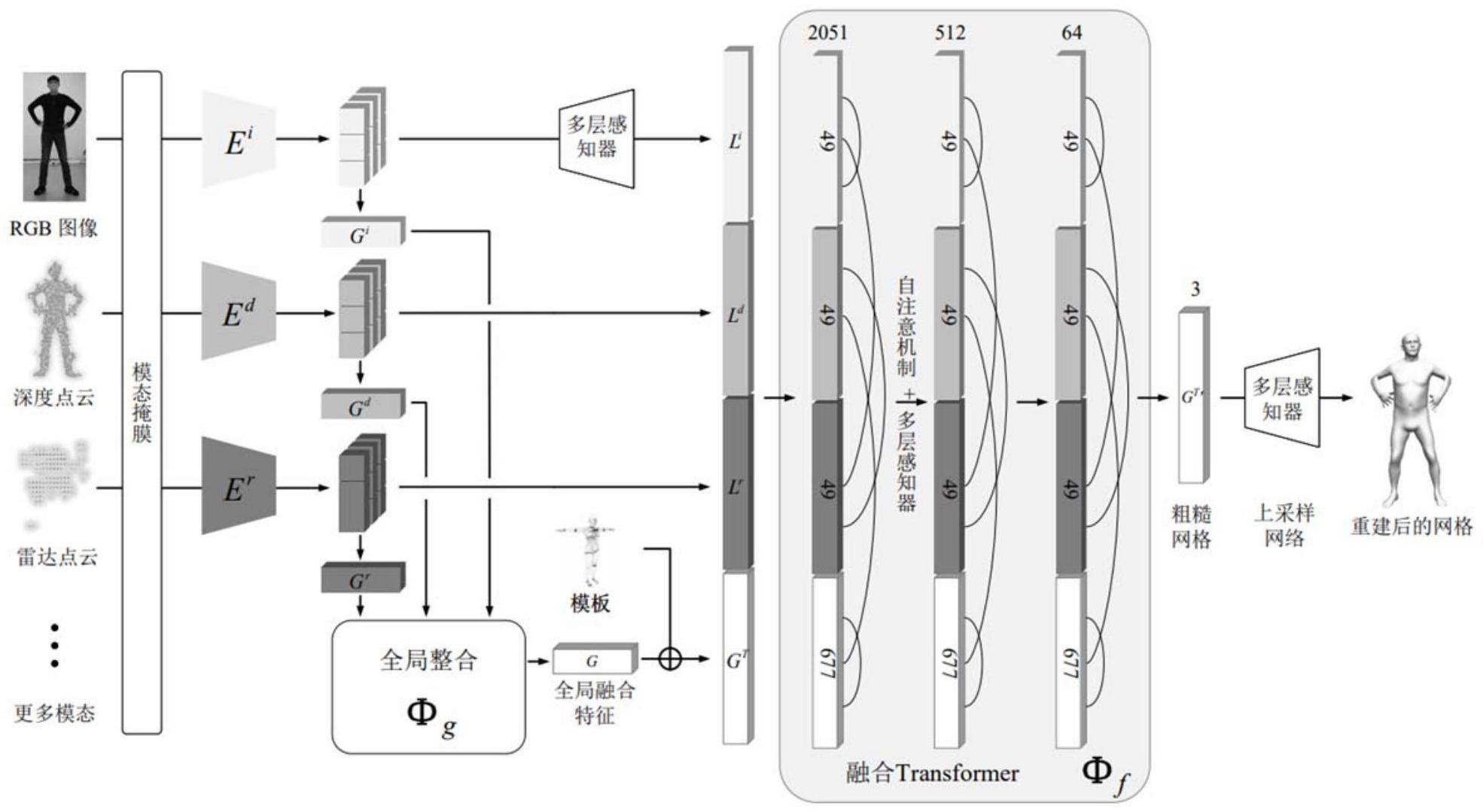
4、s1,从原始多模态的数据中裁剪得到仅包含身体部位的感兴趣区域;
5、s2,将s1中得到的裁剪后的不同模态的数据进行模态掩膜;
6、s3,将掩膜后得到的数据中不同的模态分别独立提取全局特征和局部特征;
7、s4,全局整合各种模态数据的局部特征,融合成一个全局特征向量;
8、s5,将s3和s4中得到的局部特征和全局特征向量输入到融合transformer网络模型中进行训练;
9、s6,直接输入原始多模态数据,进行分别独立提取全局特征和局部特征,并进行全局整合,得到全局特征向量输入到训练好的融合transformer网络模型中,动态融合信息得到粗糙网格gt',上采样后得到最终重建出的人体网格。该部分重建人体网格的方法即为一种三维场景感知的方法,即通过三维传感器如激光雷达、深度相机等获取场景中物体的三维位置、形状等信息,从而实现场景理解、物体检测、路径规划等应用。
10、进一步地,所述步骤s1具体为:
11、利用从数据集中网格关节点的真实值,使用自动标注的边界框裁剪原数据;裁剪后得到所需数据集d={it,pt,jt,vt},t=0,...,n,其中是裁取出身体部分的rgb图像和深度点云,是在时间t标注的22个关节点和10475个顶点的具体位置,每一帧rgb图像包括不同输入模态之间的随机取样。
12、进一步地,所述步骤s2中做法具体为:
13、对s1中得到的数据随机屏蔽一些输入模态,从而强制模型在不同的输入模态组合中学习;关节/顶点标记特征gt进行随机掩膜,模拟自身或烟雾遮挡和缺失部分。
14、进一步地,所述步骤s3具体为:
15、s301:将模态掩膜后得到的图像和点云的人体区域输入到现有图像和点云主干网络,以提取全局特征和局部特征;
16、s302:使用一个共享的hrnet获取rgb图像i的梯度特征和全局特征其中n为通道数,m为特征维度,hrnet输出得到的梯度特征和全局特征输入到第一多层感知器中生成局部特征;
17、s303:深度点云特征使用点云处理网络得到点云局部特征其中n表示最远点采样中采样的点的数量,3表示空间坐标,p表示从集群局部点中提取出的特征的维度;
18、s304:从点云局部特征ld使用第二多层感知器提取出点云全局特征向量
19、
20、进一步地,所述步骤s4具体为:
21、通过将22个关节点和655个顶点坐标与一个从smpl-x降采样得到的粗糙的网格模板联系起来,从而实现位置嵌入;每个模态的序数都嵌入到局部特征中,以简化训练;所有局部特征都用于为人体重建提供细粒度的局部细节,得到全局特征向量。
22、进一步地,所述步骤s5中的训练过程为:
23、s3和s4中得到的局部特征和全局特征向量,对s5步骤中的融合transformer网络结构进行训练;对每个场景选择训练集和测试集,其中训练集随机分成多个部分,每个部分由输入模态的组合组成;在整个测试集上测试所有模态组合,以比较不同模型之间的性能,并将l1损失函数应用于重建的网格以约束顶点和关节。
24、进一步地,所述步骤s6中做法具体为:
25、s601:利用融合transformerφf从任意模态中选择信息性标记特征来动态融合信息,φf在关注有效特征并限制不需要的特征的同时,采用从全局特征g生成的关节点/顶点查询gt和从局部特征生成的模态标记之间的交叉注意,以聚合多模态输入的相关信息;
26、s602:使用多层感知器实现的线性投影网络将输出的粗糙网格上采样,得到最终重建出的人体网格。
27、进一步地,在融合transformer中使用多头注意力机制减轻由于毫米波信号的稀疏性和噪声以及全模态输入的极端条件下rgb或深度信息的不足而导致的特征退化。
28、本发明的有益效果是:
29、1、提出一种多传感器数据融合下的三维场景感知方法。
30、2、使用提出的框架实现对三维人体模型的准确重建。
31、3、克服传统方法依赖特定传感器的局限性,使用本发明可以获得更加可靠的结果。
32、4、克服早期激光雷达-相机融合方法依赖于点云和图像之间的投影关系的问题,生成更加鲁棒的结果。
33、5、使用模态掩膜的方法解决失真问题。
34、6、实现多种模态下任意组合情况下的数据处理,适用于多种不同模态下的三维场景感知。
35、7、在三维场景感知领域中首次提出使用融合transformer以使用不同模态数据的随机组合实现人体重建的方法。
- 还没有人留言评论。精彩留言会获得点赞!