基于多模态数据的用户画像构建方法、装置、设备及介质与流程
本发明适用于数据分析,尤其涉及一种基于多模态数据的用户画像构建方法、装置、设备及介质。
背景技术:
1、用户画像是在大数据环境下将用户信息标签化的一种方法,即大数据提供充足的数据基础,通过抽象出标签信息,将用户全貌完整地呈现出来,最终形成一个虚拟用户的全貌。
2、传统的用户画像算法往往依赖于大量的特征工程或者规则,使用单一且低频变化的基本属性数据进行用户画像构建,缺乏整合不同模态数据的能力。然而,金融领域的用户数据具有稀疏、维度高、多源异构且动态变化的特点,且坐席会指导用户上传相关图片进行身份或资质验证,图片中也包含用户相关信息,传统用户画像算法难以充分利用多模态数据自动生成特征,导致难以对用户进行完整地动态刻画,降低了用户画像的构建准确性。
3、因此,在数据处理技术领域,如何提高多模态数据下用户画像的构建准确性成为亟待解决的问题。
技术实现思路
1、有鉴于此,本发明实施例提供了一种基于多模态数据的用户画像构建方法、装置、设备及介质,以解决传统用户画像算法难以充分利用多模态数据,导致用户画像的构建准确性较低的问题。
2、第一方面,本发明实施例提供一种基于多模态数据的用户画像构建方法,所述用户画像构建方法包括:
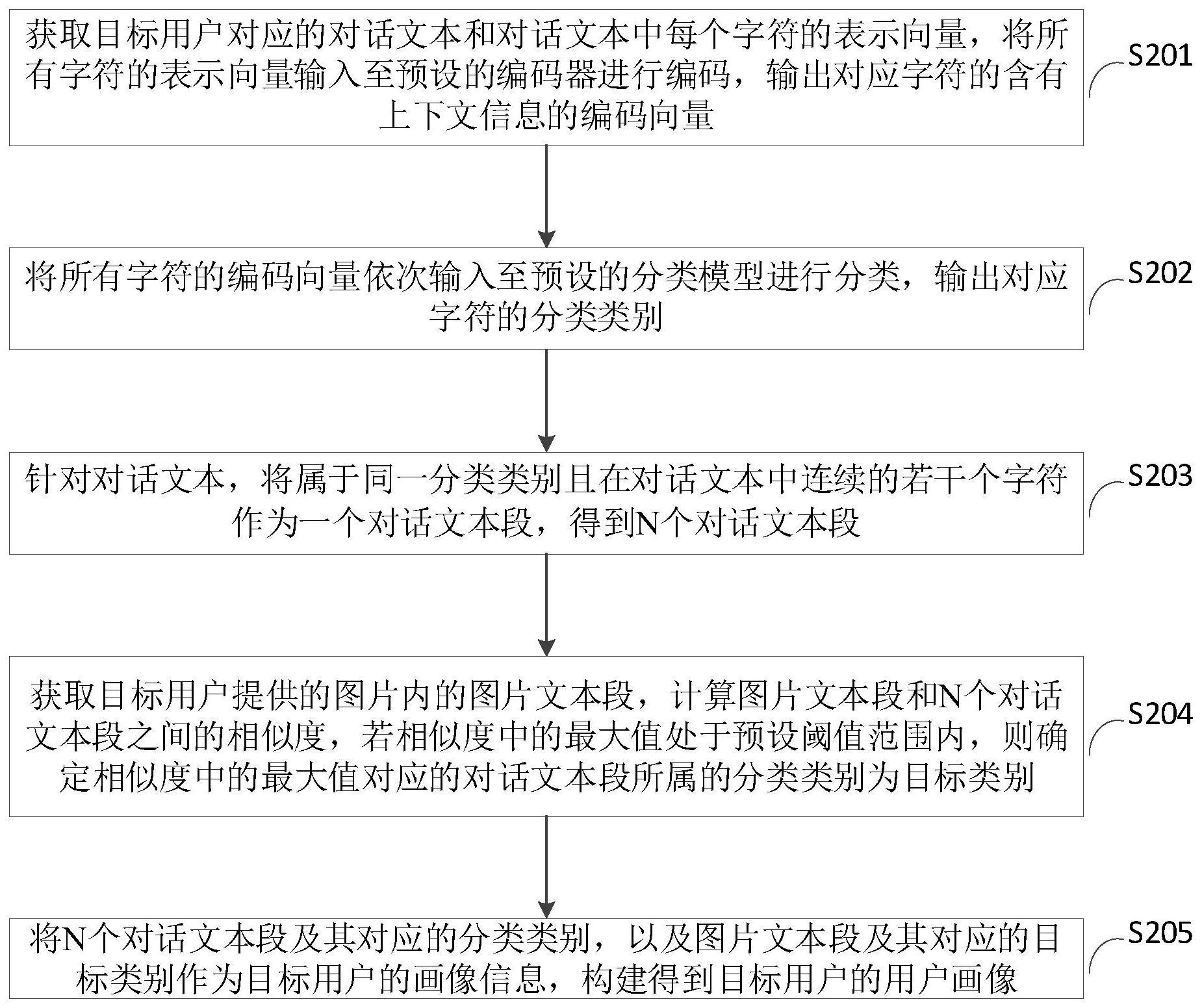
3、获取目标用户对应的对话文本和所述对话文本中每个字符的表示向量,将所有字符的表示向量输入至预设的编码器进行编码,输出对应字符的含有上下文信息的编码向量;
4、将所有字符的编码向量依次输入至预设的分类模型进行分类,输出对应字符的分类类别;
5、针对所述对话文本,将属于同一分类类别且在所述对话文本中连续的若干个字符作为一个对话文本段,得到n个对话文本段,n为大于0的整数;
6、获取所述目标用户提供的图片内的图片文本段,计算所述图片文本段和n个对话文本段之间的相似度,若所述相似度中的最大值处于预设阈值范围内,则确定所述相似度中的最大值对应的对话文本段所属的分类类别为目标类别;
7、将所述n个对话文本段及其对应的分类类别,以及所述图片文本段及其对应的所述目标类别作为所述目标用户的画像信息,构建得到所述目标用户的用户画像。
8、第二方面,本发明实施例提供一种基于多模态数据的用户画像构建装置,所述用户画像构建装置包括:
9、字符编码模块,用于获取目标用户对应的对话文本和所述对话文本中每个字符的表示向量,将所有字符的表示向量输入至预设的编码器进行编码,输出对应字符的含有上下文信息的编码向量;
10、字符分类模块,用于将所有字符的编码向量依次输入至预设的分类模型进行分类,输出对应字符的分类类别;
11、文本分段模块,用于针对所述对话文本,将属于同一分类类别且在所述对话文本中连续的若干个字符作为一个对话文本段,得到n个对话文本段,n为大于0的整数;
12、类别确定模块,用于获取所述目标用户提供的图片内的图片文本段,计算所述图片文本段和n个对话文本段之间的相似度,若所述相似度中的最大值处于预设阈值范围内,则确定所述相似度中的最大值对应的对话文本段所属的分类类别为目标类别;
13、画像构建模块,用于将所述n个对话文本段及其对应的分类类别,以及所述图片文本段及其对应的所述目标类别作为所述目标用户的画像信息,构建得到所述目标用户的用户画像。
14、第三方面,本发明实施例提供一种计算机设备,所述计算机设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的用户画像构建方法。
15、第四方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的用户画像构建方法。
16、本发明实施例与现有技术相比存在的有益效果是:通过获取目标用户对应的对话文本和对话文本中每个字符的表示向量,将所有字符的表示向量输入至预设的编码器进行编码,输出对应字符的含有上下文信息的编码向量,将所有字符的编码向量依次输入至预设的分类模型进行分类,输出对应字符的分类类别,将属于同一分类类别且在对话文本中连续的若干个字符作为一个对话文本段,得到n个对话文本段,获取目标用户提供的图片内的图片文本段,计算图片文本段和n个对话文本段之间的相似度,若相似度中的最大值处于预设阈值范围内,则确定相似度中的最大值对应的对话文本段所属的分类类别为目标类别,将n个对话文本段及其对应的分类类别,以及图片文本段及其对应的目标类别作为目标用户的画像信息,构建得到目标用户的用户画像,通过提取对话文本中对应的用户画像文本信息和用户画像类别信息,并根据对话文本中的用户画像信息对目标用户提供的图片进行信息衡量,得到对应的图片文本段及其目标类别来补充用户画像信息,以融合对话文本和图片对用户画像进行了完整地动态刻画,提高了用户画像的构建准确性。
技术特征:
1.一种基于多模态数据的用户画像构建方法,其特征在于,所述用户画像构建方法包括:
2.根据权利要求1所述的用户画像构建方法,其特征在于,所述获取目标用户对应的对话文本和所述对话文本中每个字符的表示向量包括:
3.根据权利要求1所述的用户画像构建方法,其特征在于,所述预设的分类模型包括预设的双向长短时记忆模型;
4.根据权利要求1所述的用户画像构建方法,其特征在于,所述获取所述目标用户提供的图片内的图片文本段包括:
5.根据权利要求1所述的用户画像构建方法,其特征在于,所述计算所述图片文本段和n个对话文本段之间的相似度包括:
6.根据权利要求1所述的画像构建方法,其特征在于,所述将所述n个对话文本段及其对应的分类类别,以及所述图片文本段及其对应的所述目标类别作为所述目标用户的画像信息,构建得到所述目标用户的用户画像包括:
7.一种基于多模态数据的用户画像构建装置,其特征在于,所述用户画像构建装置包括:
8.根据权利要求7所述的用户画像构建装置,其特征在于,所述画像构建模块包括:
9.一种计算机设备,其特征在于,所述计算机设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至6任一项所述的用户画像构建方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6任一项所述的用户画像构建方法。
技术总结
本发明适用于数据处理技术领域,尤其涉及一种基于多模态数据的用户画像构建方法、装置、设备及介质。本发明根据编码器和分类模型输出对话文本中每个字符的分类类别,将属于同一分类类别且在对话文本中连续的若干个字符作为一个对话文本段,得到N个对话文本段,并在获取的图片文本段和N个对话文本段之间的相似度中的最大值处于预设阈值范围内时,确定图片文本段及其目标类别,结合N个对话文本段及其对应的分类类别构建得到用户画像,通过提取到的对话文本中的用户画像信息对图片文本段进行用衡量,得到图片文本段及其目标类别来补充用户画像信息,以融合对话文本和图片数据对用户画像进行完整地刻画,提高了用户画像构建结果的准确性。
技术研发人员:欧阳燕绚,易艳,王建明,肖京
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!