奖励模型的训练数据标注方法及相关产品与流程
本申请涉及人工智能,具体涉及一种奖励模型的训练数据标注方法及相关产品。
背景技术:
1、chatgpt由open ai公司发明,它是自然语言模型的一个突破性进展,可以根据人的要求生成符合需求的文章。chatgpt已经融入微软的必应搜索引擎,当用户搜索问题时,左边显示正常搜索结果,右边显示chatgpt写的答案。奖励模型(reward model)是chatgpt的一个核心模块。目前,在对奖励模型进行训练的方式是,构造奖励模型的训练数据,其中,该训练数据包括一个问题和多个回答,首先人工根据经验,判断多个回答的优劣,对多个回答进行排序;将问题和每个回答作为分别输入到奖励模型,奖励模型会输出一个分数,该分数表示这个回答的质量。然后,基于每个回答的分数对多个回答进行排序,并根据人工对该多个回答的排序,对奖励模型进行训练。
2、可以看出,目前训练奖励模型时,需要对训练数据进行人工标注,导致训练数据的标注成本较高,而且受人工经验的影响,导致训练数据的标注质量较低。
技术实现思路
1、本申请实施例提供了一种奖励模型的训练数据标注方法及相关产品,通过对用户分组,实现自动化对奖励模型的训练数据进行标注,降低训练数据的标注成本,提高训练数据的标注质量。
2、第一方面,本申请实施例提供一种奖励模型的训练数据标注方法,包括:
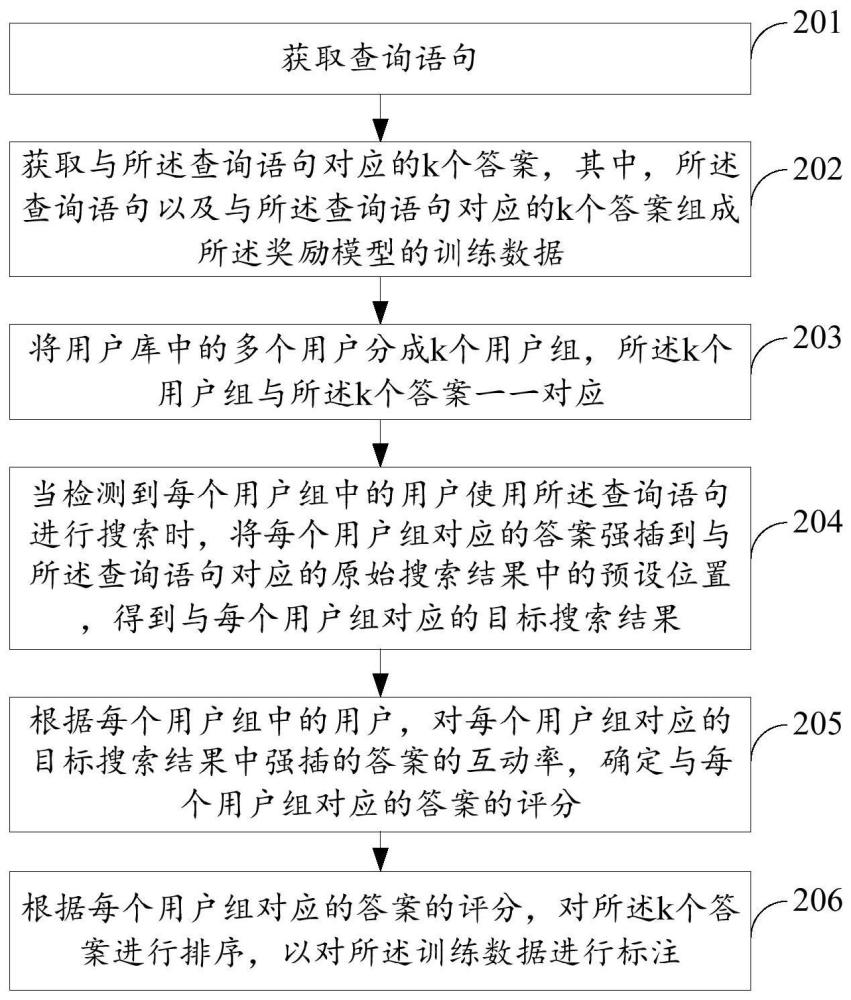
3、获取查询语句;
4、获取与所述查询语句对应的k个答案,其中,所述查询语句以及与所述查询语句对应的k个答案组成所述奖励模型的训练数据;
5、将用户库中的多个用户分成k个用户组,所述k个用户组与所述k个答案一一对应;
6、当检测到每个用户组中的用户使用所述查询语句进行搜索时,将每个用户组对应的答案强插到与所述查询语句对应的原始搜索结果中的预设位置,得到与每个用户组对应的目标搜索结果;
7、根据每个用户组中的用户,对每个用户组对应的目标搜索结果中强插的与每个用户组对应的答案的互动率,确定与每个用户组对应的答案的评分;
8、根据每个用户组对应的答案的评分,对所述k个答案进行排序,以对所述训练数据进行标注。
9、第二方面,本申请实施例提供一种奖励模型的训练数据标注装置,包括:获取单元和处理单元;
10、所述获取单元,用于获取查询语句;
11、所述处理单元,用于获取与所述查询语句对应的k个答案,其中,所述查询语句以及与所述查询语句对应的k个答案组成所述奖励模型的训练数据;
12、将用户库中的多个用户分成k个用户组,所述k个用户组与所述k个答案一一对应;
13、当检测到每个用户组中的用户使用所述查询语句进行搜索时,将每个用户组对应的答案强插到与所述查询语句对应的原始搜索结果中的预设位置,得到与每个用户组对应的目标搜索结果;
14、根据每个用户组中的用户,对每个用户组对应的目标搜索结果中强插的与每个用户组对应的答案的互动率,确定与每个用户组对应的答案的评分;
15、根据每个用户组对应的答案的评分,对所述k个答案进行排序,以对所述训练数据进行标注。
16、第三方面,本申请实施例提供一种电子设备,包括:处理器和存储器,所述处理器与存储器相连,所述存储器用于存储计算机程序,所述处理器用于执行所述存储器中存储的计算机程序,以使得所述电子设备执行如第一方面所述的方法。
17、第四方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序使得计算机执行如第一方面所述的方法。
18、第五方面,本申请实施例提供一种计算机程序产品,所述计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,所述计算机可操作来使计算机执行如第一方面所述的方法。
19、实施本申请实施例,具有如下有益效果:
20、可以看出,在本申请实施例中,在对奖励模型的训练数据(即查询语句)中的多个答案进行标注时,先为查询语句生成该多个答案;然后根据多个答案的数量将用户分成数量相同的多个用户组;然后,针对每个用户组,当检测到该用户组中的用户使用查询语句进行搜索时,则将该用户组对应的答案强插到原始搜索结果中生成目标搜索结果,并将目标搜索结果返回给该用户。这样统计每个用户组中的用户,对返回的目标搜索结果中强插的与该用户组对应的答案的互动率,确定出与该用户组对应的答案的评分,即确定出了与该用户组对应的答案的质量,从而实现每个用户组用于评判一个答案的质量。这样通过在线统计每个用户组中的用户与该用户组的答案的互动率,即可确定出多个答案的质量,无需根据人工经验评判查询语句的多个答案的质量,使确定出的多个答案的质量的精度较高;最后,基于多个答案的评分,对多个答案进行排序,即完成对多个答案的标注,从而实现无需人工对查询语句的多个答案进行人工标注,降低了奖励模型的训练数据的标注成本,并且,由于避免了人工经验标注的干扰,使训练数据的标注质量精度较高。而且,不需要人工标注,可以为奖励模型,标注大量的训练数据,提高了奖励模型的训练数据的丰富性。
技术特征:
1.一种奖励模型的训练数据标注方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,根据每个用户组中的用户,根据每个用户组中的用户,对每个用户组对应的目标搜索结果中强插的与每个用户组对应的答案的互动率,确定与每个用户组对应的答案的评分之前,所述方法还包括:
3.根据权利要求1或2所述的方法,其特征在于,
4.根据权利要求1-3任一项所述的方法,其特征在于,所述获取查询语句,包括:
5.根据权利要求1-4任一项所述的方法,其特征在于,所述获取与所述查询语句对应的k个答案,包括:
6.根据权利要求1-5任一项所述的方法,其特征在于,所述将用户库中的多个用户分成k个用户组,包括:
7.根据权利要求1-6任一项所述的方法,其特征在于,所述方法还包括:
8.一种奖励模型的训练数据标注装置,其特征在于,包括:获取单元和处理单元;
9.一种电子设备,其特征在于,包括:处理器和存储器,所述处理器与所述存储器相连,所述存储器用于存储计算机程序,所述处理器用于执行所述存储器中存储的计算机程序,以使得所述电子设备执行如权利要求1-7中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行以实现如权利要求1-7中任一项所述的方法。
技术总结
本申请实施例公开了一种奖励模型的训练数据标注方法及相关产品。该方法包括:获取查询语句;获取与查询语句对应的k个答案,其中,查询语句以及与查询语句对应的k个答案组成奖励模型的训练数据;将用户库中的多个用户分成k个用户组;当检测到每个用户组中的用户使用查询语句进行搜索时,将每个用户组对应的答案强插到与查询语句对应的原始搜索结果中的预设位置,得到与每个用户组对应的目标搜索结果;根据每个用户组中的用户,对每个用户组对应的目标搜索结果中强插的与每个用户组对应的答案的互动率,确定与每个用户组对应的答案的评分;根据每个用户组对应的答案的评分,对k个答案进行排序,以对训练数据进行标注。
技术研发人员:王树森
受保护的技术使用者:小红书科技有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!