一种基于TF-IDF和LDA主题模型的语料集分类方法
本发明涉及语料集的分类,特别是涉及一种基于tf-idf和lda主题模型的语料集分类方法。
背景技术:
1、在当今全球化、信息化的背景下,工程科技的发展水平体现着一国的核心竞争力。在国外相关研究中,支持个性化学习的技术主要有数据挖掘技术、协同过滤技术、遗传算法及聚类算法。基于层次分析法(ahp)定量计算支撑课程与毕业要求的目标权重值,最终确定达成度评价的综合得分,研究期望为毕业要求达成度评价提供新的定量评价机制,然而其缺少与学生的互动交流,忽视了学生的主观能动性和专业应用领域的创新能力。
2、这种情况下就需要社会各方面提供相应的意见或建议,但是大量的语料数据获取后,很难有效地实现关键信息的提取和分类,来获取相应的关键信息。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于tf-idf和lda主题模型的语料集分类方法,基于tf-idf算法和lda主题模型对于语料信息进行主题分类,配合用户词典、停用词文档和近义词表等使用jieba库进行文本分词,具有良好的主题分类能力,为关键信息的获取提供了有效条件。
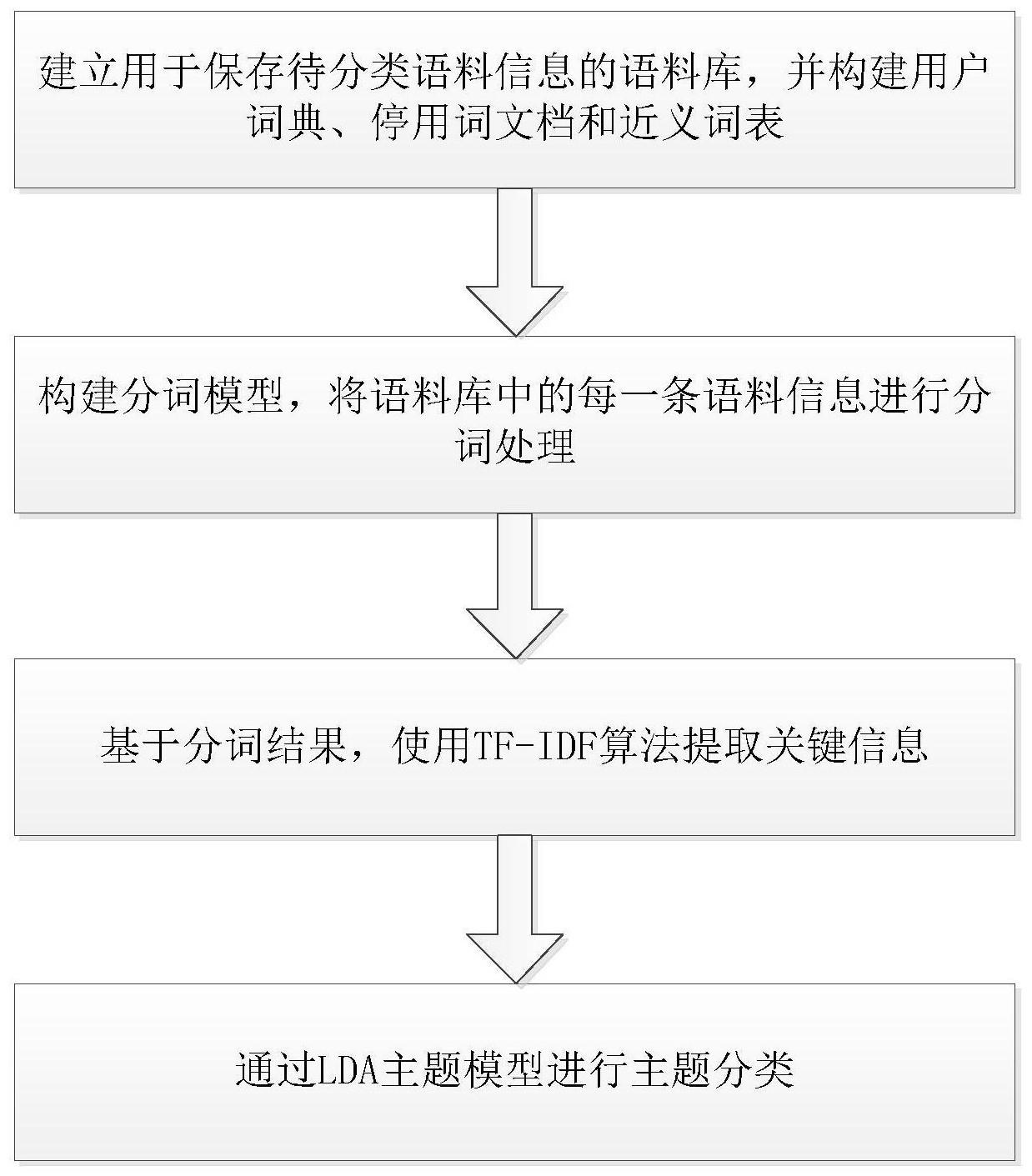
2、本发明的目的是通过以下技术方案来实现的:一种基于tf-idf和lda主题模型的语料集分类方法,包括以下步骤:
3、s1.建立用于保存待分类语料信息的语料库,并构建用户词典、停用词文档和近义词表;
4、s2.构建分词模型,将语料库中的每一条语料信息进行分词处理;
5、s3.基于分词处理结果,使用tf-idf算法提取关键信息;
6、s4.通过lda主题模型进行主题分类。
7、本发明的有益效果是:本发明基于tf-idf算法和lda主题模型对于语料信息进行主题分类,配合用户词典、停用词文档和近义词表等使用jieba库进行文本分词,具有良好的主题分类能力,为关键信息的获取提供了有效条件。
技术特征:
1.一种基于tf-idf和lda主题模型的语料集分类方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的一种基于tf-idf和lda主题模型的语料集分类方法,其特征在于:所述步骤s1包括:
3.根据权利要求1所述的一种基于tf-idf和lda主题模型的语料集分类方法,其特征在于:所述步骤s2包括:
4.根据权利要求1所述的一种基于tf-idf和lda主题模型的语料集分类方法,其特征在于:所述步骤s3中,需要计算每一条语料信息重点词的tf-idf权值,具体计算步骤如下:
5.根据权利要求1所述的一种基于tf-idf和lda主题模型的语料集分类方法,其特征在于:所述步骤s4中利用lda主题模型进行分类时,需要首先为lda主题模型定义多种主题,然后将所有语料信息的关键词输出lda主题模型中,由lda主题模型将各个关键词划分到不同的主题下。
技术总结
本发明公开了一种基于TF‑IDF和LDA主题模型的语料集分类方法,包括以下步骤:S1.建立用于保存待分类语料信息的语料库,并构建用户词典、停用词文档和近义词表;S2.构建分词模型,将语料库中的每一条语料信息进行分词处理;S3.基于分词处理结果,使用TF‑IDF算法提取关键信息;S4.通过LDA主题模型进行主题分类。本发明基于TF‑IDF算法和LDA主题模型对于语料信息进行主题分类,配合用户词典、停用词文档和近义词表等使用jieba库进行文本分词,具有良好的主题分类能力,为关键信息的获取提供了有效条件。
技术研发人员:贺航飞,李军,兰晓青,兰晓倩,张代科,黄云,卫泽东,杨倩
受保护的技术使用者:四川农业大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!