基于知识图谱的语义分析方法与流程
本发明涉及语义分析,特别涉及基于知识图谱的语义分析方法。
背景技术:
1、近年来,语音识别技术的发展较大程度的提高了人机交互水平,而语义分析技术作为理解自然语言的关键部分,对于人机交互的智能化程度起到了决定性作用。然而,从自然语言的角度来说,大部分词具有一词多义的特点,一个词除了表达本意之外,还可能具有其它的隐含语义,仅通过关键字进行识别的方法无法准确识别出其实际意义。此外,当句子为口语化语句时,语义分析过程中可能无法寻找到句子中的谓语,进而难以实现准确的语义分析;
2、知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它把复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制而显示出来,揭示知识领域的动态发展规律,为学科研究提供切实的、有价值的参考。
3、因此,有必要提供基于知识图谱的语义分析方法解决上述技术问题。
技术实现思路
1、为解决上述技术问题,本发明提供基于知识图谱的语义分析方法。
2、本发明提供的基于知识图谱的语义分析方法,具体步骤如下:
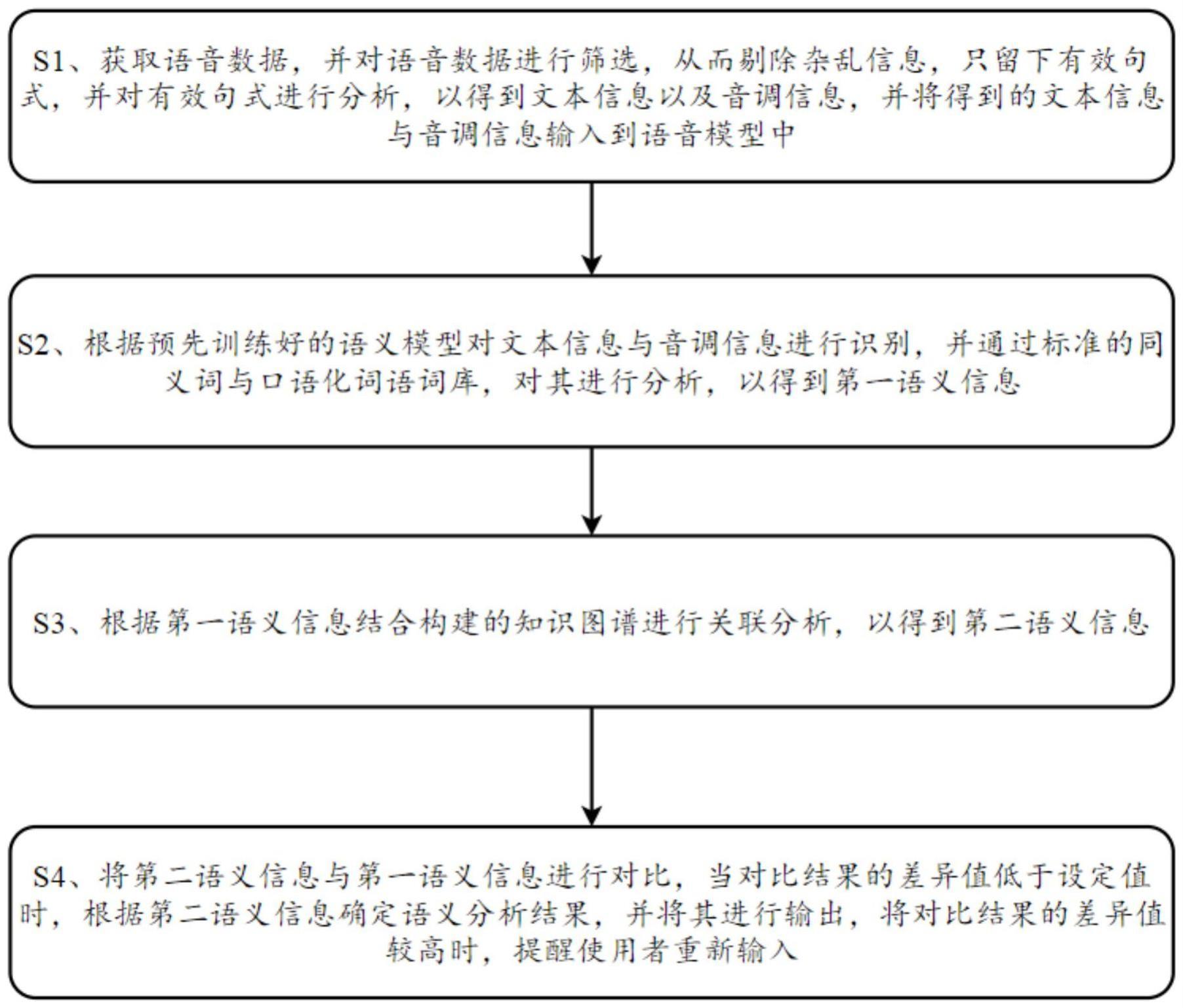
3、s1、获取语音数据,并对语音数据进行筛选,从而剔除杂乱信息,只留下有效句式,并对有效句式进行分析,以得到文本信息以及音调信息,并将得到的文本信息与音调信息输入到语音模型中;
4、s2、根据预先训练好的语义模型对文本信息与音调信息进行识别,并通过标准的同义词与口语化词语词库,对其进行分析,以得到第一语义信息;
5、s3、根据第一语义信息结合构建的知识图谱进行关联分析,以得到第二语义信息;
6、s4、将第二语义信息与第一语义信息进行对比,当对比结果的差异值低于设定值时,根据第二语义信息确定语义分析结果,并将其进行输出,将对比结果的差异值较高时,提醒使用者重新输入。
7、优选的,所述知识图谱的构建的具体方法为:
8、s31、通过可视化方式对接各种数据源,以及对数据源进行校验及管理,根据数据源建立基本知识库;
9、s32、对数据源进行解析,将其解析生成多个语义向量;
10、s33、对生成的语义向量进行数据融合,并对融合后的语义向量之间挖掘关联关系,生成语义向量之间关系;
11、s34、对将融合后的语义向量与语义向量之间关系构成语义数据库,并将其存储在服务器中,并对语义数据库进行质量评估,完成知识图谱的构建。
12、优选的,所述步骤s31中数据源包括标准的同义词与口语化词语词库,用户填写的基本信息,用户平时的行为数据、用户的聊天信息与网络上公开的网页数据。
13、优选的,获取语音数据,对语音数据进行筛选,从而剔除杂乱信息,只留下有效句式,并对有效句式进行分析,以得到文本信息的步骤为:
14、s11、从所述语音数据中提取声音特征量;
15、s12、将所述声音特征量与声音库内的模型化的声音数据进行匹配,以获取相似度匹配的声音数据;
16、s13、把所述声音数据与文字语音库内存储的语音数据进行对比匹配,得出文本信息。
17、优选的,所述文字语音库中存储有文字、文字对应的语音和文字扩展词句的语音数据。
18、优选的,获取语音数据,对语音数据进行筛选,从而剔除杂乱信息,只留下有效句式,并对有效句式进行分析,以得到音调信息的步骤为:
19、s14、对所述语音数据进行频谱分析,并从所述语音数据中提取出声调音素;
20、s15、根据所述声调音素在声调模型中匹配出所述语音数据的声调。
21、优选的,根据预先训练好的语义模型对文本信息与音调信息进行识别,并通过标准的同义词与口语化词语词库,对其进行分析,以得到第一语义信息的步骤为:
22、s21、通过语音模型对音调信息进行识别,并得到音调顺序,可通过音调信息剔除文本信息中音调顺序与识别出的音调顺序音调信息差距过大的组合;
23、s22、通过语义模型对所述文本信息进行分词,得到至少一个词语;分别获取所述至少一个词语的特性;
24、s23、根据所述特性分别确定所述至少一个词语包含的信息量,并从所述至少一个词语中选取包含信息量多的至少一个词语作为关键词;
25、s24、分别以所述关键词为中心做窗口,确定所述关键词的上下文词语;
26、s25、将所述上下文词语与标准的同义词与口语化词语词库进行匹配,得到匹配结果;
27、s26、根据所述匹配结果分析语义,以得到第一语义信息。
28、与相关技术相比较,本发明提供的基于知识图谱的语义分析方法具有如下
29、有益效果:
30、1、本发明根据根据预先训练好的语义模型对语音数据中的文本信息与音调信息进行识别,并通过标准的同义词与口语化词语词库,对其进行分析,以得到第一语义信息,根据第一语义信息结合构建的知识图谱进行关联分析,以得到第二语义信息,通过第二语义信息与第一语义信息对比,得到最终输出的语音信息,通过双语音信息的对比,可得到更加符合使用者要求的语义信息,提高对语义数据中信息解析的准确率;
31、2、本发明在进行语义分析前,先进行知识图谱的构建,通过对数据源进行解析,将其解析生成多个语义向量;对生成的语义向量进行数据融合,并对融合后的语义向量之间挖掘关联关系,生成语义向量之间关系,对将融合后的语义向量与语义向量之间关系构成语义数据库,并将其存储在服务器中,并对语义数据库进行质量评估,完成知识图谱的构建,通过语义向量之间的关系,可实现准确的语义分析;
技术特征:
1.基于知识图谱的语义分析方法,其特征在于,具体步骤如下:
2.根据权利要求1所述的基于知识图谱的语义分析方法,其特征在于,所述知识图谱的构建的具体方法为:
3.根据权利要求2所述的基于知识图谱的语义分析方法,其特征在于,所述步骤s31中数据源包括标准的同义词与口语化词语词库,用户填写的基本信息,用户平时的行为数据、用户的聊天信息与网络上公开的网页数据。
4.根据权利要求1所述的基于知识图谱的语义分析方法,其特征在于,获取语音数据,对语音数据进行筛选,从而剔除杂乱信息,只留下有效句式,并对有效句式进行分析,以得到文本信息的步骤为:
5.根据权利要求4所述的基于知识图谱的语义分析方法,其特征在于,所述文字语音库中存储有文字、文字对应的语音和文字扩展词句的语音数据。
6.根据权利要求1所述的基于知识图谱的语义分析方法,其特征在于,获取语音数据,对语音数据进行筛选,从而剔除杂乱信息,只留下有效句式,并对有效句式进行分析,以得到音调信息的步骤为:
7.根据权利要求1所述的基于知识图谱的语义分析方法,其特征在于,根据预先训练好的语义模型对文本信息与音调信息进行识别,并通过标准的同义词与口语化词语词库,对其进行分析,以得到第一语义信息的步骤为:
技术总结
本发明涉及语义分析技术领域,特别涉及基于知识图谱的语义分析方法,通过获取语音数据,并对语音数据进行筛选,从而剔除杂乱信息,留下有效句式,对有效句式进行分析,得到文本信息以及音调信息,根据预先训练好的语义模型对文本信息与音调信息进行识别,并通过标准的同义词与口语化词语词库,对其进行分析,得到第一语义信息,根据第一语义信息结合构建的知识图谱进行关联分析,得到第二语义信息,将第二语义信息与第一语义信息进行对比,当对比结果的差异值低于设定值时,将第二语义信息输出,将对比结果的差异值较高时,提醒使用者重新输入,通过双语音信息的对比,可得到更加符合使用者要求的语义信息,提高对语义数据中信息解析的准确率。
技术研发人员:瞿珂,万澎江,张少杰,于政,翟士丹
受保护的技术使用者:北京海致科技集团有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!