规范化名称的确定方法、系统、设备及介质与流程
本发明涉及自然语言处理领域及数字医疗领域,特别涉及一种规范化名称的确定方法、系统、设备及介质。
背景技术:
1、随着科技的迅猛发展,机器学习技术已经在医疗领域得到了深入的应用,为传统医疗技术应用带来了极大的创新。在医疗领域中,有些名称可能会有多种不同的称呼,需要对名称进行规范化处理,以便用户可以根据各称呼查询到同一名称。业界现有的名称规范化的方法主要包括人工标注方法、基于字面相似度的方式和基于深度学习的语义匹配方法。人工标注方法是通过人工整理各种名称的全称、别名、缩略名,然后通过精准匹配以实现名称的规范化。基于字面相似度的方式常见于利用es搜索引擎的bm25算法,将得到的一个字面相似度很高的全称作为规范化名称。基于深度学习的语义匹配方法主要是通过基于深度学习的有监督训练,将待规范化的名称和预存的多个不同的名称进行语义匹配,进而得到规范化名称。
2、发明人意识到,上述人工标注方法成本极高,在工程上难以有效应用。基于字面相似度的方式针对字面相似度差异很小的各名称,很难有效地进行区分,还会造成字面相似度低,但语义相同的名称不能被规范化。而基于深度学习的语义匹配方法需要进行大量的人工数据标注,费时费力。
技术实现思路
1、本发明的目的在于提供一种规范化名称的确定方法、系统、设备及介质。以解决现有的名称规范化方法无法对字面相似度高且语义差异大的样本,以及字面相似度低且语义相似度高的样本进行准确区分,导致规范化名称的识别率低的问题。
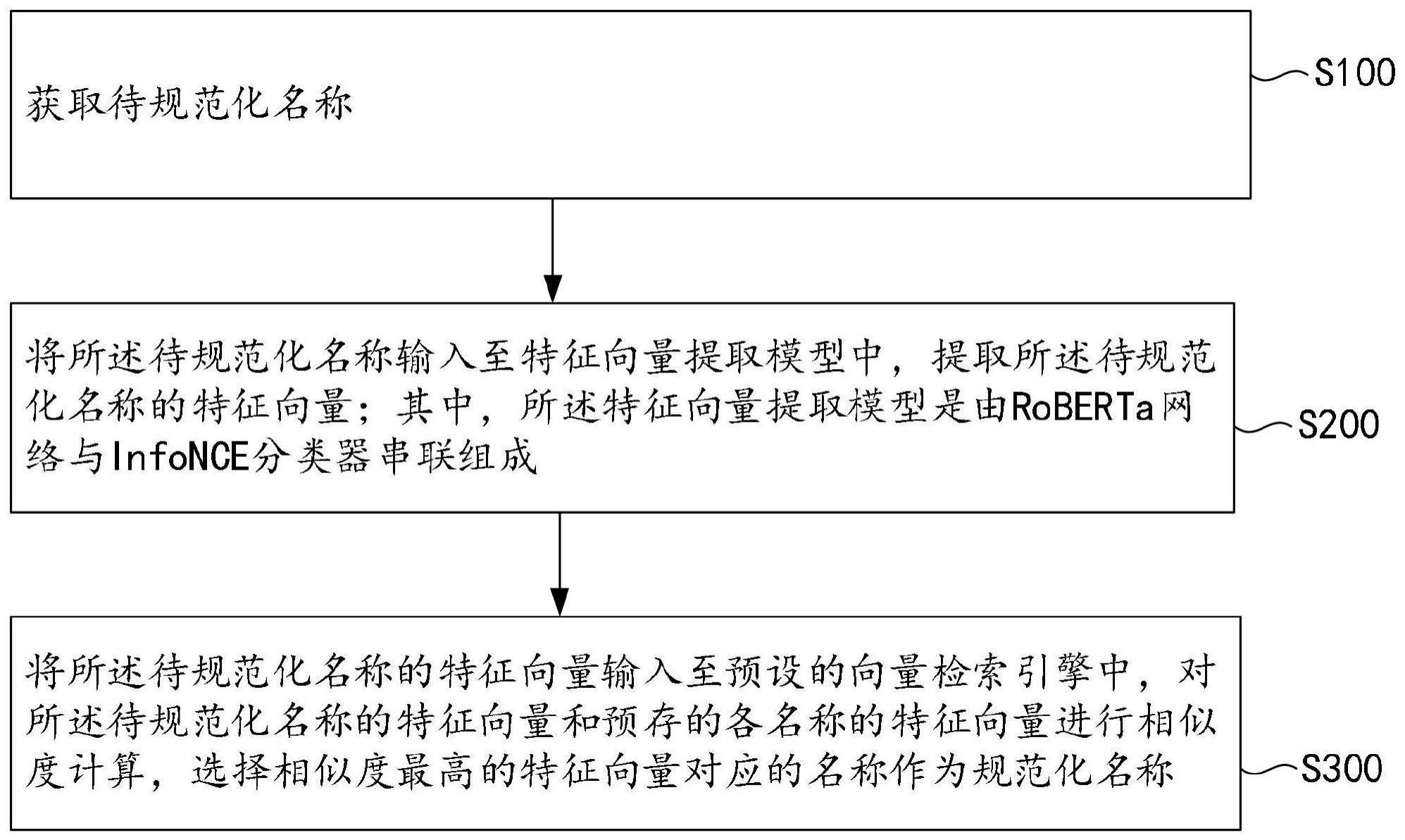
2、第一方面,提供了一种规范化名称的确定方法,包括:
3、获取待规范化名称;
4、将所述待规范化名称输入至特征向量提取模型中,提取所述待规范化名称的特征向量;其中,所述特征向量提取模型是由roberta网络与infonce分类器串联组成;
5、将所述待规范化名称的特征向量输入至预设的向量检索引擎中,对所述待规范化名称的特征向量和预存的各名称的特征向量进行相似度计算,选择相似度最高的特征向量对应的名称作为规范化名称。
6、第二方面,提供了一种规范化名称的确定系统,包括:
7、待规范化名称获取模块,用于获取待规范化名称;
8、特征向量获取模块,用于将所述待规范化名称输入至特征向量提取模型中,提取所述待规范化名称的特征向量;其中,所述特征向量提取模型是由roberta网络与infonce分类器串联组成;
9、名称确定模块,用于将所述待规范化名称的特征向量输入至预设的向量检索引擎中,对所述待规范化名称的特征向量和预存的各名称的特征向量进行相似度计算,选择相似度最高的特征向量对应的名称作为规范化名称。
10、第三方面,提供了一种计算机设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器计算机程序时实现上述意图识别方法的步骤。
11、第四方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器时实现上述意图识别方法的步骤。
12、本发明的规范化名称的确定方法、系统、设备及介质。通过获取待规范化名称,并将其输入至预先训练好的特征向量提取模型中,从而获取待规范化名称的特征向量。然后将待规范化名称的特征向量输入到预先设置的向量检索引擎中,通过计算向量检索引擎中,预存的各名称的特征向量和该待规范化名称的特征向量的相似度,选择相似度最高的特征向量对应的名称即可作为规范化名称。能够精准确定规范化名称。在本发明中,针对现有技术中,进行名称规范化识别时,对于字面相似低且语义相似度高的样本,无法准确区分的问题。通过使用特征向量提取模型,利用roberta网络强大的语义表征能力,可以更加准确的提取待规范化名称的特征向量,从而为后续准确识别规范化名称奠定了基础。且使用向量检索引擎和特征向量提取模型进行规范化名称的确定,极大的加快了线上获取规范化名称的响应时间,能够快速的对输入的待规范化名称做出响应,加快了标准化服务的整体响应周期。借助于深度学习模型的语义表征优势,实现了对于字面相似度低且语义相似度高的名称的标准化,为传统的对于名称的规范化带来了极大的创新。
技术特征:
1.一种规范化名称的确定方法,其特征在于,包括:
2.根据权利要求1所述的规范化名称的确定方法,其特征在于,所述特征向量提取模型是通过训练获得的,所述特征向量提取模型的训练过程包括:
3.根据权利要求2所述的规范化名称的确定方法,其特征在于,所述使用所述es搜索引擎获取所述标准样本的一个或多个负样本,包括:
4.根据权利要求2所述的规范化名称的确定方法,其特征在于,所述将正样本、标准样本和负样本输入至待训练的特征向量提取模型中进行训练之前,还包括:分别对正样本、标准样本和负样本进行词嵌入,得到词嵌入后的正样本、词嵌入后的标准样本和词嵌入后的负样本。
5.根据权利要求2所述的规范化名称的确定方法,其特征在于,所述将正样本、标准样本和负样本输入至待训练的特征向量提取模型中进行训练,并基于训练得到的正样本特征向量、负样本特征向量和标准样本特征向量,更新待训练的特征向量提取模型的权重,包括:
6.根据权利要求5所述的规范化名称的确定方法,其特征在于,所述通过语义信息编码和非线性运算,提取所述正样本的特征向量,包括:
7.根据权利要求1所述的规范化名称的确定方法,其特征在于,所述将所述待规范化名称的特征向量输入至预设的向量检索引擎中,对所述待规范化名称的特征向量和预存的各名称的特征向量进行相似度计算,选择相似度最高的特征向量对应的名称作为规范化名称,包括:
8.一种规范化名称的确定系统,其特征在于,所述系统包括:
9.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器所述计算机程序时实现权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器时实现权利要求1至7中任一项所述的方法的步骤。
技术总结
本发明涉及自然语言处理领域及数字医疗领域,提供一种规范化名称的确定方法、系统、设备及介质。所述方法包括:获取待规范化名称;将所述待规范化名称输入至特征向量提取模型中,提取所述待规范化名称的特征向量;其中,所述特征向量提取模型是由RoBERTa网络与InfoNCE分类器串联组成;将所述待规范化名称的特征向量输入至预设的向量检索引擎中,对所述待规范化名称的特征向量和预存的各名称的特征向量进行相似度计算,选择相似度最高的特征向量对应的名称作为规范化名称。能够快速精准的确定待规范化名称的规范化名称。
技术研发人员:付桂振
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!