一种基于信息熵的领域单文本分词方法与系统
本申请涉及自然语言处理,具体公开了一种基于信息熵的领域单文本分词方法与系统。
背景技术:
1、中文分词是文本资料开发利用中必不可少的步骤。但中文分词的过程中存在两大技术难点:歧义识别和未登录词识别,为了解决这两大技术难点,分词技术依赖于大规模的人为工作和算力,特别是专业领域文本中包含较多的专业名词,难以实现精确率和人工耗费的平衡。
2、而在无人为工作及大规模训练的条件下,分词只能从文本自身出发,而文本是字符连接和组成的结果,先于语法结构和词语存在。基于统计的方法可以利用语义连接关系,平衡地看待不同字符的识别问题,从而对未登录词有很好的识别效果。
3、已有学者对零样本的分词技术展开了优秀的思考和尝试。例如:张素华等基于中医古籍文本的字符出入度连接特征,提出了connectrank算法,完全实现无监督分词,但准确率仅为67.6%;顾淳等从文本中预处理提取候选词,再结合bert模型、候选词与文本相似度评分提取关键词,改善了中文单文本关键词提取问题,在短文本中表现较好,但准确率仍低于40%。
4、信息熵的理论是香农从热力学中借鉴得到,可以很好地量化字符连接关系。张民引入信息熵开展字词关系研究,通过给定经验阈值筛选词对;任禾基于信息熵理论,通过比较信息熵与人工设定阈值的大小从文本中抽取高频词;取得较好的效果。
5、基于信息熵的统计方法无需复杂的人为耗费,从量化文本字符关系出发,能跳出字典和深度学习取得良好的分词效果,但目前主要使用方式是人为设定阈值,具有随意性和存疑性。
6、并且,在现有的技术资料中,诸多研究从各种角度尝试实现对中文文本的分词,目前看来,准确率的提高还有较多空间,特别是针对领域文本的分词;这些研究在很大程度上减少了人为工作,但仍然不能完全舍弃人为工作,具有人工耗费;人工设定阈值等人为工作具有很大程度的随意性和倾向性,不利于准确地利用和分析字符关系。
7、因此,发明人有鉴于此,提供了一种基于信息熵的领域单文本分词方法与系统,以便解决上述问题。
技术实现思路
1、本发明的目的在于提供一种基于信息熵的领域单文本分词方法与系统,以在零样本、无标签、无训练等无人为工作的条件下,解决专业领域单文本的准确分词问题。
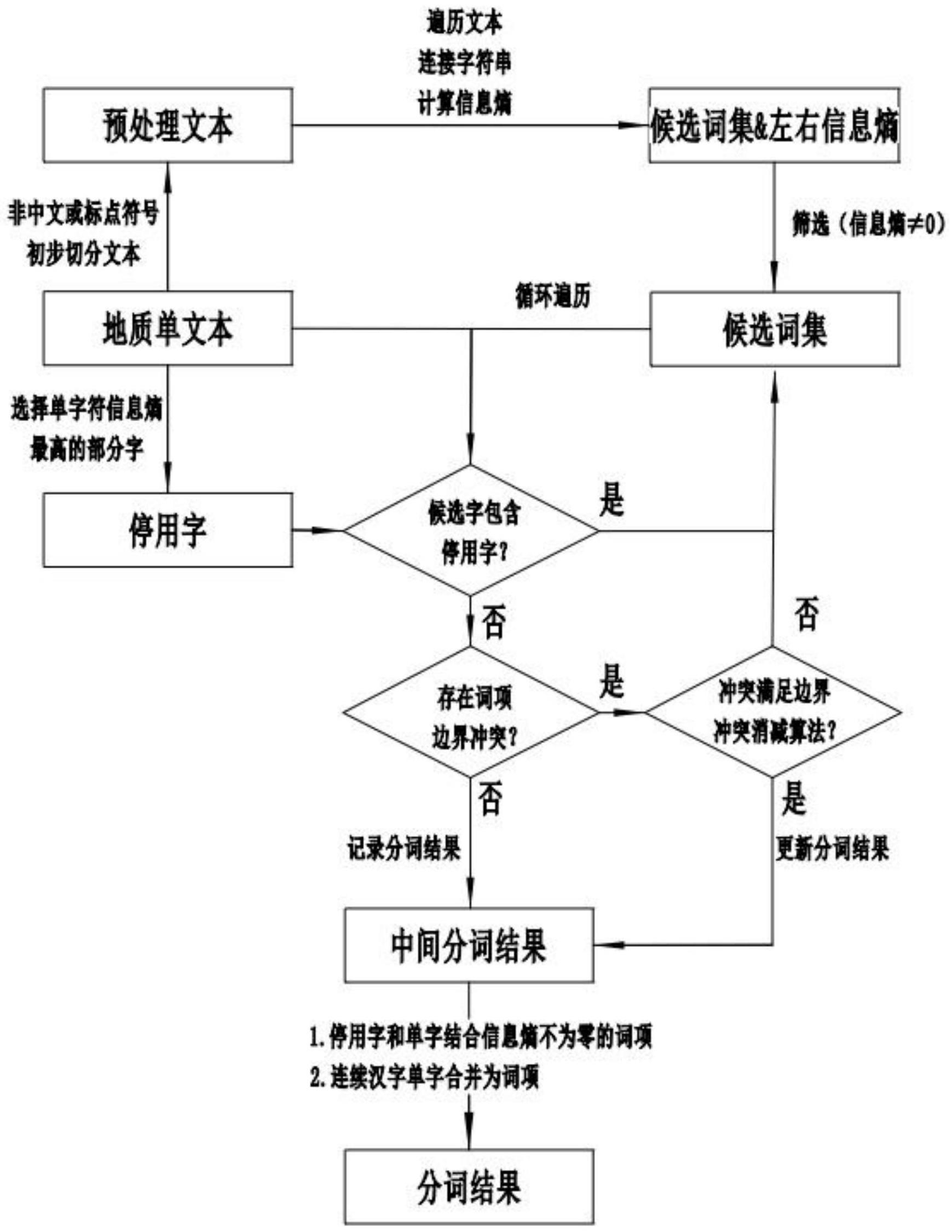
2、为了达到上述目的,本发明的基础方案提供一种基于信息熵的领域单文本分词方法,包括:
3、获取待分词文本;
4、遍历文本,计算单字符信息熵,并选取停用字;
5、遍历文本,枚举所有可能的字符串连接组合形成候选词项,并计算各个候选词项的左右信息熵,以生成并记录候选词集;
6、通过候选词集进行分词:遍历候选词集,记录不包含停用字且与已记录的分词结果无冲突的候选词项为分词结果,当候选词项与已记录的分词结果冲突时,记录并更新更满足边界冲突消减算法的候选词项为分词结果;
7、二次后处理结果:二次遍历消减词项边界冲突后的分词结果,对停用字和单字结合信息熵不为零的词项、连续中文单字组成的词项合并,得到最终分词结果。
8、进一步,采用以下步骤选取停用字:
9、获取文本全部单字符,生成单字符列表;
10、循环遍历单字符列表,依次计算各个单字符的左右信息熵,以形成信息熵列表;
11、将信息熵列表中各个单字符的左右信息熵之和按照降序排列,选取信息熵列表前端部分的单字符作为停用字。
12、进一步,所述停用字为所述信息熵列表中前1%。
13、进一步,采用以下步骤获取候选词集:
14、循环遍历文段,依次获得不重复单字符并计算单字符的左右信息熵;
15、将单字符按照左右信息熵之和降序排列,形成候选单字符列表。
16、进一步,对文段从左到右依次增加一个字符,从而枚举组合所有不定长度的字符串。
17、进一步,通过候选词集进行分词的步骤如下:
18、循环遍历候选词集列表,依次取出候选词项和信息熵,
19、确定所有候选词项在文本中的位置并生成位置列表;
20、判断位置列表中的候选词与文本原始数据是否冲突,当不冲突时记录该候选词为分词结果并记录该候选词的信息熵;当冲突时判断候选词与文本原始数据的冲突类型以及是否满足边界冲突消减算法的修改条件,记录并更新更满足边界冲突消减算法的候选词项为分词结果;
21、二次遍历消减词项边界冲突后的分词结果,对停用字和单字结合信息熵不为零的词项、连续中文单字组成的词项合并,得到最终分词结果;
22、基于统一发明构思,本发明提供一种基于信息熵的领域单文本分词系统,所述领域单文本分词系统用于实现上述的一种基于信息熵的领域单文本分词方法。
23、进一步,所述领域单文本分词系统包括:
24、数据接收模块:用于接收待分词文本信息;
25、信息熵计算模块:用于计算待分词文本中不定长度的字符串的左右信息熵;
26、停用字模块:用于记录待分词文本中的停用字;
27、候选词模块:用于枚举所有可能的字符串连接组合形成候选词项,并计算各个候选词项的左右信息熵,以生成并记录候选词集;
28、分词处理模块:用于遍历候选词集,记录不包含停用字且与已记录的分词结果无冲突的候选词项为分词结果,当候选词项与已记录的分词结果冲突时,记录并更新更满足边界冲突消减算法的候选词项为分词结果;
29、二次后处理模块:二次遍历消减词项边界冲突后的分词结果,对停用字和单字结合信息熵不为零的词项、连续中文单字组成的词项合并,得到最终分词结果;
30、结果输出模块:用于输出分词结果。
31、基于统一发明构思,本发明提供一种电子设备,包括存储器、处理器以及储存在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种基于信息熵的领域单文本分词方法。
32、进一步,所述电子设备内设有上述的一种基于信息熵的领域单文本分词系统,以实现上述的一种基于信息熵的领域单文本分词方法。
33、本方案的原理及效果在于:
34、1.本发明将传统的分词问题转化成确定词项边界问题,从而发现候选词项间的相互冲突,并在冲突区域中,使用基于信息熵的词项间局部比较,代替阈值筛选,从量化文本字符关系出发,基于统计的方法能跳出字典和领域知识的限制,取得良好的分词效果。
35、2.本发明采用候选词项边界冲突消减方法,针对领域单文本的分词效果优秀,准确率更高,能够基于零样本、无标签、无复杂训练的条件,摆脱了分词过程中的人为工作,减少了人工耗费。
36、3.本发明采用词项间的局部动态对比,代替人工设置阈值,具有快捷的优点,既避免了人为的不准确性,又综合考虑了分词过程中的全局和局部特征。
技术特征:
1.一种基于信息熵的领域单文本分词方法,其特征在于,包括:
2.根据权利要求1所述的一种基于信息熵的领域单文本分词方法,其特征在于,采用以下步骤选取停用字:
3.根据权利要求2所述的一种基于信息熵的领域单文本分词方法,其特征在于,所述停用字为所述信息熵列表中前1%。
4.根据权利要求2至3任一所述的一种基于信息熵的领域单文本分词方法,其特征在于,采用以下步骤获取候选词集:
5.根据权利要求4所述的一种基于信息熵的领域单文本分词方法,其特征在于,对文段从左到右依次增加一个字符,从而枚举组合所有不定长度的字符串。
6.根据权利要求4所述的一种基于信息熵的领域单文本分词方法,其特征在于,通过候选词集进行分词的步骤如下:
7.一种基于信息熵的领域单文本分词系统,其特征在于,所述领域单文本分词系统用于实现如权利要求1~6中任一所述的一种基于信息熵的领域单文本分词方法。
8.根据权利要求7所述的一种基于信息熵的领域单文本分词系统,其特征在于,所述领域单文本分词系统包括:
9.一种电子设备,包括存储器、处理器以及储存在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1~6中任一所述的一种基于信息熵的领域单文本分词方法。
10.根据权利要求9所述的一种电子设备,其特征在于,所述电子设备内设有如权利要求7~8任一所述的一种基于信息熵的领域单文本分词系统,以实现如权利要求1~6中任一所述的一种基于信息熵的领域单文本分词方法。
技术总结
本发明涉及自然语言处理技术领域,具体公开了一种基于信息熵的领域单文本分词方法,包括:获取待分词文本;遍历文本,计算单字符信息熵,并选取停用字;遍历文本,枚举所有可能的字符串连接组合形成候选词项,并计算各个候选词项的左右信息熵,以生成并记录候选词集;通过候选词集进行分词:遍历候选词集,记录不包含停用字且与已记录的分词结果无冲突的候选词项为分词结果,当候选词项与已记录的分词结果冲突时,记录并更新更满足边界冲突消减算法的候选词项为分词结果;对分词结果进行二次遍历,若存在停用字与前后某一单字组合信息熵更高且不为零,合并停用字与该单字,得到最终分词结果。本发明针对领域单文本的分词效果优秀,准确率更高。
技术研发人员:邓吉秋,唐宇,郭志勇,邱蓝,吴军,王飞龙
受保护的技术使用者:中南大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!