一种基于注意力的多项选择机器阅读理解方法
本发明属于自然语言处理领域,具体涉及一种基于注意力的多项选择机器阅读理解方法。
背景技术:
1、机器阅读理解是自然语言处理领域重要的研究方向之一。近年随着各种深度学习技术的融合,它越来越受到关注。多项选择机器阅读理解是其中的任务之一,其任务旨在帮助人类从海量文本中快速聚焦问题相关信息,做出最优选择,在人工信息获取方面节约成本,增加信息检索的有效性。
2、目前主流的机器阅读理解技术是基于大规模预训练模型的方法bert、robert等。因为利用了大规模预训练模型提供了更好的模型初始化参数,使用了更多更丰富的数据集作为支撑,使得在目标任务上有更好的准确度。然而,堆叠更多的数据会加重模型的负载,使模型被无用信息所干扰,模型的泛化能力变差,降低模型的收敛速度。综上所述,传统的模型和数据结合不能满足目前应用场景的需求。
技术实现思路
1、为解决以上现有技术存在的问题,本发明提出了一种基于注意力的多项选择机器阅读理解方法,该方法包括:
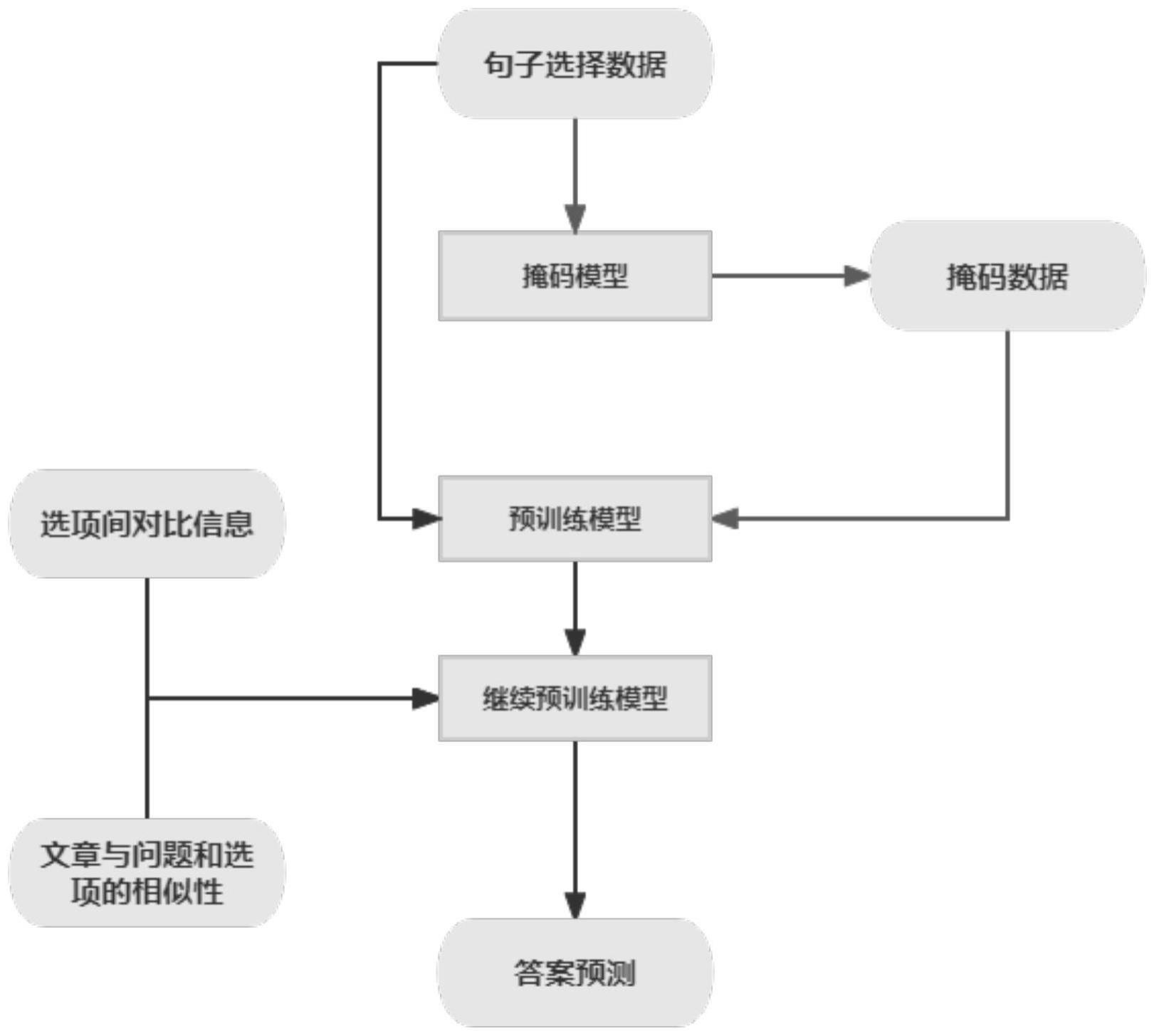
2、s1:获取阅读理解数据,将阅读理解数据划分为多项选择数据集和句子选择数据集;
3、s2:将句子选择数据集中的文章问题和选项进行二次掩码操作,将掩码后的数据输入到bert-wwm-ext预训练模型中进行增量训练,得到预训练模型d;
4、s3:在预训练模型d中加入多头注意力机制,计算每个选项之间相互注意力权重aij,得到选项的注意力输出向量attention(aij);
5、s4:通过门控通道注意力机制将注意力输出向量融入原始的选项表示中,得到候选选项集合options;
6、s5:将选项与文章、问题与文章中的每个句子进行相似度匹配,保留文章与选项相关性最高的k个句子,将k个句子组合成文章p’;
7、s6:根据候选选项集合options、文章p’以及问题构建全连接信息,通过构建的全连接线性层去预测问题最后的答案。
8、优选的,对bert-wwm-ext预训练模型中进行增量训练的过程包括:句子选择数据输入bert-wwm-ext模型进行一轮继续预训练,得到预训练模型m;随机选取选项中的词语,使用[mask]掩码遮盖,并将正确答案句子填入文章,将mask的词语作为选项,得到新的文本数据;重复上述过程,将所有的新数据文本输入到入模型m得到当前预训练模型d。
9、进一步的,对bert-wwm-ext模型进行迭代训练的过程包括:给定一个段落p和n个选项a1,a2...an,用词汇表[unusednum]中的特殊标签替换p中的空格,其中num范围从0到空格数减去1;对于答案选项中的每个ai,将ai和带有标签[sep]的p连接起来作为输入序列;将长度为l的输入序列输入到bert中,并通过权重移动平均优化方法对模型的学习率进行衰减,得到一个隐藏的表示将h和可训练参数进行点积得到当前选项出现空白的概率t通过softmax进行对数计算,并选择概率最大的选项作为该空间的预测。
10、进一步的,采用权重移动平均优化方法对模型的学习率进行衰减包括:对于n个权重数据[θ1,θ2,...θn],权重平均值公式为:
11、vt=β·vt-1+(1-β)·θt
12、其中,vt表示第t个影子权重,β为超参数,vt-1表示第t-1个影子权重,θt表示第t个权重数据。
13、优选的,计算每个选项之间相互注意力权重aij的公式为:
14、
15、
16、m=1,2,3...head
17、其中,aij代表第i个选项向量oi与第j个对比选项向量pj的注意力权重,attention(aij)m表示由选项向量和对比选项向量计算得出的注意力输出向量,softmax()表示softmax函数,w1、w2、w3都是可训练权重矩阵。
18、优选的,通过门控通道注意力机制将注意力输出向量融入原始的选项表示包括:
19、
20、
21、
22、
23、本发明的有益效果:
24、本发明通过使用句子选择数据对预训练模型bert-wwm-ext进行继续预训练,使得模型可以更加适应横向领域,同时多头注意力机制的引入可以充分利用文章、问题和选项之间的信息,再通过权重移动平均优化模型参数,使模型更加准确的回答阅读理解的问题。
技术特征:
1.一种基于注意力的多项选择机器阅读理解方法,其特征在于,包括:
2.根据权利要求1所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,对bert-wwm-ext预训练模型中进行增量训练的过程包括:句子选择数据输入bert-wwm-ext模型进行一轮继续预训练,得到预训练模型m;随机选取选项中的词语,使用[mask]掩码遮盖,并将正确答案句子填入文章,将mask的词语作为选项,得到新的文本数据;重复上述过程,将所有的新数据文本输入到入模型m得到当前预训练模型d。
3.根据权利要求2所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,对bert-wwm-ext模型进行迭代训练的过程包括:给定一个段落p和n个选项a1,a2...an,用词汇表[unusednum]中的特殊标签替换p中的空格,其中num范围从0到空格数减去1;对于答案选项中的每个ai,将ai和带有标签[sep]的p连接起来作为输入序列;将长度为l的输入序列输入到bert中,并通过权重移动平均优化方法对模型的学习率进行衰减,得到一个隐藏的表示将h和可训练参数进行点积得到当前选项出现空白的概率t通过softmax进行对数计算,并选择概率最大的选项作为该空间的预测。
4.根据权利要求3所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,采用权重移动平均优化方法对模型的学习率进行衰减包括:对于n个权重数据[θ1,θ2,...θn],权重平均值公式为:
5.根据权利要求1所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,计算每个选项之间相互注意力权重aij的公式为:
6.根据权利要求1所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,通过门控通道注意力机制将注意力输出向量融入原始的选项表示包括:
7.根据权利要求1所述的一种基于注意力的多项选择机器阅读理解方法,其特征在于,对选项与文章中的每个句子进行相似度匹配检测,对问题与文章中的每个句子进行相似度匹配检测包括:计算句子中单词向量的加权平均值,去除平均向量在主成分上的公共值;给定句子s,计算句子中每个单词w的加权平均值;获取句子s中的语义信息;根据加权平均值对语义信息进行筛选,删除与语义信息想法方向上的分量,得到关键信息;将所有的关键信息进行相似度比较,得到k个句子;其中计算加权平均值时,每个单词的权重表示为其中a为超参数,p(w)为单词w在语料库中出现的频率,语料库为随机数据组成的数据库。
技术总结
本发明属于自然语言处理领域,具体涉及一种基于注意力的多项选择机器阅读理解方法,包括:采用句子选择数据集S对中文预训练模型BERT‑wwm‑ext进行增量训练,得到继续预训练模型D;引入多头注意力机制融合选项信息,问题与文章信息,增强模型回答的正确率;采用权重移动平均的方式对模型参数进行调优;本发明通过对预训练模型BERT‑wwm‑ext进行继续预训练,使得模型更加适应横向领域,同时多头注意力机制的引入可以充分利用文章、问题和选项之间的信息,再通过权重移动平均优化模型参数,使模型更加准确的回答阅读理解的问题。
技术研发人员:孙开伟,段雨辰,纪志阳,李奕佳,曾雅苑
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!