多特征融合的双目标自监督医疗问题文本聚类方法及系统
本发明涉及一种文本处理,特别是关于一种多特征融合的双目标自监督医疗问题文本聚类方法及系统。
背景技术:
1、在许多实际应用中,短文本聚类是一项具有挑战性的重要任务。然而,许多基于词袋的短文本聚类方法往往受到文本表示稀疏性的限制,而基于神经网络词嵌入的方法无法捕捉文本语料库中的文档结构依赖性,同时传统文本聚类算法将文本表示与聚类过程分开计算,自监督学习(self-supervised learning)是无监督学习的一个特殊形式,自监督学习和无监督学习面向没有标注的数据。将聚类结果作为目标自监督训练引导深度网络学习到更好的表征,通过深度网络与聚类过程联合训练,学习到的高质量文本表征有助于提高聚类算法性能,提高聚类精度和网络的泛化能力,改变传统聚类框架中特征表示和聚类算法之间非端到端的本质。
2、医疗问答数据为非结构化的文本形式,且字符较短,用语不规范的特点,单一模型提取的特征往往不能充分表征文本内容,需要结合其他模型构建融合特征,丰富特征向量的语义信息,从而更好的进行文本表示。因此,如何使问题文本融合更多的信息,同时构建端对端的文本聚类模型,构建多特征融合的双目标自监督医疗问题文本聚类模型成为目前亟需解决的技术问题。
技术实现思路
1、针对上述问题,本发明的目的是提供一种多特征融合的双目标自监督医疗问题文本聚类方法及系统,其能有效提高问题文本的特征表示能力。
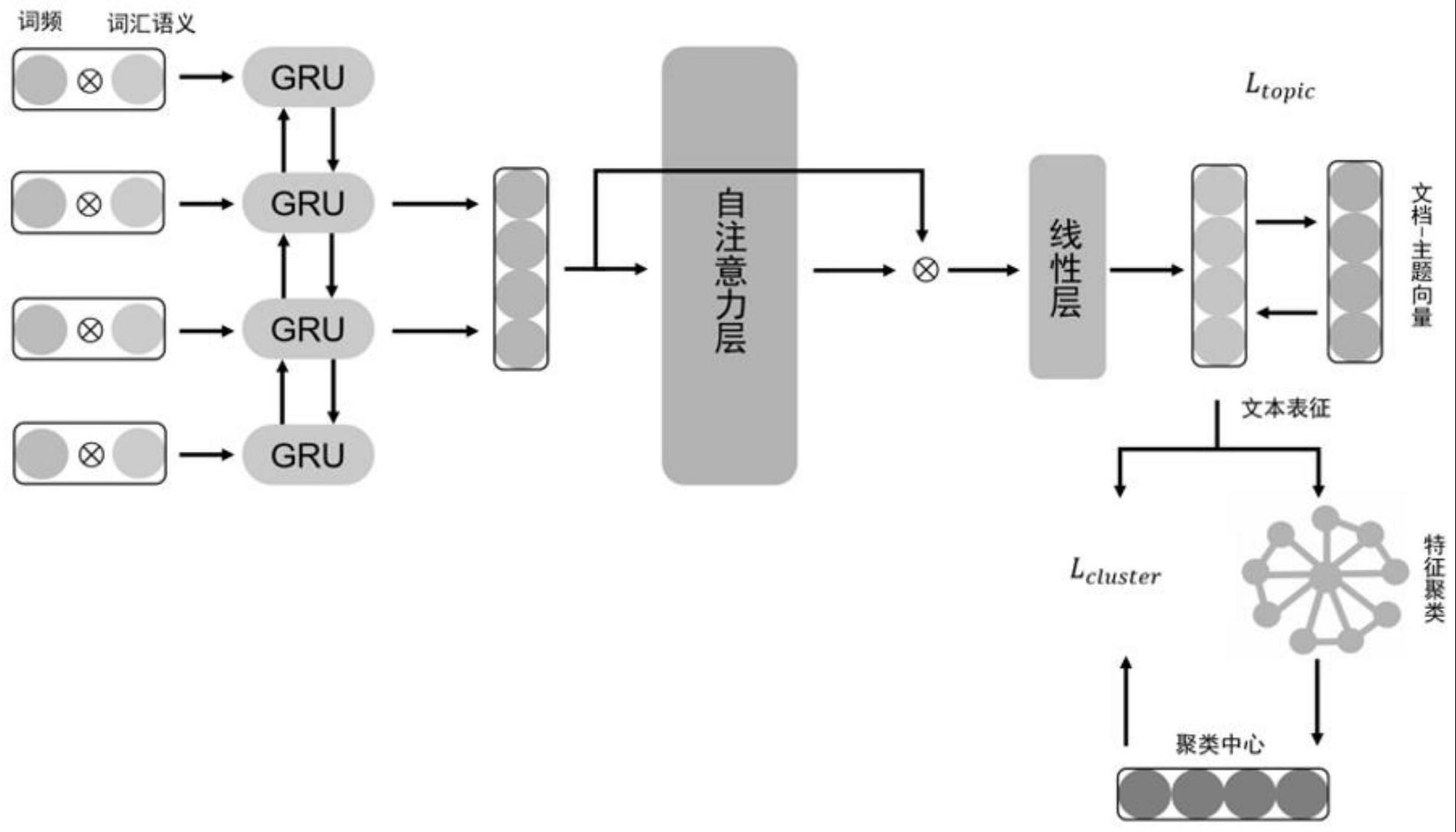
2、为实现上述目的,本发明采取以下技术方案:一种多特征融合的双目标自监督医疗问题文本聚类方法,其包括:提取医疗问题文本数据源中的词频信息和词汇语义信息,将词频信息和词汇语义信息融合得到加权词向量;将加权词向量作为bigru模型的输入,进行深度学习并引入自注意力机制,计算每个词语在医疗问题文本中的权重,得到词汇间的语义关系;基于词汇间的语义关系构建跨文档主题信息目标函数,并将聚类目标函数融合到学习表示的网络损失函数中,与跨文档主题信息目标函数构建联合损失函数,将文本表示和聚类结果融合到统一框架下,实现端对端的双目标自监督文本聚类。
3、进一步,将词频信息和词汇语义信息融合得到加权词向量,包括:
4、以词频-逆文本频率指数值tf-idf对快速文本分类器fasttext词汇语义加权,减少非关键词的特征影响,提高主题区分能力,得到医疗问题文本中词汇的权重特征;
5、将词汇语义特征与相应的tf-tdf值相乘,得到加权词向量。
6、进一步,在提取医疗问题文本数据源中的词频信息和词汇语义信息之前,还包括对医疗问题文本数据进行处理的步骤:
7、将医疗问题文本数据进行数据清洗,去除无意义噪声数据,同时对标点符号不用、乱用问题进行修正;
8、将进行数据清洗后的医疗问题文本数据进行分词,分词后进行类别标注。
9、进一步,将加权词向量作为bigru模型的输入,进行深度学习并引入自注意力机制,包括:
10、采用bigru作为非线性函数f1以获取长期依赖神经元信息,每个gru单元中设置有两个sigmoid门:复位门和更新门;通过双向结构获得单个问题文本中相邻单词之间的依赖关系;
11、在bigru基础上引入自注意机制,允许将句子的不同方面提取到多个向量表示中;在没有其他额外输入的情况下获取更多信息,并能直接访问所有时间下的隐藏表示。
12、进一步,多方面的自我注意机制,为:
13、
14、
15、式中,w1和w2是具有可学习参数的线性层,tanh作为激活层引入非线性变换,t为矩阵的转置,h作为gru的输出特征,而z则代表线性层输出特征;a为自注意力矩阵,exp代表指数函数,a中的每个值表示对于特征值与其他特征值的相关性;通过乘以注意力矩阵a和输入h得到基于自注意力机制增强的中间特征再通过一层线性投射层计算以获得输出特征。
16、进一步,跨文档主题信息目标函数,为:
17、
18、
19、式中,ltopic为跨文档主题信息目标函数,kl散度,dij∈d表示样本i属于主题j的概率,fij∈f为表示样本i属于主题j的概率,f为主题模型lda计算出的文本的文档-主题分布,下标i、j分别表示样本i,主题j;d为一种概率分布,d∈r1×r,其中r为文档-主题分布向量的长度,relu为线性修正激活函数,w1和w2是具有可学习参数的线性层。
20、进一步,联合损失函数为:
21、ltrain=αlcluster+ltopic
22、其中,ltrain为联合损失函数,lcluster为聚类目标函数,ltopic为跨文档主题信息目标函数,α为超参数。
23、一种多特征融合的双目标自监督医疗问题文本聚类系统,其包括:第一处理模块,提取医疗问题文本数据源中的词频信息和词汇语义信息,将词频信息和词汇语义信息融合得到加权词向量;第二处理模块,将加权词向量作为bigru模型的输入,进行深度学习并引入自注意力机制,计算每个词语在医疗问题文本中的权重,得到词汇间的语义关系;第三处理模块,基于词汇间的语义关系构建跨文档主题信息目标函数,并将聚类目标函数融合到学习表示的网络损失函数中,与跨文档主题信息目标函数构建联合损失函数,将文本表示和聚类结果融合到统一框架下,实现端对端的双目标自监督文本聚类。
24、一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行上述方法中的任一方法。
25、一种计算设备,其包括:一个或多个处理器、存储器及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为所述一个或多个处理器执行,所述一个或多个程序包括用于执行如上述方法中的任一方法的指令。
26、本发明由于采取以上技术方案,其具有以下优点:
27、本发明为学习融合跨文档主题特征同时构建端对端的文本聚类模型,构建两个目标函数,融合到统一聚类框架下,学习有利于文本聚类的友好表示。解决了目前文本聚类算法将文本表示与聚类过程分开,以及医疗问题文本本身字符少,特征稀疏的问题。
技术特征:
1.一种多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,包括:
2.如权利要求1所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,将词频信息和词汇语义信息融合得到加权词向量,包括:
3.如权利要求1所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,在提取医疗问题文本数据源中的词频信息和词汇语义信息之前,还包括对医疗问题文本数据进行处理的步骤:
4.如权利要求1所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,将加权词向量作为bigru模型的输入,进行深度学习并引入自注意力机制,包括:
5.如权利要求4所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,多方面的自我注意机制,为:
6.如权利要求1所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,跨文档主题信息目标函数,为:
7.如权利要求1所述多特征融合的双目标自监督医疗问题文本聚类方法,其特征在于,联合损失函数为:
8.一种多特征融合的双目标自监督医疗问题文本聚类系统,其特征在于,包括:
9.一种存储一个或多个程序的计算机可读存储介质,其特征在于,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行如权利要求1至7所述方法中的任一方法。
10.一种计算设备,其特征在于,包括:一个或多个处理器、存储器及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为所述一个或多个处理器执行,所述一个或多个程序包括用于执行如权利要求1至7所述方法中的任一方法的指令。
技术总结
本发明涉及一种多特征融合的双目标自监督医疗问题文本聚类方法及系统,其包括:提取医疗问题文本数据源中的词频信息和词汇语义信息,将词频信息和词汇语义信息融合得到加权词向量;将加权词向量作为BiGRU模型的输入,进行深度学习并引入自注意力机制,计算每个词语在医疗问题文本中的权重,得到词汇间的语义关系;基于词汇间的语义关系构建跨文档主题信息目标函数,并将聚类目标函数融合到学习表示的网络损失函数中,与跨文档主题信息目标函数构建联合损失函数,将文本表示和聚类结果融合到统一框架下,实现端对端的双目标自监督文本聚类。本发明能有效提高问题文本的特征表示能力。
技术研发人员:高东平,申喜凤,秦奕,南嘉乐,张维宁,车美龄
受保护的技术使用者:中国医学科学院医学信息研究所
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!