一种深度学习模型推理部署的方法和系统与流程
本发明涉及的是计算机,特别涉及一种深度学习模型推理部署的方法和系统。
背景技术:
1、近年来,以深度学习为核心的人工智能技术迅速发展,在计算机视觉、语音识别、自然语言处理等领域取得了显著的应用成果。
2、随着深度学习训练框架和人工智能芯片等软硬件技术的发展和应用,人工智能向“云、边、端”的方向迅速发展并逐渐形成一个繁荣的应用生态。目前,在算法开发和训练阶段,开发人员通常会选择tensorflow、pytorch、paddpaddle、mxnet等成熟的深度学习框架来训练和构建深度学习模型,在算法部署与生产应用环节,开发人员更倾向于选择面向硬件优化加速的轻量级推理引擎,如tensorrt、openvino、coreml、tengine等,由于各框架的独立性和多样性,模型在不同框架间的重构转换和落地应用给开发人员带来了较大的困难和挑战,因此需要一种通用的、便捷的、低成本的工具和方法来简化深度学习模型的推理部署。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的一种深度学习模型推理部署的方法和系统。
2、为了解决上述技术问题,本申请实施例公开了如下技术方案:
3、一种深度学习模型推理部署的方法,包括:
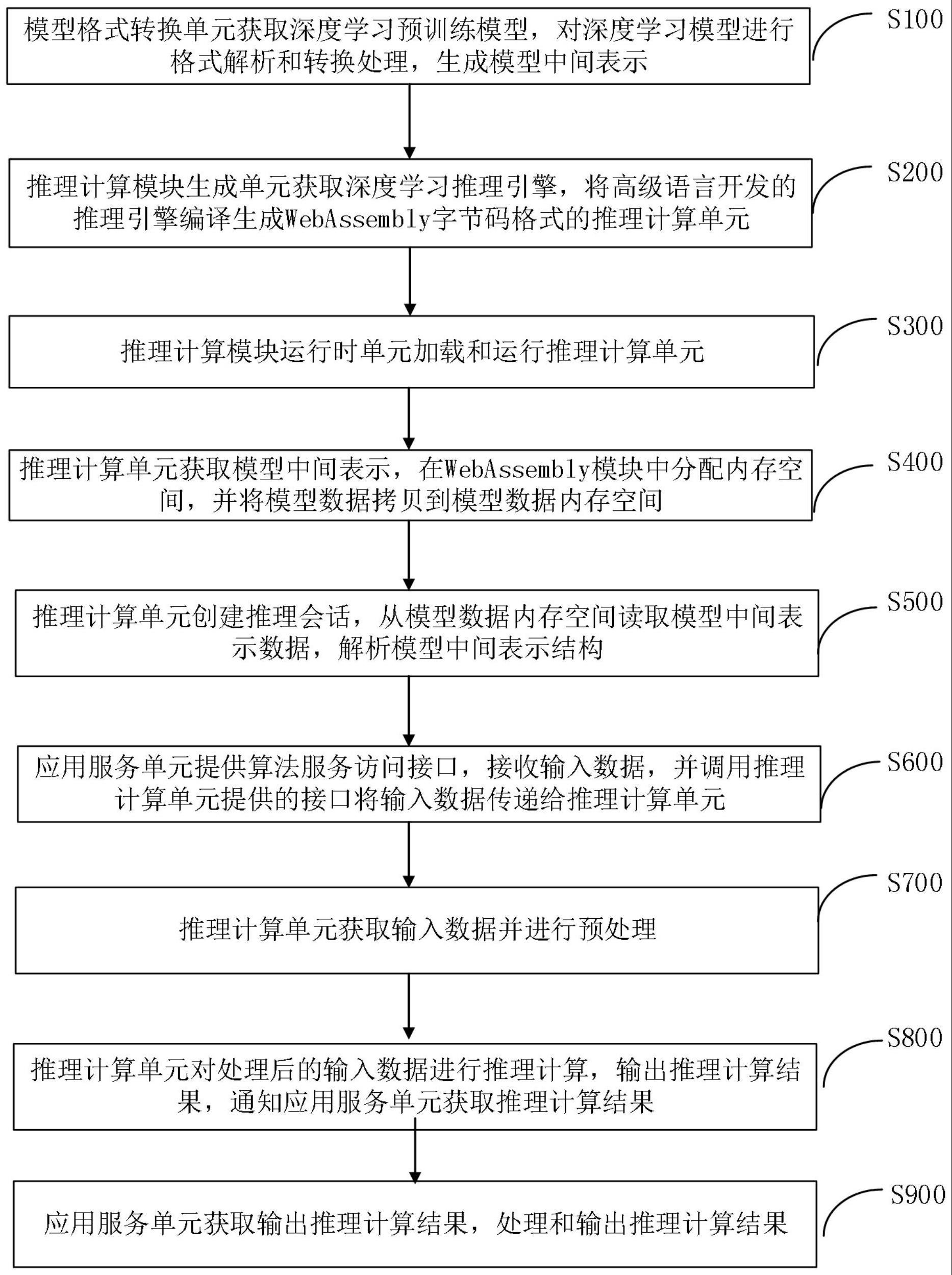
4、s100.模型格式转换单元获取深度学习预训练模型,对深度学习模型进行格式解析和转换处理,生成模型中间表示;
5、s200.推理计算模块生成单元获取深度学习推理引擎,将高级语言开发的推理引擎编译生成webassembly字节码格式的推理计算单元;
6、s300.推理计算模块运行时单元加载和运行推理计算单元;
7、s400.推理计算单元获取模型中间表示,在webassembly模块中分配内存空间,并将模型数据拷贝到模型数据内存空间;
8、s500.推理计算单元创建推理会话,从模型数据内存空间读取模型中间表示数据,解析模型中间表示结构;
9、s600.应用服务单元提供算法服务访问接口,接收输入数据,并调用推理计算单元提供的接口将输入数据传递给推理计算单元;
10、s700.推理计算单元获取输入数据并进行预处理;
11、s800.推理计算单元对处理后的输入数据进行推理计算,输出推理计算结果,通知应用服务单元获取推理计算结果;
12、s900.应用服务单元获取输出推理计算结果,处理和输出推理计算结果。
13、进一步地,s100中,生成模型中间表示是onnx格式。
14、进一步地,s100中,采用两种模型格式转换方式进行转换,具体为:基于docker容器安装部署fastdeploy工具,基于fastdeploy工具的格式转换命令进行模型格式转换;或/和基于docker容器安装部署深度学习框架,采用深度学习框架转换工具或各深度学习框架内置的模型导出接口,将模型格式转换为onnx格式。
15、进一步地,s200中,推理计算模块生成单元采用docker容器进行部署管理,包括编写dockerfile文件,dockerfile文件包含emscripten编译环境安装步骤,dockerfile文件也包含获取推理引擎源码及拷贝解压步骤,使用dockerfile文件和dockerbuild命令构建生成docker镜像,使用docker镜像和dockerrun命令构建docker镜像的运行实例,运行docker容器时默认启动emscripten编译环境,基于emscripten工具链对高级语言开发的推理引擎代码进行编译,生成webassembly模块;推理计算模块生成单元构建完成后,使用dockerpush命令将docker镜像存放到docker镜像仓库中。
16、进一步地,s300中,推理计算模块运行时单元使用webassembly运行时来加载和运行webassembly字节码格式的推理计算单元;具体的,web端推理计算模块运行时单元,采用chrome、firefox、edge、safari浏览器内核作为webassembly运行时环境。
17、进一步地,s400中,应用服务单元获取到onnx格式的模型文件后,需要将onnx格式的模型文件传递到推理计算单元的内存空间;具体方法包括:应用服务单元调用推理计算单元的api接口分配内存空间,所述内存空间包括模型数据内存空间、输入数据内存空间和输出数据内存空间,并将onnx格式的模型文件的二进制数据拷贝到推理计算单元的模型数据内存空间中,具体的,应用服务单元基于module.heap对象来访问推理计算单元的内存空间。
18、进一步地,s500中,推理计算单元工作方法包括:推理计算单元调用onnxruntime的api接口创建inferencesession推理会话对象,调用inferencesession对象的加载模型接口从模型数据内存空间加载onnx模型并进行解析。
19、进一步地,s600中,输入数据是一张包含文字信息的待识别图片文件,应用服务单元将输入图片数据由base64编码转换为二进制数据格式,调用推理计算单元提供的接口,将图片数据拷贝到推理计算单元的输入数据内存空间中。
20、进一步地,s900中,应用服务单元访问推理计算单元的输出数据内存空间的数据指针,并将输出结果数据拷贝到应用服务单元的内存空间;推理任务完成后,应用服务单元通知推理计算单元清空和释放输入数据内存空间和输出数据内存空间。
21、本发明还公开了一种深度学习模型推理部署的系统,包括:模型格式转换单元、推理计算单元、推理计算模块生成单元、推理计算模块运行时单元、应用服务单元;其中:
22、模型格式转换单元,用于将深度学习框架生成的预训练模型转换成模型中间表示;
23、推理计算单元,用于对输入数据进行预处理和推理计算,输出推理计算结果;
24、推理计算模块生成单元,用于将高级语言开发的推理引擎生成webassembly字节码格式的推理计算单元;
25、推理计算模块运行时单元,用于为运行推理计算模块提供运行时环境;
26、应用服务单元,提供算法服务访问接口,同时提供模型下载、消息通信、业务处理功能。
27、本发明实施例提供的上述技术方案的有益效果至少包括:
28、本发明公开了一种深度学习模型推理部署的方法和系统,通过将主流深度学习框架训练的模型转换成通用的模型中间表示格式,同时将推理引擎转换成webassembly模块,可以在不同的推理计算运行时环境(如浏览器)中执行推理过程,具有开放通用、安全便捷、灵活扩展、低成本等优点。
29、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
技术特征:
1.一种深度学习模型推理部署的方法,其特征在于,包括:
2.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s100中,生成模型中间表示是onnx格式。
3.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s100中,采用两种模型格式转换方式进行转换,具体为:基于docker容器安装部署fastdeploy工具,基于fastdeploy工具的格式转换命令进行模型格式转换;或/和基于docker容器安装部署深度学习框架,采用深度学习框架转换工具或各深度学习框架内置的模型导出接口,将模型格式转换为onnx格式。
4.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s200中,推理计算模块生成单元采用docker容器进行部署管理,包括编写dockerfile文件,dockerfile文件包含emscripten编译环境安装步骤,dockerfile文件也包含获取推理引擎源码及拷贝解压步骤,使用dockerfile文件和dockerbuild命令构建生成docker镜像,使用docker镜像和dockerrun命令构建docker镜像的运行实例,运行docker容器时默认启动emscripten编译环境,基于emscripten工具链对高级语言开发的推理引擎代码进行编译,生成webassembly模块;推理计算模块生成单元构建完成后,使用dockerpush命令将docker镜像存放到docker镜像仓库中。
5.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s300中,推理计算模块运行时单元使用webassembly运行时来加载和运行webassembly字节码格式的推理计算单元;具体的,web端推理计算模块运行时单元,采用chrome、firefox、edge、safari浏览器内核作为webassembly运行时环境。
6.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s400中,应用服务单元获取到onnx格式的模型文件后,需要将onnx格式的模型文件传递到推理计算单元的内存空间;具体方法包括:应用服务单元调用推理计算单元的api接口分配内存空间,所述内存空间包括模型数据内存空间、输入数据内存空间和输出数据内存空间,并将onnx格式的模型文件的二进制数据拷贝到推理计算单元的模型数据内存空间中,具体的,应用服务单元基于module.heap对象来访问推理计算单元的内存空间。
7.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s500中,推理计算单元工作方法包括:推理计算单元调用onnx runtime的api接口创建inferencesession推理会话对象,调用inferencesession对象的加载模型接口从模型数据内存空间加载onnx模型并进行解析。
8.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s600中,输入数据是一张包含文字信息的待识别图片文件,应用服务单元将输入图片数据由base64编码转换为二进制数据格式,调用推理计算单元提供的接口,将图片数据拷贝到推理计算单元的输入数据内存空间中。
9.如权利要求1所述的一种深度学习模型推理部署的方法,其特征在于,s900中,应用服务单元访问推理计算单元的输出数据内存空间的数据指针,并将输出结果数据拷贝到应用服务单元的内存空间;推理任务完成后,应用服务单元通知推理计算单元清空和释放输入数据内存空间和输出数据内存空间。
10.一种深度学习模型推理部署的系统,其特征在于,包括:模型格式转换单元、推理计算单元、推理计算模块生成单元、推理计算模块运行时单元、应用服务单元;其中:
技术总结
本实施例公开了一种深度学习模型推理部署的方法和系统,所述方法和系统通过将主流深度学习框架训练的模型转换成通用的模型中间表示格式,同时将推理引擎转换成WebAssembly模块,可以在不同的推理计算运行时环境中执行推理过程,具有开放通用、安全便捷、灵活扩展、低成本等优点。
技术研发人员:刘树惠,陈璐
受保护的技术使用者:武汉众智数字技术有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!