一种基于数据合成的大规模零样本数据检索方法及系统
本发明涉及信息检索,尤其涉及一种基于数据合成的大规模零样本数据检索方法及系统。
背景技术:
1、由于互联网上的大规模多媒体数据不断增长,大规模检索越来越受到人们的关注。哈希是一种流行的最近邻检索技术,可以高效检索大规模多媒体数据,它学习保持原样本空间相似性的哈希函数,将高维数据编码为紧凑的二进制码,并基于逐位异或操作实现高效的相似性搜索。从而实现更短的检索响应时间和更少的计算成本。
2、然而,传统的监督哈希方法面临巨大的挑战:新兴语义概念和多媒体数据增长迅猛,由于高昂的人工标注成本,监督知识不能得到及时更新。对于已知类别的样本,现有的监督哈希方法可以达到令人满意的效果,因为有可靠的监督信息指导学习过程,但是这些方法不能泛化到未知类别,也就是训练数据中不包含的类别;另外,新兴语义概念可能会导致一些没有视觉数据特征的新类(未知类)出现,现有的哈希方法没有考虑到解决这类场景。
3、零样本哈希可以通过构建通用的哈希模型,从而对已知类别和未知类别都能较好地进行哈希编码。但是现有的零样本哈希检索方法存在以下问题:(1)现有的零样本哈希方法没有考虑那些只有属性矢量,没有视觉特征数据的未知类样本(未知类没有视觉特征数据,原本存在的已知类有视觉特征数据)。(2)对于同时含有已知类别和未知类别的混合数据,只考虑已知类别的数据,忽略未知类别,因此不适合混合未知数据的数据检索。(3)在哈希码学习中,大多数方法忽略了类属性信息,只考虑同质属性(比如猫和狗都属于“动物”)而忽略异质属性(比如鸟和飞机共享“翅膀”这一属性),不利于将监督知识从已知类迁移到未知类。
4、因此,现有的零样本哈希方法无法针对只有属性矢量,没有视觉特征数据的未知类样本利用同时考虑成对相似性、类标签和类属性来训练模型的方式来迁移监督知识,从而降低了大规模数据检索的准确程度。
技术实现思路
1、针对现有技术存在的不足,本发明的目的是提供一种基于数据合成的大规模零样本数据检索方法及系统,对于只有属性矢量,没有视觉特征数据的未知类样本,提出利用属性特征合成视觉特征数据。对于哈希码的学习阶段,考虑了标签信息并使用成对相似性来增强语义信息。还将视觉数据特征与类属性相结合,考虑已知类和未知类之间的关系,将监督信息从已知类传递到未知类,大大提高了检索精度。
2、为了实现上述目的,本发明是通过如下的技术方案来实现:
3、本发明第一方面提供了一种基于数据合成的大规模零样本数据检索方法,包括以下步骤:
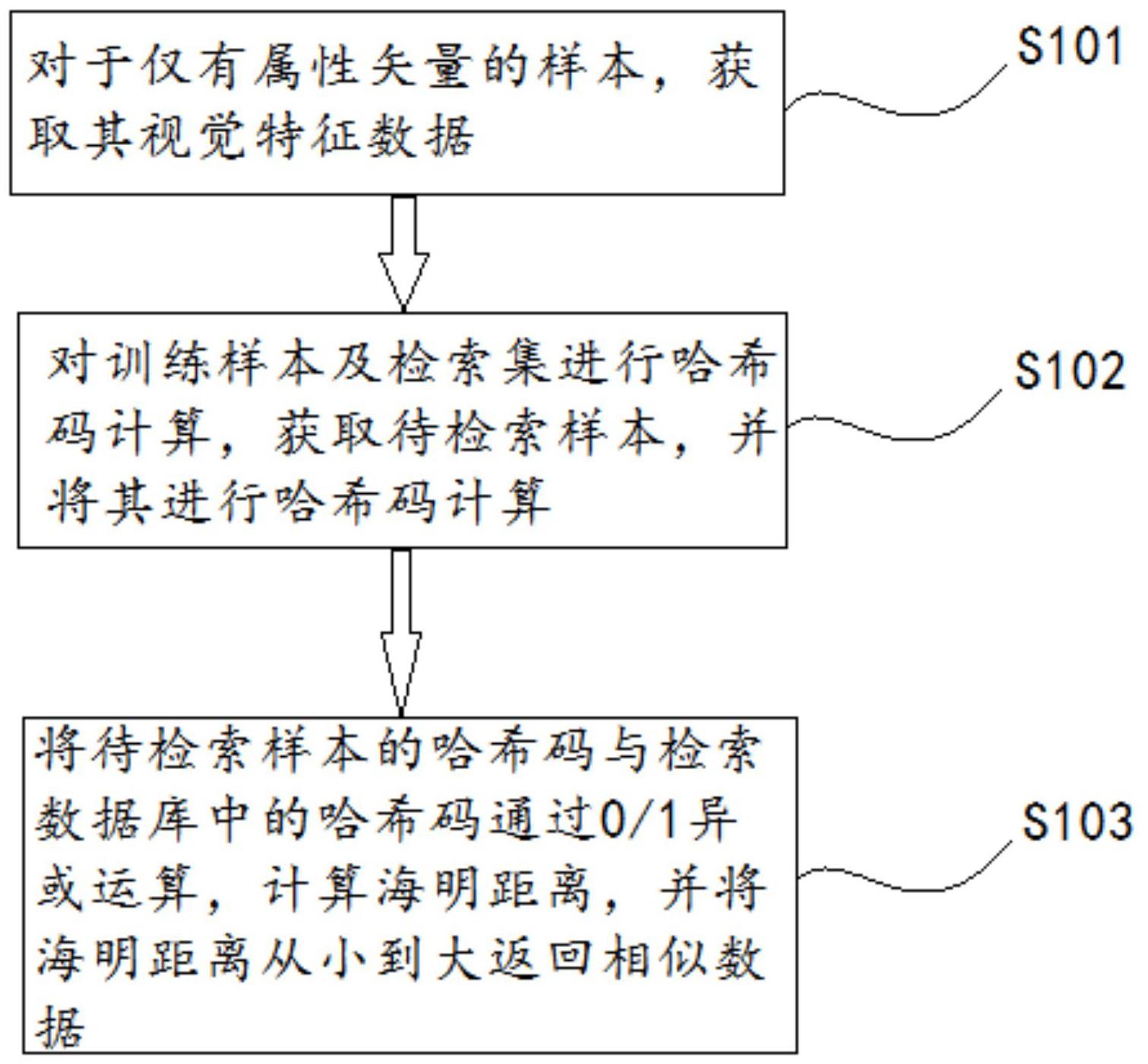
4、获取仅有属性矢量,没有视觉特征数据的未知类样本,通过从属性矢量到视觉特征数据的目标函数对未知类样本进行处理得到视觉特征数据;
5、将得到的视觉特征数据对仅有属性矢量,没有视觉特征数据的未知类样本进行补充;将补充后的未知类样本随机划分为两部分,一部分补充后的未知类样本作为测试样本,另一部分补充后的未知类样本与已知类数据集构成检索集;
6、获取现有的已知类训练样本,对现有的已知类训练样本进行处理,根据处理过的训练样本训练得到哈希码学习目标函数;具体步骤为:根据数据类别信息为训练样本添加语义标签,构成标签矩阵;基于每个类类名提取标签矩阵的实值向量构成类-属性矩阵;根据类-属性矩阵对哈希码学习目标函数进行已知类和未知类之间的关系学习得到最终的哈希码学习目标函数;
7、利用哈希码学习目标函数对训练样本与检索集分别进行计算,得到训练样本与检索集对应的哈希码;将得到的哈希码存入检索数据库中;
8、获取待检索未知类样本,根据哈希码学习目标函数对待检索未知类样本进行未知类样本拓展得到待检索未知类样本的哈希码;
9、将待检索未知类样本的哈希码与检索数据库中的哈希码通过异或运算计算海明距离,按照海明距离从小到大排列返回检索结果。
10、本发明第二方面提供了一种基于数据合成的大规模零样本数据检索系统,包括:
11、样本处理模块,被配置为获取仅有属性矢量,没有视觉特征数据的未知类样本,通过从属性矢量到视觉特征数据的目标函数对未知类样本进行处理得到视觉特征数据;
12、将得到的视觉特征数据对仅有属性矢量,没有视觉特征数据的未知类样本进行补充;将补充后的未知类样本随机划分为两部分,一部分补充后的未知类样本作为测试样本,另一部分补充后的未知类样本与已知类数据集构成检索集;
13、获取现有的已知类训练样本,对现有的已知类训练样本进行处理,根据处理过的训练样本训练得到哈希码学习目标函数;具体步骤为:根据数据类别信息为训练样本添加语义标签,构成标签矩阵;基于每个类类名提取标签矩阵的实值向量构成类-属性矩阵;根据类-属性矩阵对哈希码学习目标函数进行已知类和未知类之间的关系学习得到最终的哈希码学习目标函数;
14、利用哈希码学习目标函数对训练样本与检索集分别进行计算,得到训练样本与检索集对应的哈希码;将得到的哈希码存入检索数据库中;
15、哈希码矩阵生成模块,被配置为获取待检索未知类样本,根据哈希码学习目标函数对待检索未知类样本进行未知类样本拓展得到待检索未知类样本的哈希码;
16、检索结果获取模块,被配置为将待检索未知类样本的哈希码与检索数据库中的哈希码通过异或运算计算海明距离,按照海明距离从小到大排列返回检索结果。
17、以上一个或多个技术方案存在以下有益效果:
18、本发明公开了一种基于数据合成的大规模零样本数据检索方法及系统,对于一些只有属性矢量,没有视觉特征数据的未知类样本,引入语义数据空间作为中介从属性矢量反推得到视觉特征的数据。克服了现有零样本哈希算法直接从属性映射到特征数据导致部分信息被忽略的缺陷。
19、本发明通过对已知类别的样本数据进行处理获得哈希码存入检索库中,并通过已知类别的样本数据哈希码的获取方法进行拓展得到未知类别哈希码的获取方法,从而实现混合未知数据的数据检索。
20、本发明将成对相似性、语义标签和类别属性集成到一个框架中,以充分挖掘语义信息。具体将数据特征与类别属性相结合,以获得每个实例的类别表示向量。同时考虑成对相似矩阵和语义标签等监督信息,因此可以更好地捕捉已知类和未知类之间的关系,将监督知识从已知类转移到未知类,从而指导哈希码学习。克服了现有零样本哈希方法不能同时考虑成对相似性、类标签和类属性来训练模型的缺陷。
21、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于数据合成的大规模零样本数据检索方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于数据合成的大规模零样本数据检索方法,其特征在于,所述从属性矢量到视觉特征数据的目标函数由三项构成,第一项是引入一个语义空间从属性数据反推语义数据项;第二项是将语义空间作为中介反推得到视觉数据项;第三项是关于语义空间的正则化项。
3.如权利要求1所述的基于数据合成的大规模零样本数据检索方法,其特征在于,所述测试样本用于对训练得到的哈希码学习目标函数进行测试。
4.如权利要求3所述的基于数据合成的大规模零样本数据检索方法,其特征在于,所述训练样本中的已知类数据与检索集中的已知类数据不同。
5.如权利要求1所述的基于数据合成的大规模零样本数据检索方法,其特征在于,所述哈希码学习目标函数由五项构成:第一项是哈希码项;第二项是相似性保持项;第三项是标签矩阵嵌入项,第四项是属性空间学习项;第五项是正则化项。
6.一种基于数据合成的大规模零样本数据检索系统,其特征在于,包括:
7.如权利要求6所述的基于数据合成的大规模零样本数据检索系统,其特征在于,所述样本处理模块包括第一目标函数模块,所述第一目标函数模块用于构建从属性矢量到视觉特征数据的目标函数,从属性矢量到视觉特征数据的目标函数由三项构成,第一项是引入一个语义空间从属性数据反推语义数据项;第二项是将语义空间作为中介反推得到视觉数据项;第三项是关于语义空间的正则化项。
8.如权利要求6所述的基于数据合成的大规模零样本数据检索系统,其特征在于,所述样本处理模块包括测试样本模块和训练样本模块,所述测试样本模块用于采用测试样本对训练得到的哈希码学习目标函数进行测试。
9.如权利要求8所述的基于数据合成的大规模零样本数据检索系统,其特征在于,所述训练样本模块用于获取现有的已知类训练样本,对现有的已知类训练样本进行处理,其中,训练样本中的已知类数据与检索集中的已知类数据不同。
10.如权利要求6所述的基于数据合成的大规模零样本数据检索系统,其特征在于,所述样本处理模块包括第二目标函数模块,所述第二目标函数模块用于构建哈希码学习目标函数,哈希码学习目标函数由五项构成:第一项是哈希码项;第二项是相似性保持项;第三项是标签矩阵嵌入项,第四项是属性空间学习项;第五项是正则化项。
技术总结
本发明公开了一种基于数据合成的大规模零样本数据检索方法及系统,涉及信息检索技术领域。首先对仅有属性矢量,没有视觉特征数据的原始数据样本,获取其视觉特征数据对原始数据样本进行补充。利用哈希码学习方法通过训练样本训练得到对应的哈希码和哈希码学习目标函数,并存入检索数据库;对于待检索未知类样本,将其进行哈希码计算得到待检索未知类样本的哈希码;最后将待检索未知类样本的哈希码与检索数据库中的哈希码通过异或运算计算海明距离,得到检索结果。本发明克服了现有方法不考虑未知类样本的问题,并且考虑成对相似性、类标签和类属性来训练模型,实现了高效准确的大规模零样本数据检索。
技术研发人员:刘兴波,李雪茹,张雪凝,聂秀山,王少华,尹义龙
受保护的技术使用者:山东建筑大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!