一种基于经典读唇的视频人像读唇分析方法
本发明涉及计算机视觉和侦查,具体涉及一种基于经典读唇的视频人像读唇分析方法。
背景技术:
1、视频中语音缺失的情况十分常见,而缺少了语音这一关键信息的视频无法直接用于执法监督、法律诉讼、新闻报道等场景当中。更有甚者,缺少语音的视频可能会被歪曲本意,恶意传播,从而引发严重的舆情风险,造成不良的社会影响。因此,增强读唇分析方法的准确性,能够有效拓展证据获取渠道,维护社会和谐稳定,具有重要的研究意义与迫切的实际需求。
2、目前读唇分析的方法主要包括两类,其一是利用嘴部图像提取传统的视觉特征,利用特征比对或机器学习进行分析;其二是利用深度学习技术,利用深度网络对嘴部图像进行端到端的学习分析。前者特征提取的能力有限,往往对视频拍摄的质量有较高的要求,在实际应用中受到限制。后者虽然可以通过利用大规模样本进行训练来提高特征提取能力,从而应对各种条件下的读唇分析,但在实际应用中往往难以获得符合需求的大规模样本数据,而缺乏训练数据也大大限制了深度网络模型的读唇分析能力。
3、由于现有的读唇分析方法具有上述局限性,难以在实际中有效使用,尤其对于执法流程监督、法律诉讼证据等特定应用场景,已有方法的使用成功率仍十分有限。这表明读唇分析技术在实际应用当中仍然充满了挑战。
技术实现思路
1、为了解决现有读唇分析技术中的缺陷,本发明提供了一种基于经典读唇的视频人像读唇分析方法。该方法针对特定的应用需求,通过将检材视频与已知所说语句的样本视频进行特征提取与匹配,能有效判断出检材视频中人物所说语句是否与样本视频一致,从而为流程审查、案件诉讼等应用提供有力的证据支持。
2、本发明的目的可以通过采取如下技术方案达到:
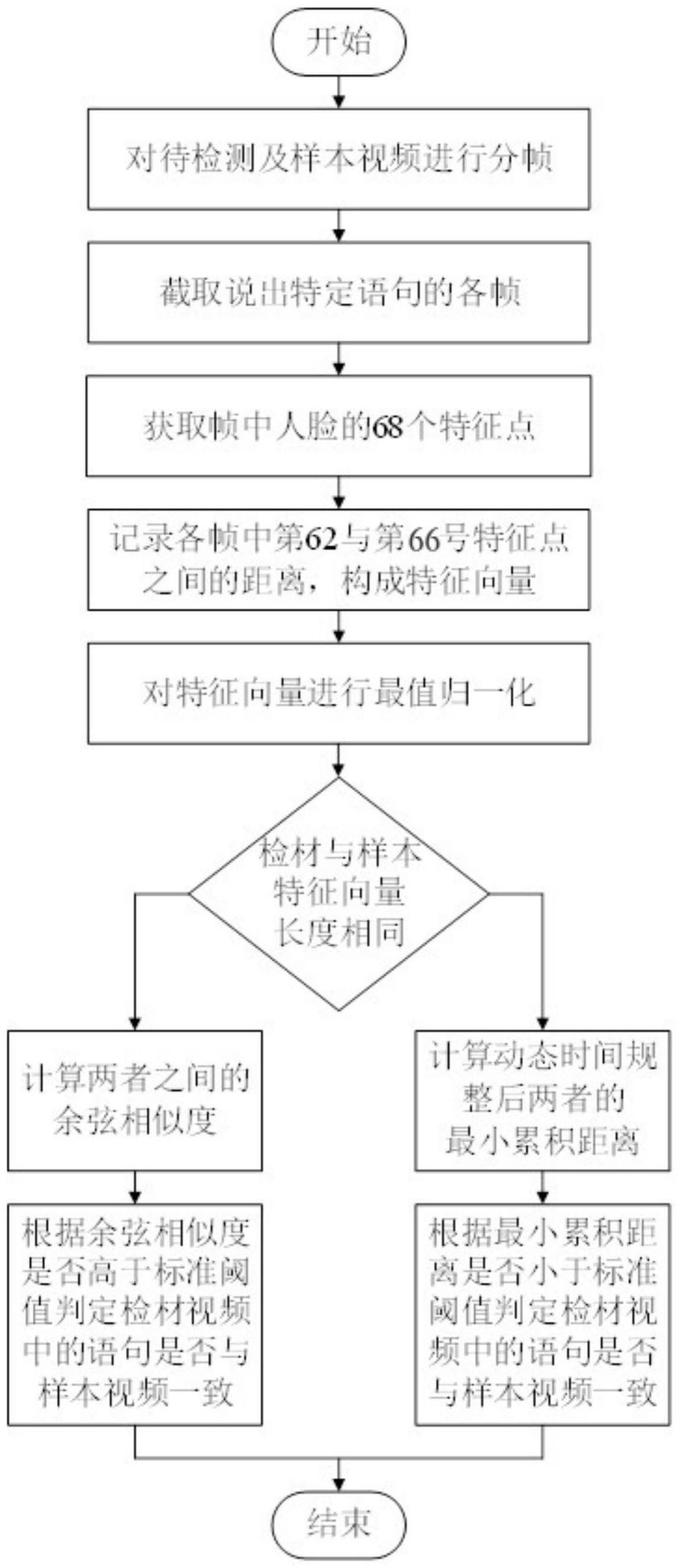
3、一种基于经典读唇的视频人像读唇分析方法,其特征在于,包括以下步骤:
4、s1、对检材视频及样本视频均进行分帧,截取样本视频中说出特定语句的各帧,以及检材视频中说出需检验语句的各帧,将样本视频中截取的各帧分别记为其中n为样本视频截取的总帧数,将检材视频中截取的各帧分别记为其中m为检材视频截取的总帧数;
5、s2、利用人脸关键点检测方法,对每帧当中人脸的68个关键特征点进行检测定位;
6、s3、记录各帧中第62与第66号特征点之间的距离,构成两个特征向量,其中样本对应的特征向量为a=(a1,a2,…,an),检材对应的特征向量为b=(b1,b2,…,bm);
7、s4、对特征向量a与b分别进行最值归一化,对于特征向量a,归一化后第i个元素为:
8、
9、其中ai表示特征向量a原本的第i个元素,amin表示特征向量a原本元素中的最小值,amax表示特征向量a原本元素中的最大值,得到样本视频归一化后的特征向量a*,并以同样的方法得到检材视频归一化后的特征向量b*;
10、s5、若样本与检材特征向量的维度相同,即n=m,则计算两个归一化特征向量之间的余弦相似度s:
11、
12、若s高于标准阈值,则判定检材视频中的语句与样本视频一致,否则判定两者不一致;
13、s6、若样本与检材特征向量的维度不同,即n≠m,则计算动态时间规整后的两者最小累积距离∑d,若∑d小于标准阈值,则判定检材视频中的语句与样本视频一致,否则判定两者不一致。
14、作为优选的技术方案,所述s2步骤中,使用卷积专家约束局部模型(convolutional experts constrained local model,ce-clm)进行人脸68个关键特征点的检测定位。
15、作为优选的技术方案,所述s5步骤中,余弦相似度的标准阈值为0.9469。
16、作为优选的技术方案,所述s6步骤中,动态时间规整后最小累积距离的标准阈值为1.9085。
17、本发明相对于现有技术具有如下的优点及效果:
18、1、本发明提供了一种基于经典读唇的视频人像读唇分析方法,通过对检材和样本视频进行成对分析,解决实际应用当中视频质量不高,训练样本不足的问题。
19、2、本发明对于检材与样本视频长度相同和不同的情况均可有效处理,适用范围广泛。
20、3、本发明计算简便,运算复杂度较低,所需资源较小,有效提高了该方法的应用效率。
技术特征:
1.一种基于经典读唇的视频人像读唇分析方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于经典读唇的视频人像读唇分析方法,其特征在于,所述s2步骤中,使用卷积专家约束局部模型(convolutional experts constrained localmodel,ce-clm)进行人脸68个关键特征点的检测定位。
3.根据权利要求1所述的一种基于经典读唇的视频人像读唇分析方法,其特征在于,所述s5步骤中,余弦相似度的标准阈值为0.9469。
4.根据权利要求1所述的一种基于经典读唇的视频人像读唇分析方法,其特征在于,所述s6步骤中,动态时间规整后最小累积距离的标准阈值为1.9085。
技术总结
本发明公开了一种基于经典读唇的视频人像读唇分析方法,主要步骤如下:对检材视频及样本视频均进行分帧,截取样本视频中说出特定语句的各帧,以及检材视频中说出需检验语句的各帧;对各帧中的人脸进行关键特征点提取,获取68个特征点;记录各帧中第62与第66号特征点之间的距离,构成两个特征向量;对两个特征向量分别进行最值归一化;若两特征向量长度相同,计算两者之间的余弦相似度,根据余弦相似度是否高于标准阈值判定检材视频中的语句是否与样本视频一致;若两特征向量长度不同,计算动态时间规整后两者的最小累积距离,根据最小累积距离是否小于标准阈值判定检材视频中的语句是否与样本视频一致。
技术研发人员:廖广军,王宇飞,王爽
受保护的技术使用者:广东警官学院(广东省公安司法管理干部学院)
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!