基于Kmeans的内容均匀聚类方法与流程
本发明涉及计算机,尤其是涉及一种基于kmeans的内容均匀聚类方法。
背景技术:
1、使用传统的聚类算法对文章进行聚类分析,比如预先设定要分4个类,如果内容的特征分布均匀,那么分类如图5所示;但是实际的文章进行聚类,如果分4个类,大部分情况会如图6所示;在极限情况下可能某些类只有个位数的资讯,而有些类有上万篇资讯。
2、故而亟需提出一种基于kmeans的内容均匀聚类方法来解决上述问题。
技术实现思路
1、基于此,有必要针对现有技术的不足,提供一种基于kmeans的内容均匀聚类方法,采用机器学习的方式,可以更加精准的进行相似内容细分,且分类均匀。
2、为解决上述技术问题,本发明采用以下技术方案:
3、本发明提供了基于kmeans的内容均匀聚类方法,其包括如下步骤:
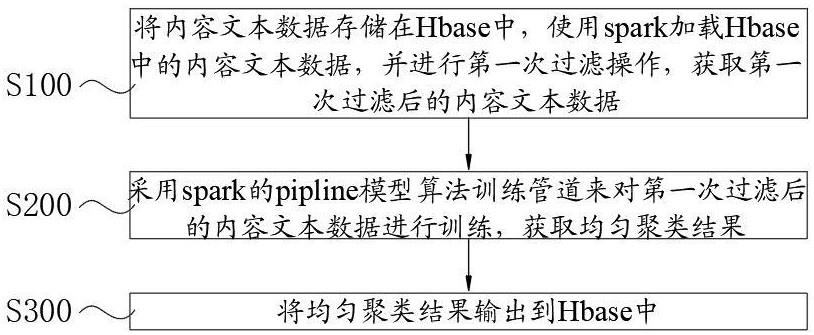
4、步骤s100、将内容文本数据存储在hbase中,使用spark加载hbase中的内容文本数据,并进行第一次过滤操作,获取第一次过滤后的内容文本数据;
5、步骤s200、采用spark的pipline模型算法训练管道来对第一次过滤后的内容文本数据进行训练,获取均匀聚类结果;其中,所述pipline模型算法训练管道由过滤模型、分词模型、词转向量模型及均匀分类模型组合而成;
6、步骤s300、将均匀聚类结果输出到hbase中。
7、综上所述,本发明提供的基于kmeans的内容均匀聚类方法采用spark的pipline模型算法训练管道,配合获取二分聚类算法第n次计算后的均匀聚类结果,有效提高了本发明的聚类精确性,可以更加精准的进行相似内容细分,且分类均匀。
技术特征:
1.一种基于kmeans的内容均匀聚类方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于kmeans的内容均匀聚类方法,其特征在于,步骤s100的方法,具体包括如下步骤:
3.根据权利要求1所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s200的方法,具体包括如下步骤:
4.根据权利要求3所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s250的方法,包括如下步骤,
5.根据权利要求4所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s251中欧几里得计算公式如下:
6.根据权利要求4所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s252的方法,具体操作为:
7.根据权利要求4所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s254的方法,具体操作为:
8.根据权利要求4所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s254的方法,具体操作为:
9.根据权利要求4所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s254之后,还包括
10.根据权利要求1所述的基于kmeans的内容均匀聚类方法,其特征在于,所述步骤s300的方法,具体操作为:
技术总结
本发明公开一种基于Kmeans的内容均匀聚类方法,其包括如下步骤:将内容文本数据存储在Hbase中,使用spark加载Hbase中的内容文本数据,并进行第一次过滤操作,获取第一次过滤后的内容文本数据;采用spark的pipline模型算法训练管道来对第一次过滤后的内容文本数据进行训练,获取均匀聚类结果;将均匀聚类结果输出到Hbase中。本发明采用spark的pipline模型算法训练管道,配合获取二分聚类算法第n次计算后的均匀聚类结果,有效提高了本发明的聚类精确性,可以更加精准的进行相似内容细分,且分类均匀。
技术研发人员:李康琪,舒鑫,王伟,寻桥
受保护的技术使用者:长沙数智融媒科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!