一种基于事实和情感对立性的多模态反讽检测方法
本发明属于自然语言处理和计算机视觉处理,特别是涉及一种基于事实和情感对立性的多模态反讽情感检测的方法。
背景技术:
1、讽刺是一种有趣且流行的表达用户观点的方式,通常情况下意味着表达出的真实态度与字面的意思相反。由于社交媒体的发展,图文多模态数据成为了用户表达讽刺的主流方法,讽刺检测(sarcasm detection,sd)在产品评价分析、意见挖掘等应用中具有重要的作用。
2、在早期阶段,研究人员主要研究由文本数据引起的讽刺。由于推特等网络数据往往包含类别标签,使用这些标签建立了一个自然语言的讽刺语料库。根据构建的讽刺语料库信息,研究者们探索了利用讽刺语料库对文本数据进行讽刺的检测以及文本意见,情感的挖掘等相关任务。
3、由于图像-文本多模态数据的普及,多模态讽刺检测(multi-modal sarcasmdetection,msd)近年来受到越来越多的关注。与单模态讽刺检测不同,挖掘模态之间的关系是多模态讽刺检测的关键问题。相对较早期的一些研究者通过分析图像和文本的手工特征以及深度表示,采用特征拼接的方法进行多模态预测。后来,基于注意力机制的模态融合方法成为多模态讽刺检测的主要研究方向,例如利用多层次融合策略来深度融合图文表征。受到自注意力模型(transformer)取得重大成功的影响,跨模态的自注意力模块被用来发现图文模态之间的相关程度。为了更好的利用每个实例的图像和文本之间的映射关系,许多研究者关注于基于图网络的建模方法。通过进一步利用视觉问答算法(visionquestion answering,vqa)输出图像中的各个物体的边界框进行跨模态的细粒度匹配,并构建跨模态的图网络以掌握多模态之间的讽刺相关交互信息。
4、现有技术方法通过模态间交互的方式隐式的建模模态间的不一致性,但其中不一致性确切学到的知识是未知的。
技术实现思路
1、基于上述现有技术以及受人类感知过程的启发,本发明提出了一种基于事实和情感对立性的多模态反讽检测方法,基于双重网络感知结构实现了从事实和情感两个方面显式挖掘讽刺数据中的语义不一致性,从而实现了多模态的反讽情感检测方法。
2、为了达成上述发明目的,本发明采取了以下的技术方案:
3、一种基于事实和情感对立性的多模态反讽检测方法,该系统包含以下步骤
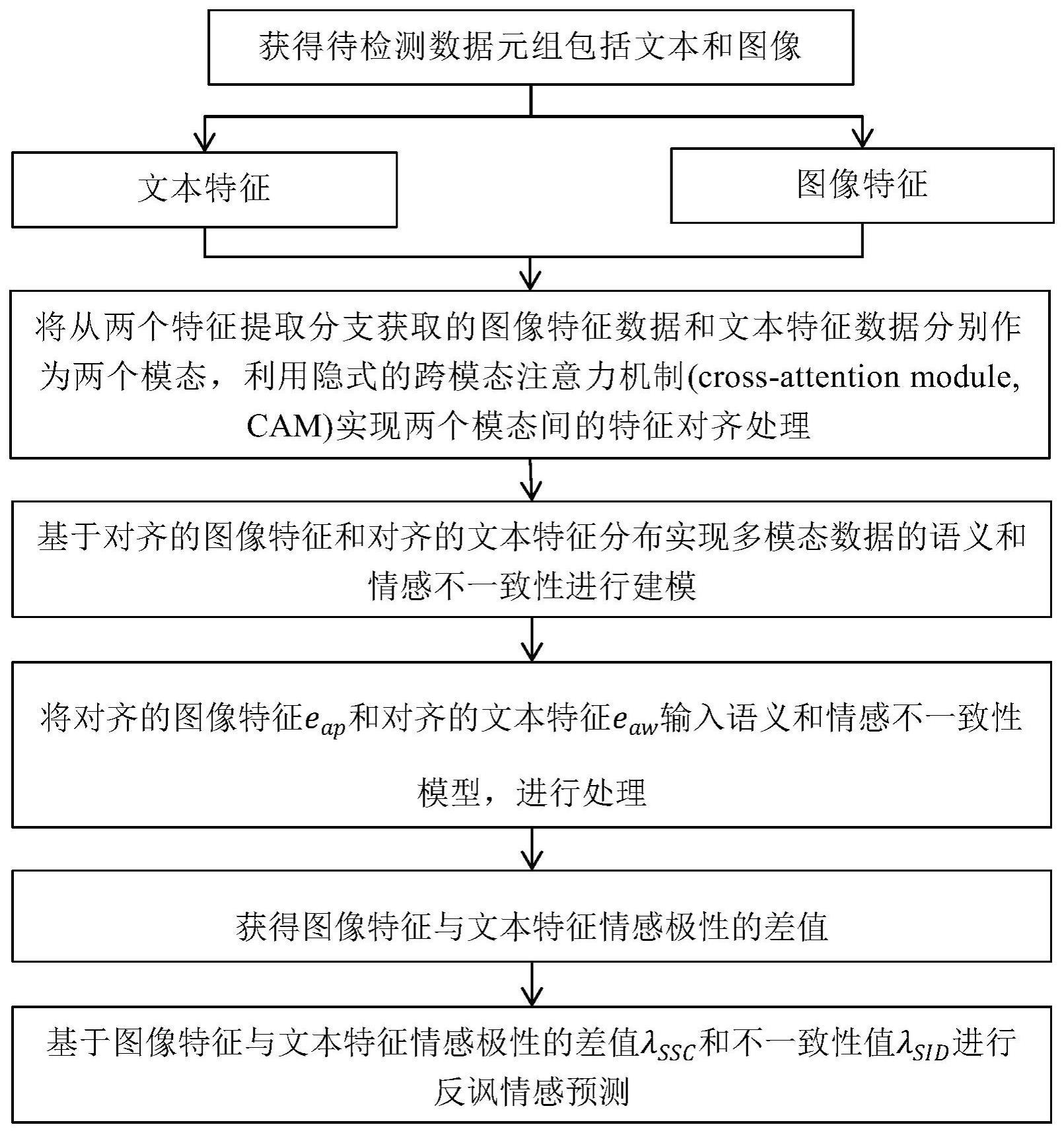
4、步骤1、获得待检测数据元组,包括文本和图像,通过两个特征提取分支获得图像特征数据和文本特征数据;
5、步骤2、将从步骤1获得的图像特征数据和文本特征数据分别作为两个模态,利用隐式的跨模态注意力机制实现两个模态间的特征对齐处理,得到对齐的图像特征和对齐的文本特征,继而归并到同一特征空间;
6、步骤3、基于步骤2中对齐的图像特征和对齐的文本特征分布实现多模态数据的语义和情感不一致性建模;
7、步骤4、将对齐的图像特征和对齐的文本特征输入步骤3的语义不一致性模型,通过该模型进行处理,获得增强后的讽刺图像特征和增强后的讽刺文本特征,对所获得的所述增强后的图像特征和所述增强后的文本特征的相似性分别计算其属于讽刺数据高斯分布与非讽刺数据高斯分布的概率,计算语义不一致性;
8、步骤5、从情感词典引入情感信息,通过连续对比学习进一步增强图像情感特征,获得图像特征与文本特征情感极性的差值作为情感不一致性;
9、步骤6、基于步骤4和步骤5的图像特征与文本特征语义和情感极性的差值和不一致性值进行反讽情感检测,得到检测结果。
10、与现有技术相比,本发明能够达成以下有益技术效果:
11、1)利用多模态数据中事实和情感的对立性,通过对不一致性的显示建模构建了双重感知网络来对多模态反讽数据进行检测;
12、2)提出了针对事实语义不一致性的通道加权修正方法,增强了讽刺相关的图文特征。通过对讽刺以及非讽刺数据进行高斯建模并计算样本与两个分布的距离,自适应的计算出事实的不一致性;
13、3)通过情感词典引入缺乏标注的情感信息,提出情感连续对比学习的方法对图像情感特征进行进一步增强。使用图文情感的极性差值显示的建模情感对立性。
14、4)在预测阶段,将多模态图文数据分别送入两个模块中,利用输出特征进行融合后判断是否为反讽;
15、5)多模态反讽检测数据集上表现出了优秀的预测性能,超过了所有现有的方法。对于给定图像,本发明可以精确对是否属于讽刺情感类别进行检测。
技术特征:
1.一种基于事实和情感对立性的多模态反讽检测方法,该方法具体包括以下步骤:
2.如权利要求1所述的一种基于事实和情感对立性的多模态反讽检测方法,其特征在于,其中步骤2中,跨模态注意力机制进一步包括以下处理:
3.如权利要求1所述的一种基于事实和情感对立性的多模态反讽检测方法,其特征在于,其中所述步骤4进一步包括以下处理:
4.如权利要求3所述的一种基于事实和情感对立性的多模态反讽检测方法,其特征在于,所述步骤5进一步包括以下处理:
5.如权利要求4所述的一种基于事实和情感对立性的多模态反讽检测方法,其特征在于,所述步骤6中,所述检测结果y的表达式如下:
技术总结
本发明公开了一种基于事实和情感对立性的多模态反讽检测方法,步骤1、获得待检测数据元组包括文本和图像,通过两个特征提取分支获得图像特征数据和文本特征数据;步骤2、利用隐式的跨模态注意力机制实现特征对齐处理;步骤3、实现多模态数据的语义和情感不一致性建模;步骤4、计算语义不一致性;步骤5、获得图像特征与文本特征情感极性的差值;步骤6、基于图像特征与文本特征情感极性的差值和不一致性值进行反讽检测,得到检测结果。与现有技术相比,本发明在利用多模态反讽检测数据集上表现出了优秀的预测性能,超过了所有现有的方法。本发明可以精确对给定图像是否属于讽刺情感类别进行检测。
技术研发人员:杨巨峰,文长崧,贾国力
受保护的技术使用者:南开大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!