一种基于置信区间的深度强化学习动作决策方法
本发明属于人工智能,具体涉及一种基于深度神经网络和置信区间的深度强化学习动作决策方法。
背景技术:
1、近十年来,深度强化学习渐渐成为了热点领域,被应用在了许多行业中,比如无人驾驶、智能制造和机器人控制等。深度神经网络,尤其是卷积网络,能够通过多层卷积核对图像的特征进行提取,在感知图像信息、处理高维数据方面有着巨大优势,因此被广泛应用于计算机视觉、自然语言处理等领域;以深度神经网络为基础的深度学习在特征提取方面效果显著,但是它却不能理解环境并做出决策。而强化学习的本质就是决策,即让智能体不断试错,通过环境给予的奖励来不断积累经验并学习,从而估算出各个状态和动作的真实价值,最终学会可以获得最大收益的决策策略。将深度神经网络和强化学习结合在一起,形成的深度强化学习,既能感知复杂的环境,又能做出适当的决策。
2、一个标准的深度强化学习算法必然包括一个合适的动作决策方法,以良好平衡每个动作选择的两种情况:探索(explore)和利用(exploit);动作决策方法对深度强化学习算法的收敛速度和能否学会最优策略有着直接影响。
3、传统强化学习中,主要有三种动作决策方法:①∈-贪心算法,基于一个概率来平衡探索和利用;②softmax法,基于当前已知的动作的平均奖赏来平衡探索和利用;③置信区间上界算法(ucb),ucb是采用置信水平来实现对开发与探索之间的平衡。
4、复杂的强化学习问题通常有着高维状态空间或者高维动作空间,传统强化学习算法缺乏适当的方法处理它们,常常导致维数爆炸,所以传统强化学习算法仅能处理小规模问题,其能力有限。现有技术中的深度强化学习算法,主要使用ε-贪心法和softmax法来进行动作决策;ε-贪心法虽然普适性很好,但是它过度的随机性会导致收敛过慢或者智能体无法学习到最优策略;而softmax法因其容易过度依赖初始状态,无法解决连续动作空间问题,难以处理高维状态空间,也无法很好地解决复杂的强化学习问题;ucb很好地克服了ε-贪心法和softmax法的缺点,但因现有技术中缺乏ucb面对复杂问题时处理高维状态空间的手段,而难以被应用于深度强化学习算法中。
技术实现思路
1、针对现有技术的不足,本发明提供一种基于置信区间的深度强化学习动作决策方法,用于解决复杂的强化问题,该方法提出一种基于深度神经网络的置信区间跨度拟合模型,从根本上解决ucb无法估计高维状态空间下各个动作的置信区间大小的问题;设计了平衡置信区间跨度和训练过程中的探索与利用的方法,使得该方法获得了理想的训练效果。
2、为实现上述目的,本发明提供了如下技术方案:
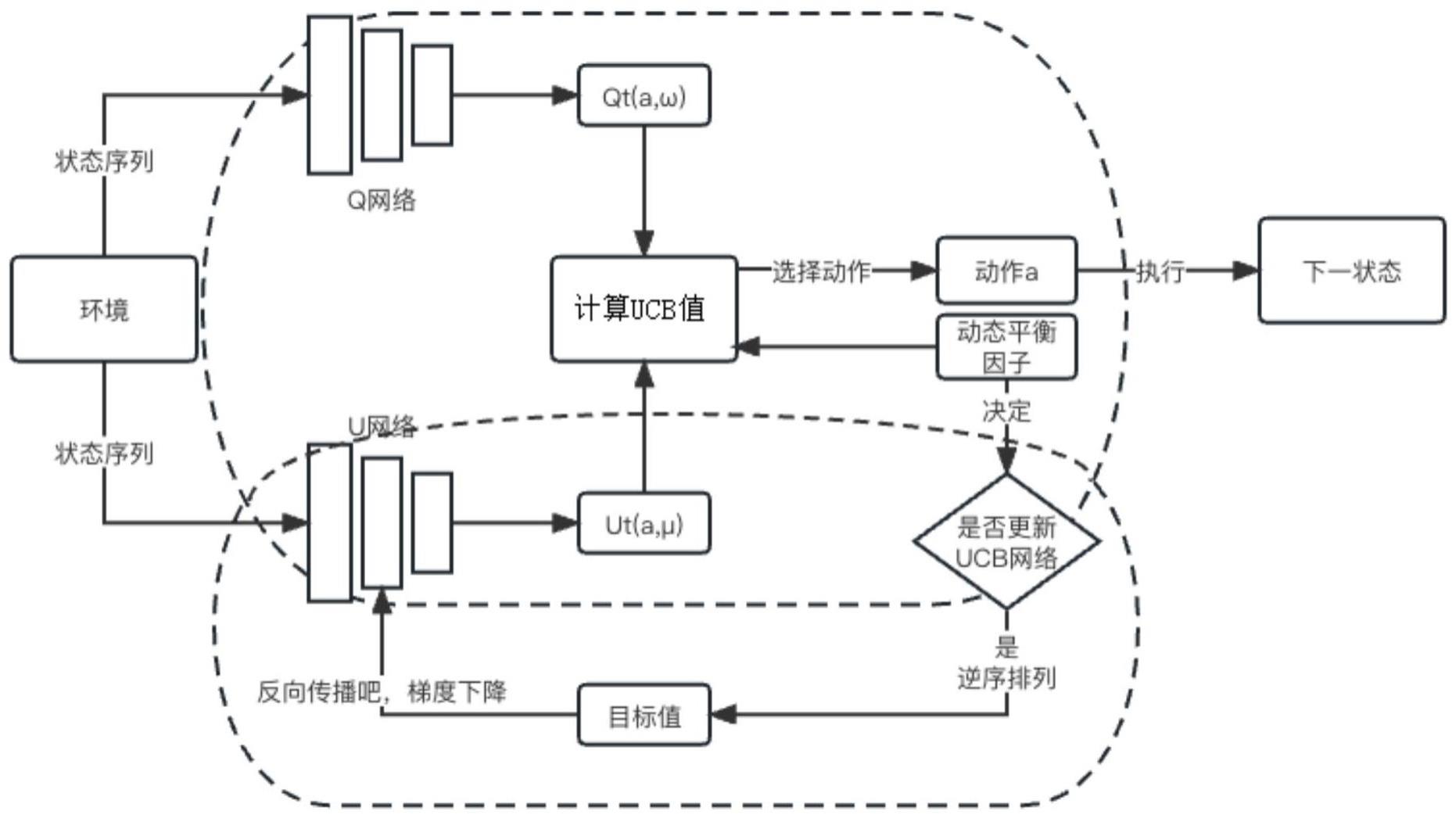
3、一种基于置信区间的深度强化学习动作决策方法,其特征在于,包括:分别用于获得动作价值和置信区间跨度的两个深度强化学习网络,q网络和u网络;基于目标值原地构建的置信区间跨度平衡模型,利用神经网络反向传播的特性在每次动作决策后更新u网络的参数,从而平衡置信区间跨度;用于平衡训练过程中的价值和置信区间跨度两指标探索与利用的动态平衡因子α,;其中0<α<1,随训练次数的增加逐渐减小。
4、优选地,其特征在于,包括如下步骤:(1)搭建两个深度神经网络q网络和u网络,所述q网络和所述u网络结构相同;
5、(2)设置训练终止条件和迭代参数,并分别初始化q网络和u网络参数ω、μ;
6、(3)初始化环境;
7、(4)获得当前训练周期下的动态平衡因子α;
8、(5)将环境状态序列并行输入到q网络和u网络,分别获得当前动作价值qt(a,ω)和当前动作置信区间跨度ut(a,μ);
9、(6)根据步骤(3)获得的动态平衡因子α和步骤(4)获得的qt(a,ω)ut(a,μ),计算各个动作的ucb值,并选择ucb值最大的动作a,即:按照如下公式选择动作:
10、
11、在0至1之间随机取得一个数作为基础值,若α大于该基础值,则更新u网络参数μ;若α小于该基础值,则不更新u网络参数μ;
12、(8)执行动作a,更新q网络参数ω;
13、(9)循环执行步骤(5)~(8),遍历每个环境状态,更新q网络参数ω和u网络参数μ;
14、(10)循环执行步骤(3)~(8),直至达到训练终止条件。
15、优选地,上述方法和步骤中更新u网络参数的方法包括:(1)将当前置信区间跨度ut(a,μ)的值逆序排列作为目标值计算损失;(2)基于损失,通过神经网络的梯度反向传播来更新u网络的参数μ。
16、优选地,上述方法和步骤中动态平衡因子α按照如下公式获得:
17、α=0.05+0.95×e^(-f/base)
18、其中,f是训练帧数,e是自然常数,base是一个用于控制衰减速率的常数。
19、与现有技术相比,本发明的有益效果是:
20、1.因为本发明搭建两个深度神经网络,分别用于拟合ucb算法中的利用和探索两部分的数据,以实现状态空间数据降维的目的,从根本上解决ucb无法估计高维状态空间下各个动作的置信区间大小的问题;
21、2.因为本发明利用深度神经网络的反向传播和梯度下降的特性,实现置信区间跨度平衡,而且利用原本的ut(a,μ)值逆序排列作为目标值,即原地构造u网络的目标值,效率高、平衡效果好。
22、3.因为本发明引入动态平衡因子α,用于平衡训练过程中的探索与利用,动态平衡因子α是作为一种加权系数直接作用在代表探索和利用的两个数值上,更有策略性,不会造成过度随机的问题;而且动态平衡因子α还决定该次迭代是否需要进行u网络的反向传播和参数更新,有效提高了训练效率。
技术特征:
1.一种基于置信区间的深度强化学习动作决策方法,其特征在于,包括:
2.根据权利要求1所述的一种基于置信区间的深度强化学习动作决策方法,其特征在于,包括如下步骤:
3.根据权利要求1或2所述的一种基于置信区间的深度强化学习动作决策方法,其特征在于,所述更新u网络参数的方法包括:
4.根据权利要求1或2所述的一种基于置信区间的深度强化学习动作决策方法,其特征在于,所述动态平衡因子α按照如下公式获得:
技术总结
本发明属于人工智能技术领域,公开了一种基于置信区间的深度强化学习动作决策方法,该方法首先提出一种基于深度神经网络的置信区间跨度拟合模型,从根本上解决UCB无法估计高维状态空间下各个动作的置信区间大小的问题;然后提出一种基于目标值原地构建的置信区间跨度平衡模型,利用神经网络反向传播的特性在每次动作决策后更新U网络的参数,从而平衡置信区间跨度;最后引入探索‑利用动态平衡因子α用于平衡训练过程中的探索与利用。该方法应用于解决复杂强化问题,取得了较好的训练效果。
技术研发人员:安康,梁巧,张文浩,宋亚庆,刘翔鹏,张会
受保护的技术使用者:上海师范大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!