基于训练数据的数据量训练预训练语言模型的方法及装置与流程
本申请涉及机器学习,尤其涉及一种基于训练数据的数据量训练预训练语言模型的方法及装置。
背景技术:
1、近年来,随着机器学习技术的发展,越来越多的大规模模型得以应用于文本处理领域。为了保证大规模模型符合要求并且提高模型的训练效率,目前常见的是对已经预训练好的大规模模型进行进一步训练。即使是在预训练好的大规模模型的基础上进一步训练,同样存在优化参数量较大和耗时长的问题,同时,在训练样本数量较少的情况下极容易出现模型过拟合现象。
技术实现思路
1、有鉴于此,本申请实施例提供了一种基于训练数据的数据量训练预训练语言模型的方法、装置、电子设备及计算机可读存储介质,以解决现有技术中,对预训练模型的进一步训练仍然存在优化参数量较大和耗时长,以及在训练样本数量较少的情况下易出现模型过拟合的问题。
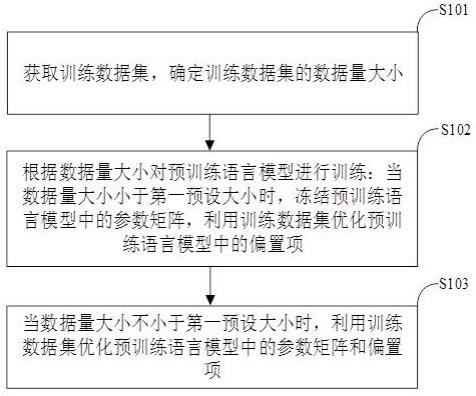
2、本申请实施例的第一方面,提供了一种基于训练数据的数据量训练预训练语言模型的方法,包括:获取训练数据集,确定训练数据集的数据量大小;根据数据量大小对预训练语言模型进行训练:当数据量大小小于第一预设大小时,冻结预训练语言模型中的参数矩阵,利用训练数据集优化预训练语言模型中的偏置项,其中,预训练语言模型中的可训练参数,包括:参数矩阵和偏置项;当数据量大小不小于第一预设大小时,利用训练数据集优化预训练语言模型中的参数矩阵和偏置项。
3、本申请实施例的第二方面,提供了一种基于训练数据的数据量训练预训练语言模型的装置,包括:确定模块,被配置为获取训练数据集,确定训练数据集的数据量大小;第一训练模块,被配置为根据数据量大小对预训练语言模型进行训练:当数据量大小小于第一预设大小时,冻结预训练语言模型中的参数矩阵,利用训练数据集优化预训练语言模型中的偏置项,其中,预训练语言模型中的可训练参数,包括:参数矩阵和偏置项;第二训练模块,被配置为当数据量大小不小于第一预设大小时,利用训练数据集优化预训练语言模型中的参数矩阵和偏置项。
4、本申请实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并且可在处理器上运行的计算机程序,该处理器执行计算机程序时实现上述方法的步骤。
5、本申请实施例的第四方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
6、本申请实施例与现有技术相比存在的有益效果是:因为本申请实施例通过获取训练数据集,确定训练数据集的数据量大小;根据数据量大小对预训练语言模型进行训练:当数据量大小小于第一预设大小时,冻结预训练语言模型中的参数矩阵,利用训练数据集优化预训练语言模型中的偏置项,其中,预训练语言模型中的可训练参数,包括:参数矩阵和偏置项;当数据量大小不小于第一预设大小时,利用训练数据集优化预训练语言模型中的参数矩阵和偏置项,因此,采用上述技术手段,可以解决现有技术中,对预训练模型的进一步训练仍然存在优化参数量较大和耗时长,以及在训练样本数量较少的情况下易出现模型过拟合的问题,进而减少优化的参数量和训练耗时,避免在训练样本数量较少时出现模型过拟合。
7、
技术特征:
1.一种基于训练数据的数据量训练预训练语言模型的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,根据所述数据量大小对预训练语言模型进行训练之前,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,根据所述数据量大小对预训练语言模型进行训练,包括:
4.根据权利要求3所述的方法,其特征在于,所述方法还包括:
5.根据权利要求4所述的方法,其特征在于,根据所述第一训练数据集对所述预训练语言模型进行第一阶段训练,根据所述第二训练数据集进行第二阶段训练,包括:
6.根据权利要求1所述的方法,其特征在于,根据所述数据量大小对预训练语言模型进行训练,包括:
7.根据权利要求6所述的方法,其特征在于,根据所述第一训练数据集对所述预训练语言模型进行第一阶段训练,根据所述第二训练数据集进行第二阶段训练,包括:
8.一种基于训练数据的数据量训练预训练语言模型的装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并且可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述方法的步骤。
技术总结
本申请涉及机器学习技术领域,提供了一种基于训练数据的数据量训练预训练语言模型的方法及装置。该方法包括:获取训练数据集,确定训练数据集的数据量大小;根据数据量大小对预训练语言模型进行训练:当数据量大小小于第一预设大小时,冻结预训练语言模型中的参数矩阵,利用训练数据集优化预训练语言模型中的偏置项,其中,预训练语言模型中的可训练参数,包括:参数矩阵和偏置项;当数据量大小不小于第一预设大小时,利用训练数据集优化预训练语言模型中的参数矩阵和偏置项。采用上述技术手段,解决现有技术中,对预训练模型的进一步训练仍然存在优化参数量较大和耗时长,以及在训练样本数量较少的情况下易出现模型过拟合的问题。
技术研发人员:暴宇健,蒋敏,王芳
受保护的技术使用者:深圳须弥云图空间科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!