一种面向DCU的OpenMPOffload寄存器优化方法与流程
本发明涉及一种面向dcu的openmp offload寄存器优化方法。
背景技术:
1、openmp提供了并行描述的高层抽象,降低了并行编程的难度和复杂度,使开发人员可以把更多的精力投入到并行算法本身,而非其具体实现细节。openmp 4.0版本之后引入了offload卸载功能,更是大大简化了异构编程的难度,使openmp成为异构编程的热门选择。
2、在openmp中,可以通过num_teams和num_threads子句来指定线程组(team)以及每个线程组所包含的线程数(thread)。对于单线程来说,可用寄存器资源是固定的,如果一个线程组中的线程数为1024、512、256,那么对应的其可用vgpr的数量为64、128、256。因此如果单线程使用的寄存器数量过多,导致寄存器溢出,由于访问内存速度远远慢于寄存器访问速度,就会严重影响程序性能。在openmp offload的过程中,llvm为了使线程可以处理任意上界的循环,会对所有线程做迭代处理,这样保证了线程在整个循环中一直占据着分配的寄存器,但有时它确是不必要的。不分情况的统一做法导致寄存器使用数量的增加,加大了寄存器溢出风险。
3、对于循环展开优化,llvm(构架编译器)中的loopunrollpass设计的是通用情况,无法针对国产dcu后端以及指令集特征进行特殊的适配处理。使得默认计算出的展开因子的优化效果达不到最佳性能。
技术实现思路
1、有鉴于此,本发明的目的是提供一种面向dcu的openmp offload寄存器优化方法,用以解决现有技术中寄存器使用数量多,存在溢出风险的技术问题。
2、为实现上述目的,本发明所提供的面向dcu的openmp offload寄存器优化方法采用如下技术方案:
3、一种面向dcu的openmp offload寄存器优化方法,包括如下步骤:
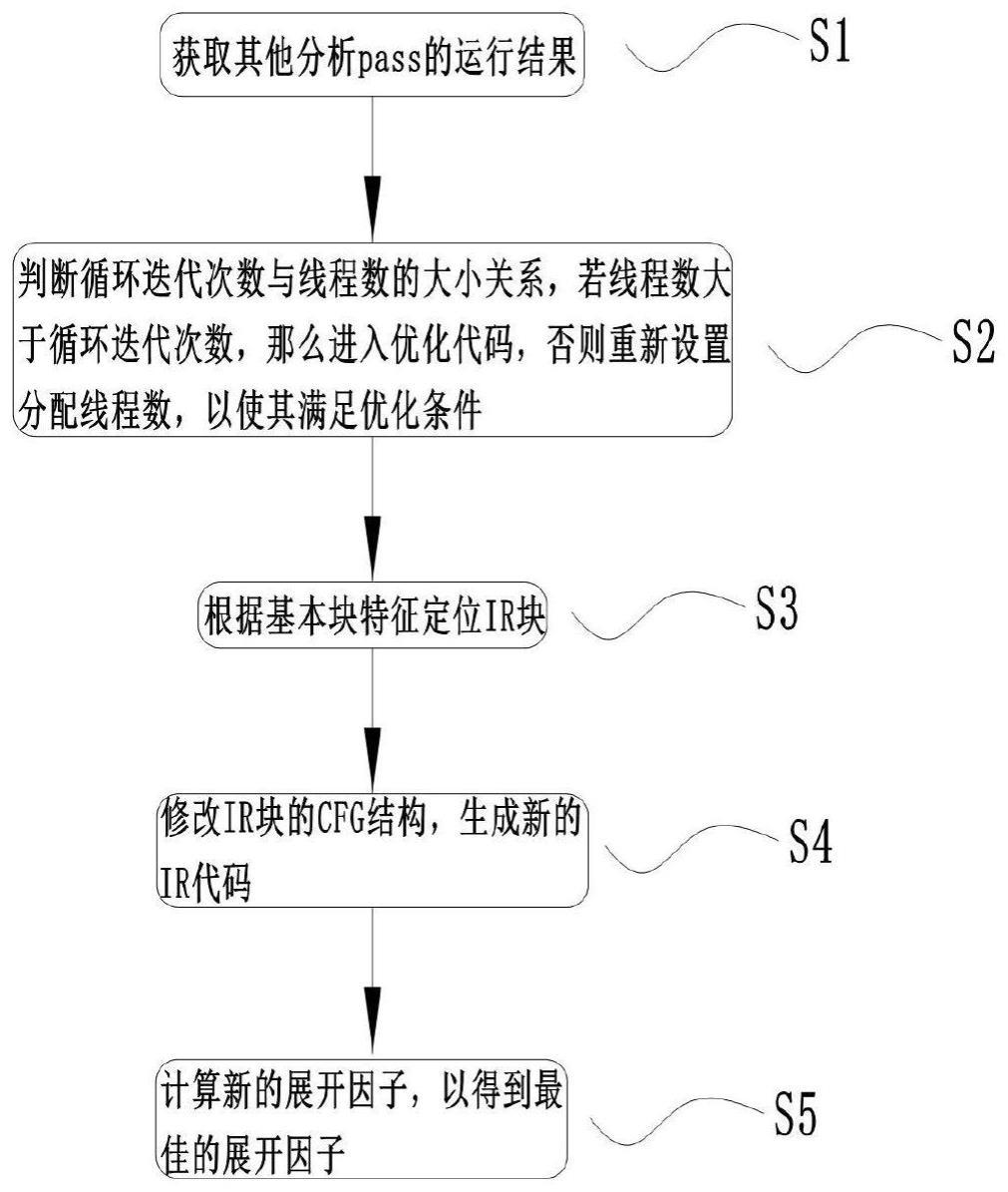
4、s1:获取其他分析pass的运行结果;
5、s2:判断循环迭代次数与线程数的大小关系,若线程数大于循环迭代次数,那么进入优化代码,否则重新设置分配线程数,以使其满足优化条件;
6、s3:根据基本块特征定位ir块;
7、s4:修改ir块的cfg结构,生成新的ir代码;
8、s5:计算新的展开因子,以得到最佳的展开因子。
9、进一步地,在步骤s1中,所述分析的运行结果包括目标代码的循环迭代次数以及分配线程数在内的相关信息。
10、进一步地,在步骤s3中,控制openmp offload线程迭代的部分具有明显的结构特征,利用该结构特征可以在ir层中准确的定位目标块位置,以对目标块进行优化操作。
11、进一步地,所述结构特征包括基本块名称以及基本块结构。
12、进一步地,在步骤s4中,通过删除新增ir语句,更改线程迭代的控制结构,消除循环控制,减少寄存器数目的使用。
13、进一步地,在步骤s5中,循环展开会使得线程使用更多的寄存器,优化处理减少了寄存器的使用数目,根据最大指令限制数以及可用的寄存器数目,便可得到最佳的展开因子。
14、进一步地,在步骤s5中,具体获取展开因子的步骤包括:
15、a)获取目前可用寄存器的数量;
16、b)计算循环体中的指令条数;
17、c)计算展开因子增加1时寄存器使用数目的增量;
18、d)展开因子初始化为最大指令限制数除以循环体的总指令数;
19、e)在保证展开因子为迭代数的因子情况下,同时考虑新增寄存器数目不超过目前可用的寄存器数量,通过不断的循环判断,从而得到默认最佳的展开因子。
20、本发明所提供的面向dcu的openmp offload寄存器优化方法的有益效果是:
21、与现有llvm对openmp offload过程中线程迭代的统一循环处理不同,本发明作分类处理,使得生成的代码更贴合程序特性,较大程度减少了循环中被占有的空闲寄存器数量,增加了寄存器的重复使用性。同时,与现有llvm中的循环展开的通用情况相比,本发明针对国产dcu后端以及指令集特征进行特殊的适配处理,使得默认计算出的展开因子的优化效果达到最佳性能,提高了程序的运行效率,有效解决了现有技术中寄存器使用数量多,存在溢出风险的技术问题。
技术特征:
1.一种面向dcu的openmpoffload寄存器优化方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的面向dcu的openmpoffload寄存器优化方法,其特征在于:在步骤s1中,所述分析的运行结果包括目标代码的循环迭代次数以及分配线程数在内的相关信息。
3.根据权利要求2所述的面向dcu的openmpoffload寄存器优化方法,其特征在于:在步骤s3中,控制openmpoffload线程迭代的部分具有明显的结构特征,利用该结构特征可以在ir层中准确的定位目标块位置,以对目标块进行优化操作。
4.根据权利要求3所述的面向dcu的openmpoffload寄存器优化方法,其特征在于:所述结构特征包括基本块名称以及基本块结构。
5.根据权利要求3或4所述的面向dcu的openmpoffload寄存器优化方法,其特征在于:在步骤s4中,通过删除新增ir语句,更改线程迭代的控制结构,消除循环控制,减少寄存器数目的使用。
6.根据权利要求5所述的面向dcu的openmpoffload寄存器优化方法,其特征在于:在步骤s5中,循环展开会使得线程使用更多的寄存器,优化处理减少了寄存器的使用数目,根据最大指令限制数以及可用的寄存器数目,便可得到最佳的展开因子。
7.根据权利要求6所述的面向dcu的openmpoffload寄存器优化方法,其特征在于,在步骤s5中,具体获取展开因子的步骤包括:
技术总结
本发明涉及一种面向DCU的OpenMPOffload寄存器优化方法,该方法包括如下步骤:S1:获取其他分析pass的运行结果;S2:判断循环迭代次数与线程数的大小关系,若线程数大于循环迭代次数,那么进入优化代码,否则重新设置分配线程数,以使其满足优化条件;S3:根据基本块特征定位IR块;S4:修改IR块的CFG结构,生成新的IR代码;S5:计算新的展开因子,以得到最佳的展开因子;与现有LLVM对OpenMPoffload过程中线程迭代的统一循环处理不同,本发明作分类处理,使得生成的代码更贴合程序特性,较大程度减少了循环中被占有的空闲寄存器数量,增加了寄存器的重复使用性,解决了现有技术中寄存器使用数量多,存在溢出风险的技术问题。
技术研发人员:高伟,韩林,柴冰,李嘉楠,陈亚浩,李颖颖
受保护的技术使用者:高伟
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!