图像识别模型的训练方法及装置、图像识别方法及装置与流程
本说明书实施例涉及人工智能,特别涉及一种图像识别模型的训练方法。
背景技术:
1、随着计算机技术的不断发展,图像识别技术越来越重要,而文本识别技术作为图像识别技术的一个分支,应用范围越来越广。文本识别技术是一种对文本图像进行图像识别,以识别出文本图像中的文本的技术。例如,识别试卷中的答题内容、识别合同中的变更内容等应用。但是目前的图像识别仅仅实现图像到文本的转化,使得识别精度不高。因此,亟需一种识别精度高、识别速度快的图像识别方法。
技术实现思路
1、有鉴于此,本说明书实施例提供了一种图像识别模型训练方法、图像识别方法。本说明书一个或者多个实施例同时涉及一种图像识别模型训练装置、图像识别装置,一种计算设备,一种计算机可读存储介质以及一种计算机程序,以解决现有技术中存在的技术缺陷。
2、根据本说明书实施例的第一方面,提供了一种图像识别模型训练方法,包括:
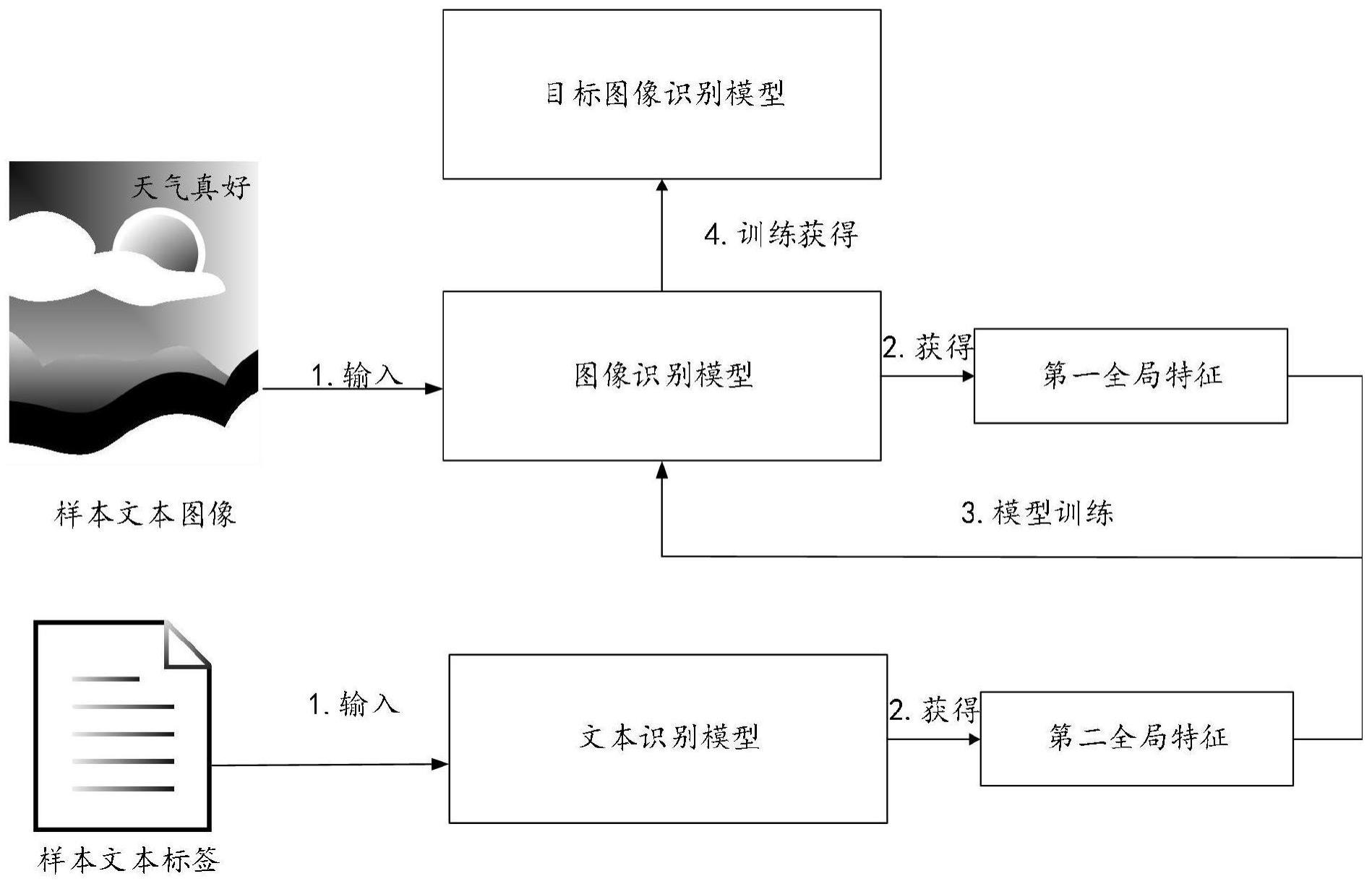
3、获取样本文本图像和所述样本文本图像的样本文本标签;
4、通过图像识别模型确定所述样本文本图像对应视觉维度的第一全局特征,以及通过文本识别模型确定所述样本文本标签对应语言维度的第二全局特征;
5、根据所述第一全局特征和所述第二全局特征对所述图像识别模型进行迭代训练,直至获得满足模型训练结束条件的目标图像识别模型;
6、其中,所述目标图像识别模型的识别结果融合所述视觉维度和所述语言维度分别对应的语义特征。
7、根据本说明书实施例的第二方面,提供了一种图像识别方法,包括:
8、获取待识别图像,并将所述待识别图像输入至通过所述图像识别模型训练方法训练获得的目标图像识别模型;
9、获得所述目标图像识别模型输出的所述待识别图像的识别结果,其中,所述目标图像识别模型的识别结果融合视觉维度和语言维度分别对应的语义特征。
10、根据本说明书实施例的第三方面,提供了一种图像识别方法,包括:
11、接收目标用户针对目标项目上传的理赔材料图像;
12、将所述理赔材料图像输入至通过所述图像识别模型训练方法训练获得的目标图像识别模型;
13、获得所述目标图像识别模型输出的所述理赔材料图像的理赔文本信息,其中,所述理赔文本信息融合视觉维度和语言维度分别对应的语义特征;
14、根据所述理赔文本信息确定理赔结果并反馈至所述目标用户。
15、根据本说明书实施例的第四方面,提供了一种图像识别模型训练装置,包括:
16、获取模块,被配置为获取样本文本图像和所述样本文本图像的样本文本标签;
17、确定模块,被配置为通过图像识别模型确定所述样本文本图像对应视觉维度的第一全局特征,以及通过文本识别模型确定所述样本文本标签对应语言维度的第二全局特征;
18、训练模块,被配置为根据所述第一全局特征和所述第二全局特征对所述图像识别模型进行迭代训练,直至获得满足模型训练结束条件的目标图像识别模型;
19、其中,所述目标图像识别模型的识别结果融合所述视觉维度和所述语言维度分别对应的语义特征。
20、根据本说明书实施例的第五方面,提供了一种图像识别装置,包括:
21、输入模块,被配置为获取待识别图像,并将所述待识别图像输入至通过所述图像识别模型训练方法训练获得的目标图像识别模型;
22、输出模块,被配置为获得所述目标图像识别模型输出的所述待识别图像的识别结果,其中,所述目标图像识别模型的识别结果融合视觉维度和语言维度分别对应的语义特征。
23、根据本说明书实施例的第六方面,提供了一种图像识别装置,包括:
24、接收模块,被配置为接收目标用户针对目标项目上传的理赔材料图像;
25、输入模块,被配置为将所述理赔材料图像输入至通过所述图像识别模型训练方法训练获得的目标图像识别模型;
26、获得模块,被配置为获得所述目标图像识别模型输出的所述理赔材料图像的理赔文本信息,其中,所述理赔文本信息融合视觉维度和语言维度分别对应的语义特征;
27、反馈模块,被配置为根据所述理赔文本信息确定理赔结果并反馈至所述目标用户。
28、根据本说明书实施例的第七方面,提供了一种计算设备,包括:
29、存储器和处理器;
30、所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,该计算机可执行指令被处理器执行时实现上述图像识别模型训练方法、图像识别方法的步骤。
31、根据本说明书实施例的第八方面,提供了一种计算机可读存储介质,其存储有计算机可执行指令,该指令被处理器执行时实现上述图像识别模型训练方法、图像识别方法的步骤。
32、根据本说明书实施例的第九方面,提供了一种计算机程序,其中,当所述计算机程序在计算机中执行时,令计算机执行上述图像识别模型训练方法、图像识别方法的步骤。
33、本说明书提供了一种图像识别模型训练方法,包括:获取样本文本图像和所述样本文本图像的样本文本标签;通过图像识别模型确定所述样本文本图像对应视觉维度的第一全局特征,以及通过文本识别模型确定所述样本文本标签对应语言维度的第二全局特征;根据所述第一全局特征和所述第二全局特征对所述图像识别模型进行迭代训练,直至获得满足模型训练结束条件的目标图像识别模型;其中,所述目标图像识别模型的识别结果融合所述视觉维度和所述语言维度分别对应的语义特征。
34、本说明书一个实施例实现了在训练阶段通过图像识别模型确定对应视觉维度的第一全局特征,通过文本识别模型确定对应语言维度的第二全局特征,并基于第一全局特征和第二全局特征对图像识别模型进行迭代训练,使得训练好的目标图像识别模型的识别结果融合视觉维度和语言维度分别对应的语义特征,实现了目标图像识别模型具备视觉和语言两种编码能力,提高识别准确率。后续在进行图像识别时,仅仅使用图像识别模型即可完成识别处理,提高了图像识别效率。
技术特征:
1.一种图像识别模型训练方法,包括:
2.如权利要求1所述的方法,通过图像识别模型确定所述样本文本图像对应视觉维度的第一全局特征,包括:
3.如权利要求2所述的方法,通过所述图像识别模型中的图像卷积单元对所述样本文本图像进行图像特征提取处理,得到所述样本文本图像的图像特征,包括:
4.如权利要求1所述的方法,通过文本识别模型确定所述样本文本标签对应语言维度的第二全局特征,包括:
5.如权利要求1所述的方法,根据所述第一全局特征和所述第二全局特征对所述图像识别模型进行迭代训练,包括:
6.如权利要求1所述的方法,根据所述第一全局特征和所述第二全局特征对所述图像识别模型进行迭代训练,包括:
7.如权利要求1所述的方法,获取样本文本图像和所述样本文本图像的样本文本标签,包括:
8.如权利要求1-7任意一项所述的方法,所述模型训练结束条件包括下述至少一项:
9.一种图像识别方法,包括:
10.一种图像识别方法,包括:
11.一种图像识别模型训练装置,包括:
12.一种图像识别装置,包括:
13.一种计算设备,包括:
14.一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现权利要求1至10任意一项所述方法的步骤。
技术总结
本说明书实施例提供图像识别模型的训练方法及装置、图像识别方法及装置,其中所述图像识别模型的训练方法包括:获取样本文本图像和样本文本图像的样本文本标签;通过图像识别模型确定样本文本图像对应视觉维度的第一全局特征,以及通过文本识别模型确定样本文本标签对应语言维度的第二全局特征;根据第一全局特征和第二全局特征对图像识别模型进行迭代训练,直至获得满足模型训练结束条件的目标图像识别模型;其中,目标图像识别模型的识别结果融合视觉维度和语言维度分别对应的语义特征。在训练阶段基于第一全局特征和第二全局特征进行迭代训练,使模型具备视觉和语言两种编码能力,提高识别效率和准确率。
技术研发人员:赵星然,李亚东,王洪彬
受保护的技术使用者:支付宝(杭州)信息技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!