一种跨数据源数据迁移方法及系统与流程
本发明属于数据库,具体涉及一种跨数据源数据迁移方法及系统。
背景技术:
1、目前,在互联网支付场景及大数据体系中,大部分项目都采用分布式微服务架构,各系统进行微服务拆分,且使用到多数据源及分库分表场景。但是如果存在跨系统数据迁移时,传统的视图、函数、临时库表存储已经不能满足迁移需求,给大批量的历史数据跨库跨表查询维护带来很大的困难,且传统方法成本消耗较大。
技术实现思路
1、针对现有技术中的缺陷,本发明提供一种跨数据源数据迁移方法及系统,解决传统模式下数据迁移成本过高的缺陷。
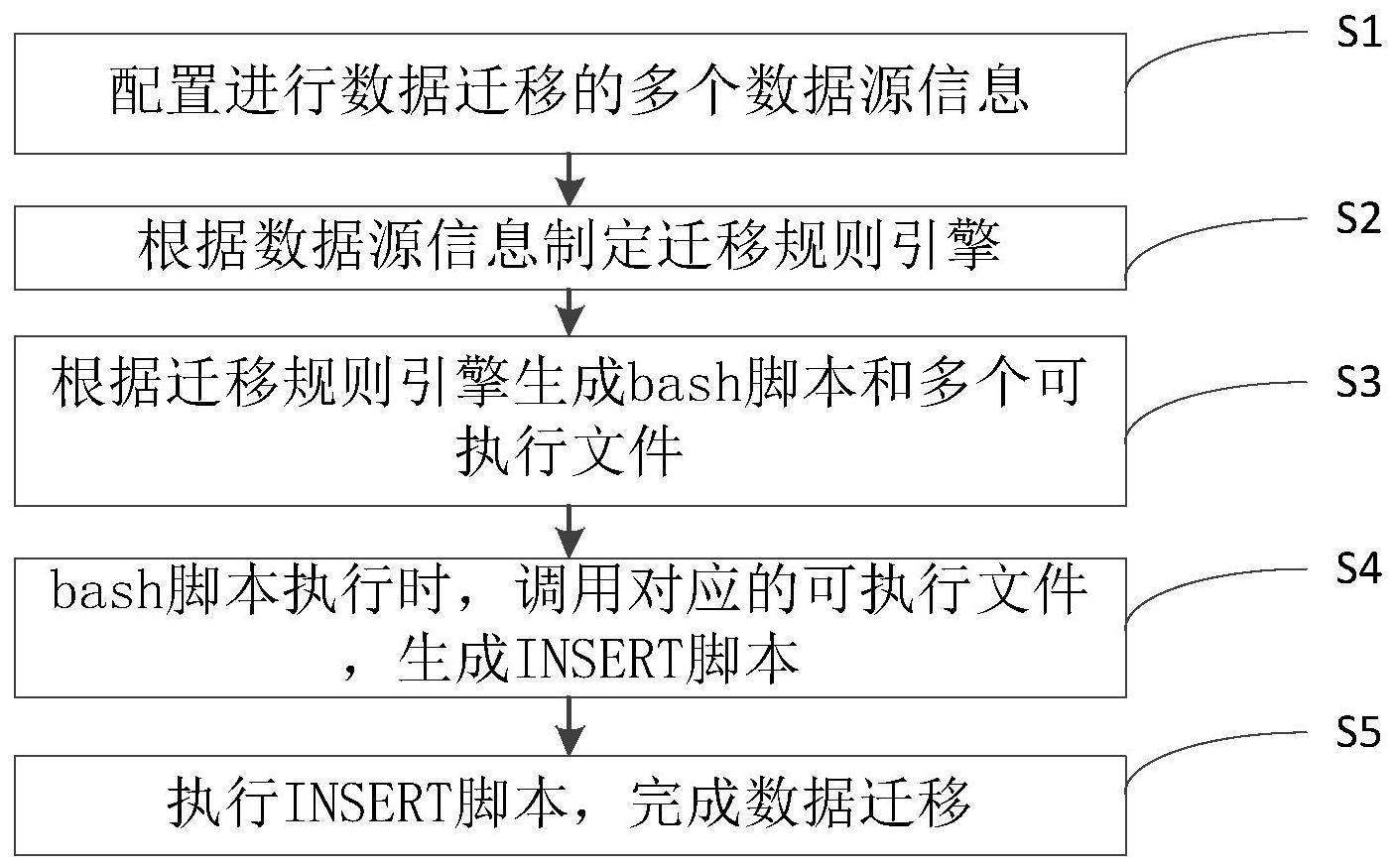
2、第一方面,一种跨数据源数据迁移方法,包括:
3、配置进行数据迁移的多个数据源信息;
4、根据数据源信息制定迁移规则引擎;
5、根据迁移规则引擎生成bash脚本和多个可执行文件;可执行文件与迁出数据源一一对应;
6、bash脚本执行时,调用对应的可执行文件,生成insert脚本;
7、执行insert脚本,完成数据迁移。
8、进一步地,配置进行数据迁移的多个数据源信息具体包括:
9、配置数据源信息;数据源信息包括迁出数据源、迁入数据源;
10、建立迁出数据源中字段与迁入数据源中字段的关联关系,以得到数据迁移关联关系;
11、将数据迁移关联关系存入临时库表中。
12、进一步地,根据数据源信息制定迁移规则引擎具体包括:
13、根据数据源信息确定迁移决策;迁移决策包括数据源的连接信息、迁出数据源的数据库查询语句、迁入数据源的数据库插入语句;
14、根据迁移决策制定迁移规则引擎。
15、进一步地,将数据迁移关联关系存入临时库表中具体包括:
16、当临时库表中不存在数据迁移关联关系时,在临时库表中创建临数据迁移关联关系。
17、进一步地,bash脚本执行时,具体包括:
18、根据迁入数据源生成insert前缀;
19、读取迁出数据源对应的可执行文件;
20、根据可执行文件查询迁移规则引擎,以得到迁出数据源的迁出数据;
21、将迁出数据以字段作为存储id;
22、当临时库表不存在存储id时,在临时库表中新建存储id,将迁出数据对应存储在临时库表中存储id下;
23、当临时库表存在存储id时,更新临时库表中存储id下的迁出数据;
24、读取临时库表中迁出数据,与insert前缀组装得到insert脚本。
25、第二方面,一种跨数据源数据迁移系统,包括:
26、配置单元:用于配置进行数据迁移的多个数据源信息;
27、引擎生成器:用于根据数据源信息制定迁移规则引擎;
28、第一脚本生成器:用于根据迁移规则引擎生成bash脚本和多个可执行文件;可执行文件与迁出数据源一一对应;
29、第二脚本生成器:用于当bash脚本执行时,调用对应的可执行文件,生成insert脚本;
30、执行单元:用于执行insert脚本,完成数据迁移。
31、进一步地,配置单元具体用于:
32、配置数据源信息;数据源信息包括迁出数据源、迁入数据源;
33、建立迁出数据源中字段与迁入数据源中字段的关联关系,以得到数据迁移关联关系;
34、将数据迁移关联关系存入临时库表中。
35、进一步地,引擎生成器具体用于:
36、根据数据源信息确定迁移决策;迁移决策包括数据源的连接信息、迁出数据源的数据库查询语句、迁入数据源的数据库插入语句;
37、根据迁移决策制定迁移规则引擎。
38、进一步地,引擎生成器具体用于:
39、当临时库表中不存在数据迁移关联关系时,在临时库表中创建临数据迁移关联关系。
40、进一步地,第二脚本生成器具体用于:
41、当bash脚本执行时,根据迁入数据源生成insert前缀;
42、读取迁出数据源对应的可执行文件;
43、根据可执行文件查询迁移规则引擎,以得到迁出数据源的迁出数据;
44、将迁出数据以字段作为存储id;
45、当临时库表不存在存储id时,在临时库表中新建存储id,将迁出数据对应存储在临时库表中存储id下;
46、当临时库表存在存储id时,更新临时库表中存储id下的迁出数据;
47、读取临时库表中迁出数据,与insert前缀组装得到insert脚本。
48、由上述技术方案可知,本发明提供的跨数据源数据迁移方法及系统,可自定义迁移规则引擎,从而实现多源异构的整合模式,动态化生成数据迁移脚本,将源数据转入目标数据库,帮助企业/银行等金融机构系统实现多源数据的动态迁移,解决传统模式下数据迁移成本过高、迁移时间过长、数据源兼容性低的问题。
技术特征:
1.一种跨数据源数据迁移方法,其特征在于,包括:
2.根据权利要求1所述跨数据源数据迁移方法,其特征在于,所述配置进行数据迁移的多个数据源信息具体包括:
3.根据权利要求2所述跨数据源数据迁移方法,其特征在于,所述根据所述数据源信息制定迁移规则引擎具体包括:
4.根据权利要求3所述跨数据源数据迁移方法,其特征在于,所述将所述数据迁移关联关系存入临时库表中具体包括:
5.根据权利要求4所述跨数据源数据迁移方法,其特征在于,所述bash脚本执行时,具体包括:
6.一种跨数据源数据迁移系统,其特征在于,包括:
7.根据权利要求6所述跨数据源数据迁移系统,其特征在于,所述配置单元具体用于:
8.根据权利要求7所述跨数据源数据迁移系统,其特征在于,所述引擎生成器具体用于:
9.根据权利要求8所述跨数据源数据迁移系统,其特征在于,所述引擎生成器具体用于:
10.根据权利要求9所述跨数据源数据迁移系统,其特征在于,所述第二脚本生成器具体用于:
技术总结
本发明提供了跨数据源数据迁移方法及系统,方法包括:配置进行数据迁移的多个数据源信息;根据数据源信息制定迁移规则引擎;根据迁移规则引擎生成bash脚本和多个可执行文件;可执行文件与迁出数据源一一对应;bash脚本执行时,调用对应的可执行文件,生成INSERT脚本;执行INSERT脚本,完成数据迁移。该方法可自定义迁移规则引擎,从而实现多源异构的整合模式,动态化生成数据迁移脚本,将源数据转入目标数据库,帮助企业/银行等金融机构系统实现多源数据的动态迁移,解决传统模式下数据迁移成本过高、迁移时间过长、数据源兼容性低的问题。
技术研发人员:李江,李家菁,杨瀚,杨晓晋,何当清
受保护的技术使用者:深圳市雁联计算系统有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!