自然语言处理系统以及方法与流程
本发明涉及自然语言处理,本发明一般而言是有关于一种自然语言处理系统以及方法,更具体而言是有关于一种使用信艾普模型单元(synapper model unit)的自然语言处理系统以及方法。
背景技术:
1、使用包括自然语言分析(natural language analysis)、自然语言理解(naturallanguage understanding)、自然语言产生(natural language generation)及类似操作的基本技术实行自然语言处理,并将自然语言处理应用于包括信息检索、机器翻译、问与答(questions&answers,q&a)及类似情境的各种领域。
2、使用典型自然语言处理方法的机器翻译可能产生不准确或不可理解的句子。
3、为了使自然语言处理更正确,可施行各种自然语言处理过程,且自然语言处理可采用自然语言分析、自然语言理解、自然语言产生及类似操作。
4、自然语言分析是一种对自然语言的含义进行分析的技术,自然语言理解是一种允许计算机因应于以自然语言呈现的输入数据进行操作的技术,且自然语言产生是一种将视讯或显示内容转换成人类可理解的自然语言的技术。
5、近年来,自然语言处理采用神经网络模型(neural network model)。
6、尽管在自然语言处理中语义解析的效能有所改善,但神经网络模型可能不会提供高精度且在源数据少时会由不一致的操作驱动的技术问题。另外,由于神经网络模型需要非常快的计算机效能及巨大的功耗的技术问题,因此存在若干实际困难。
7、[相关参考文献]
8、[专利文档]
9、韩国专利公开出版物第10-2022-0049693号(2022年4月22日)
技术实现思路
1、本发明的一个目的是提供一种自然语言处理系统以及方法,以解决上述技术问题。
2、本发明不限于上述目的,且本发明的其他目的将自下面的说明变得显而易见。
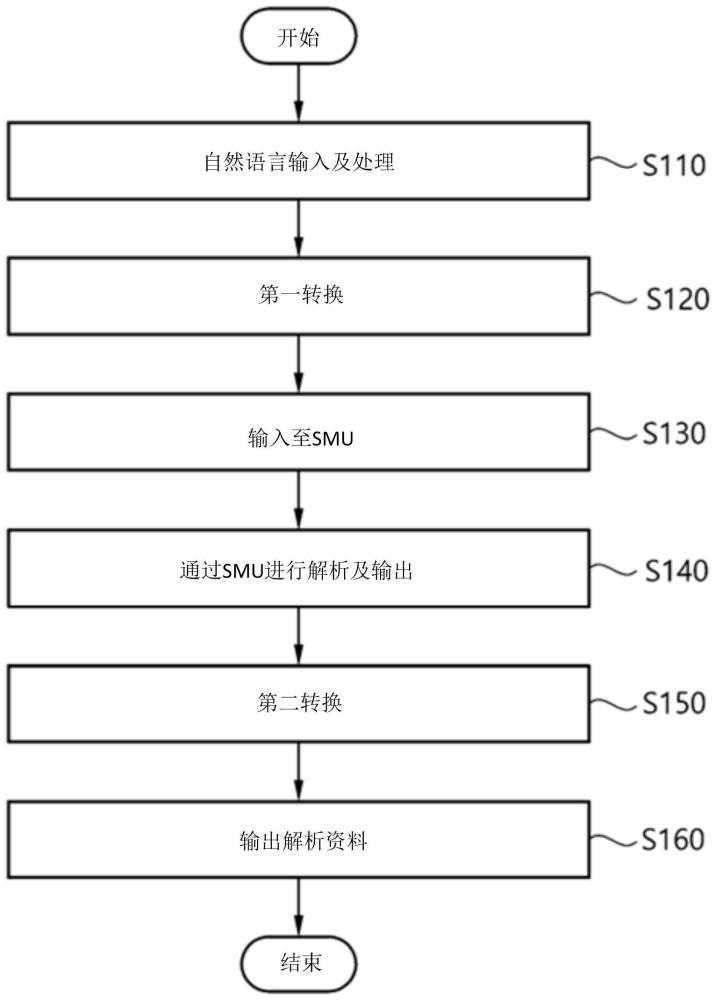
3、第一方面,本发明提供了一种使用信艾普模型单元的自然语言处理方法包括:预处理步骤,其中接收以自然语言书写或发音的文本并将所述文本转换成由单词构成的句子;第一转换步骤,其中通过第一代码转换器(wnc)将在所述预处理步骤中转换的所述句子的所述单词中的每一者转换成神经概念代码;信艾普模型输入步骤,其中将在所述第一转换步骤中转换的所述神经概念代码输入至语言处理单元的信艾普模型;解析/输出步骤,其中解析并输出通过所述语言处理单元的所述信艾普模型辨识出的所述神经概念代码;第二转换步骤,其中通过第二代码转换器(nwc)将由所述语言处理单元解析并自所述语言处理单元输出的所述神经概念代码转换成单词;以及解析数据输出步骤,其中将在所述第二转换步骤中转换的数据作为解析数据输出。
4、在一些实施例中,所述第一转换步骤包括将输入的所述单词转换成二进制/十进制数代码。
5、在一些实施例中,在所述第一转换步骤中,所述十进制数代码的前两个数字代表将输入的所述单词转换成所述神经概念代码时的词性(part-of-speech)。
6、在一些实施例中,在所述解析/输出步骤中,对缓存器集合中的每一神经概念代码(neural concept code,ncc)的所述词性进行解析以确定所述句子的正确解释。
7、在一些实施例中,在所述解析/输出步骤中,当所述句子的所有单词在所述第一转换步骤中被转换成所述神经概念代码(ncc)时,确定所述句子的句法结构并在所述信艾普模型中对所述句子的所述句法结构进行解析,以作为经解析的神经概念代码(ncc)输出。
8、在一些实施例中,在所述解析/输出步骤中,在输出所述数据之前,高速缓冲存储器临时储存通过所述信艾普模型解析的数据。
9、在一些实施例中,在所述解析/输出步骤中,文本随机存取内存(text randomaccess memory,tram)储存信艾普模型数据,以允许对所述高速缓冲存储器中难以处理的大量句子进行存取。
10、在一些实施例中,在所述解析/输出步骤中,包括闪存的储存装置储存包含重要信息的句子,以允许稍后对所述句子进行存取。
11、在一些实施例中,在所述解析/输出步骤中,所述信艾普模型将所述文本划分成句子,每一句子由单词构成且以自然语言的各种方式表达,并且基于所述句子中每一单词的词性及与其相邻的单词来确定所述单词中的哪些单词是分支及所述单词中的哪些单词是节点。
12、在一些实施例中,在所述解析/输出步骤中,在确定所述节点及所述分支的后,所述信艾普模型在第一方向上将所述节点彼此连接,同时在不同于所述第一方向的方向上将所述分支连接至对应的所述节点。
13、第二方面,本发明提供了一种使用信艾普模型单元的自然语言处理系统包括:输入单元,输入自然语言;模拟数字转换器(analog-to-digital converter,adc),将输入至所述输入单元的模拟数据转换成数字数据;第一代码转换器(wnc),将所述数字数据转换成神经概念代码;语言处理单元,自所述第一代码转换器(wnc)接收所述神经概念代码,以通过信艾普模型解析并输出所述神经概念代码;第二代码转换器(nwc),将自所述语言处理单元输出的经解析的所述神经概念代码转换成经解析的单词数据;数字模拟转换器(digital-to-analog converter,dac),将通过所述第二代码转换器(nwc)转换的所述经解析的单词数据转换成模拟数据;以及输出单元,输出通过所述数字模拟转换器(dac)转换的所述模拟数据,以提供自然语言的解析数据。
14、根据本发明,所述系统及方法在使用信艾普模型单元进行自然语言处理时即使不存在巨量资料亦能够以非常快的速度以高精度及一致性进行自然语言处理。本发明提供的自然语言处理系统以及方法,其使用信艾普模型单元即使在不存在巨量数据(big data)的情况下亦能够以非常快的速度以高精度及一致性进行自然语言处理。
技术特征:
1.一种自然语言处理方法,其特征在于,包括:
2.如权利要求1所述的自然语言处理方法,其特征在于,所述第一转换步骤包括将输入的所述单词转换成二进制数代码或/以及十进制数代码。
3.如权利要求2所述的自然语言处理方法,其特征在于,在所述第一转换步骤中,所述十进制数代码的前两个数字代表将输入的所述单词转换成所述神经概念代码时的词性。
4.如权利要求1所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,对缓存器集合中的每一神经概念代码的词性进行解析以确定所述句子的正确解释。
5.如权利要求1所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,当所述句子的所有单词在所述第一转换步骤中被转换成所述神经概念代码时,确定所述句子的句法结构并在所述信艾普模型中对所述句子的所述句法结构进行解析,以作为经解析的神经概念代码输出。
6.如权利要求1所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,在输出所述数据之前,高速缓冲存储器临时储存通过所述信艾普模型解析的数据。
7.如权利要求6所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,文本随机存取内存储存信艾普模型数据,以允许对所述高速缓冲存储器中难以处理的大量句子进行存取。
8.如权利要求7所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,闪存储存包含重要信息的句子,以允许稍后对所述句子进行存取。
9.如权利要求1所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,所述信艾普模型将所述文本划分成句子,每一句子由单词构成且以自然语言的各种方式表达,并且基于所述句子中每一单词的词性及与其相邻的单词来确定所述单词中的哪些单词是分支及所述单词中的哪些单词是节点。
10.如权利要求9所述的自然语言处理方法,其特征在于,在所述解析/输出步骤中,在确定所述节点及所述分支之后,所述信艾普模型在第一方向上将所述节点彼此连接,同时在不同于所述第一方向的方向上将所述分支连接至对应的所述节点。
11.一种自然语言处理系统,其特征在于,包括:
技术总结
本发明涉及自然语言处理技术领域,特别涉及一种自然语言处理系统以及方法,包括:预处理步骤,其中接收以自然语言书写或发音的文本并将文本转换成由单词构成的句子;第一转换步骤,其中通过第一代码转换器将在预处理步骤中转换的句子的单词中的每一者转换成神经概念代码;信艾普模型输入步骤,其中将在第一转换步骤中转换的神经概念代码输入至语言处理单元的信艾普模型;解析/输出步骤,其中解析并输出通过语言处理单元的信艾普模型辨识出的神经概念代码;第二转换步骤,其中通过第二代码转换器将由语言处理单元解析并自语言处理单元输出的神经概念代码转换成单词;以及解析数据输出步骤,其中将在第二转换步骤中转换的数据作为解析数据输出。
技术研发人员:金敏九
受保护的技术使用者:金敏九
技术研发日:
技术公布日:2024/2/6
- 还没有人留言评论。精彩留言会获得点赞!