用于模型训练的错句生成方法、装置、计算机设备及介质与流程
本发明涉及人工智能,尤其涉及一种用于模型训练的错句生成方法、装置、计算机设备及介质。
背景技术:
1、目前,基于神经网络的文本识别模型,通常需要大量的带有标签的文本数据,但此类文本数据的获取成本和标注成本都较高,因此,现有方法通常采用数据增强方法进行文本数据的扩充。
2、但是,不同数据增强方法生成的文本数据的错误类型、错误质量都不相同,如果需要获取错误类型丰富且错误质量较高的文本数据,需要多种数据增强方法并行执行,导致数据增强的处理过程繁琐,且基于多类数据增强方法融合的数据增强策略,难以快速迁移和部署。因此,如何在保证生成错句质量较高的情况下,提高错句生成效率成为亟待解决的问题。
技术实现思路
1、有鉴于此,本发明实施例提供了一种用于模型训练的错句生成方法、装置、计算机设备及介质,以解决在保证生成错句质量较高的情况下,错句生成的效率较低的问题。
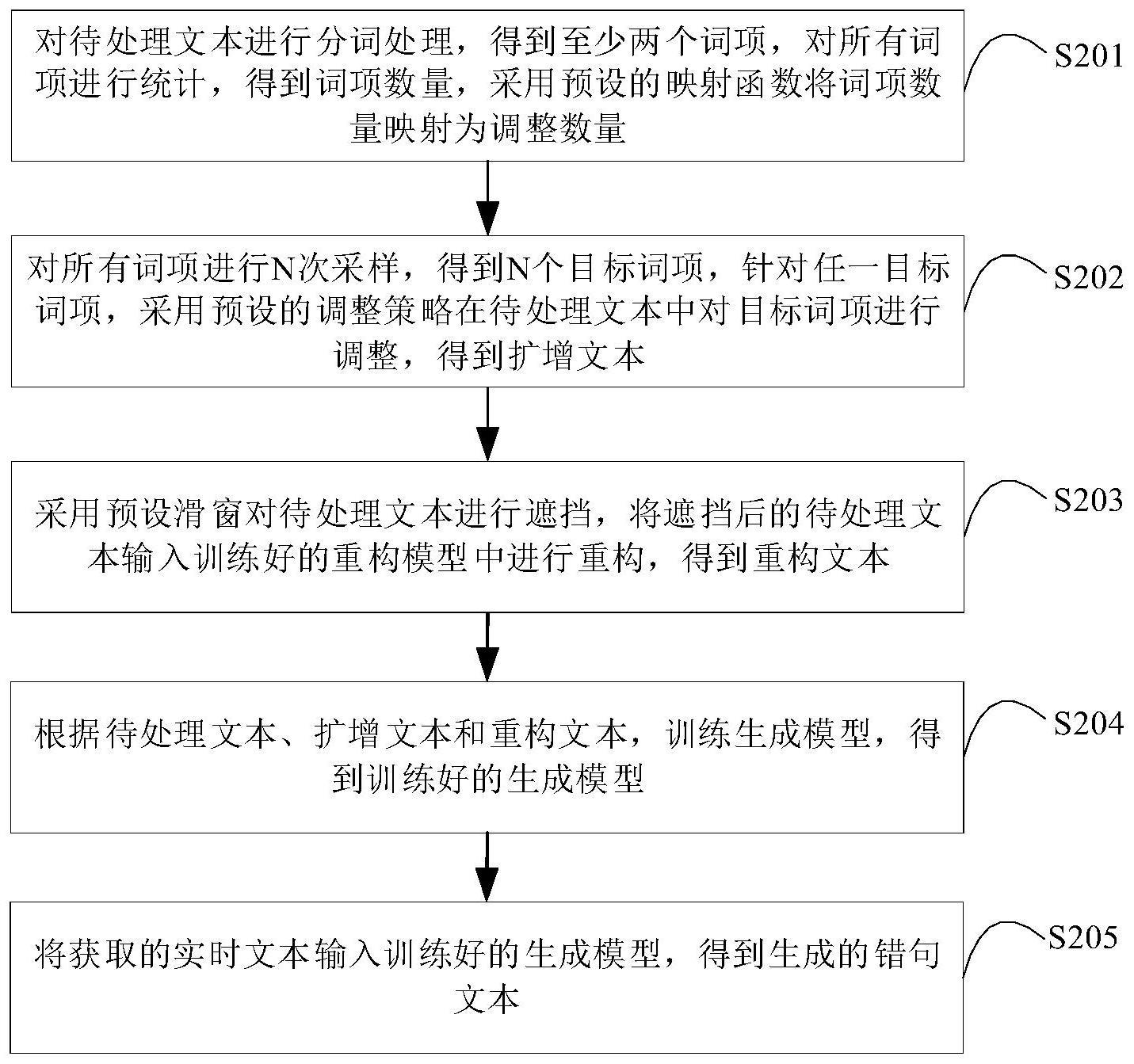
2、第一方面,本发明实施例提供一种用于模型训练的错句生成方法,所述错句生成方法包括:
3、对待处理文本进行分词处理,得到至少两个词项,对所有词项进行统计,得到词项数量,采用预设的映射函数将所述词项数量映射为调整数量;
4、对所有词项进行n次采样,得到n个目标词项,针对任一目标词项,采用预设的调整策略在所述待处理文本中对所述目标词项进行调整,得到扩增文本,n为所述调整数量;
5、采用预设滑窗对所述待处理文本进行遮挡,将遮挡后的待处理文本输入训练好的重构模型中进行重构,得到重构文本;
6、根据所述待处理文本、所述扩增文本和所述重构文本,训练所述生成模型,得到训练好的生成模型;
7、将获取的实时文本输入所述训练好的生成模型,得到生成的错句文本。
8、第二方面,本发明实施例提供一种用于模型训练的错句生成装置,所述错句生成装置包括:
9、文本分词模块,用于对待处理文本进行分词处理,得到至少两个词项,对所有词项进行统计,得到词项数量,采用预设的映射函数将所述词项数量映射为调整数量;
10、文本扩增模块,用于对所有词项进行n次采样,得到n个目标词项,针对任一目标词项,采用预设的调整策略在所述待处理文本中对所述目标词项进行调整,得到扩增文本,n为所述调整数量;
11、文本重构模块,用于采用预设滑窗对所述待处理文本进行遮挡,将遮挡后的待处理文本输入训练好的重构模型中进行重构,得到重构文本;
12、模型训练模块,用于根据所述待处理文本、所述扩增文本和所述重构文本,训练所述生成模型,得到训练好的生成模型;
13、错句生成模块,用于将获取的实时文本输入所述训练好的生成模型,得到生成的错句文本。
14、第三方面,本发明实施例提供一种计算机设备,所述计算机设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的错句生成方法。
15、第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的错句生成方法。
16、本发明实施例与现有技术相比存在的有益效果是:
17、对待处理文本进行分词处理,得到至少两个词项,对所有词项进行统计,得到词项数量,采用预设的映射函数将词项数量映射为调整数量,对所有词项进行n次采样,得到n个目标词项,针对任一目标词项,采用预设的调整策略在待处理文本中对目标词项进行调整,得到扩增文本,采用预设滑窗对待处理文本进行遮挡,将遮挡后的待处理文本输入训练好的重构模型中进行重构,得到重构文本,根据待处理文本、扩增文本和重构文本,训练生成模型,得到训练好的生成模型,将获取的实时文本输入训练好的生成模型,得到生成的错句文本,以多类数据增强方法对待处理文本进行处理,得到包含丰富错误类型的生成模型标签,并基于生成模型标签训练端到端的生成模型,使得可以直接将实时文本输入采用训练好的生成模型,得到生成的错句文本,无需频繁切换数据增强方式,在保证生成错句质量较高的情况下,极大地提高了错句生成效率。
技术特征:
1.一种用于模型训练的错句生成方法,其特征在于,所述错句生成方法包括:
2.根据权利要求1所述的错句生成方法,其特征在于,所述对所有词项进行n次采样,得到n个目标词项包括:
3.根据权利要求1所述的错句生成方法,其特征在于,所述针对任一目标词项,采用预设的调整策略在所述待处理文本中对所述目标词项进行调整,得到扩增文本包括:
4.根据权利要求3所述的错句生成方法,其特征在于,所述调整策略集合包括删除策略、替换策略和插入策略;
5.根据权利要求1所述的错句生成方法,其特征在于,所述采用预设滑窗对所述待处理文本进行遮挡包括:
6.根据权利要求5所述的错句生成方法,其特征在于,所述根据随机游走算法,将所述预设滑窗在所述待处理文本上移动,得到目标滑窗包括:
7.根据权利要求1至6任一项所述的错句生成方法,其特征在于,所述根据所述待处理文本、所述扩增文本和所述重构文本,训练所述生成模型,得到训练好的生成模型包括:
8.一种用于模型训练的错句生成装置,其特征在于,所述错句生成装置包括:
9.一种计算机设备,其特征在于,所述计算机设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述的错句生成方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的错句生成方法。
技术总结
本发明涉及人工智能技术领域,尤其涉及一种用于模型训练的错句生成方法、装置、计算机设备及介质。该方法将待处理文本的词项数量映射为调整数量,从待处理文本中采样得到目标词项,对目标词项进行调整,得到扩增文本,对待处理文本遮挡后,输入重构模型中得到重构文本,根据待处理文本、扩增文本和重构文本,训练生成模型,将实时文本输入训练好的生成模型,得到生成的错句文本,以多类数据增强方法对待处理文本进行处理,得到包含丰富错误类型的文本作为标签,训练端到端的生成模型,使得可以直接将实时文本输入训练好的生成模型,得到生成的错句文本,无需频繁切换数据增强方式,在保证生成错句质量较高的情况下,极大地提高了错句生成效率。
技术研发人员:李志韬,王健宗
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!