一种文字识别方法及装置与流程
本发明涉及数据处理,尤其涉及一种文字识别方法及装置。
背景技术:
1、目前,识别电子公文中的文本文字,首先要对对公文中存在的文字进行检测。但是,电子公文中的文字文本包含了多种文字类型,如文本印章中大多数是弯曲的文字内容,在同一页面中的文本文字存在的不同尺寸和大小字体,以及公文图片横幅中的轻度堆叠、形变的文字。因此通过文本检测准确查找、定位出公文图像中所有文本的单词级区域在文字识别中起着极为重要的作用。
2、现有的文字检测方法,通过利用卷积神经网络高层的卷积层提取的特征图检测文字,未考虑文本中字体大小不同、弯曲堆叠程度不同。仅采用高层特征也通常会导致图中尺度较小字体的特征信息缺失,使得不同高宽比文本的出现或字体大小的变化对文本检测系统的性能产生较大影响,检测准确性较低。
技术实现思路
1、本发明提供了一种文字识别方法及装置,以解决现有检测方案中对不同大小、弯曲程度字体检测准确性不高的技术问题。
2、为了解决上述技术问题,本发明实施例提供了一种文字识别方法,包括:
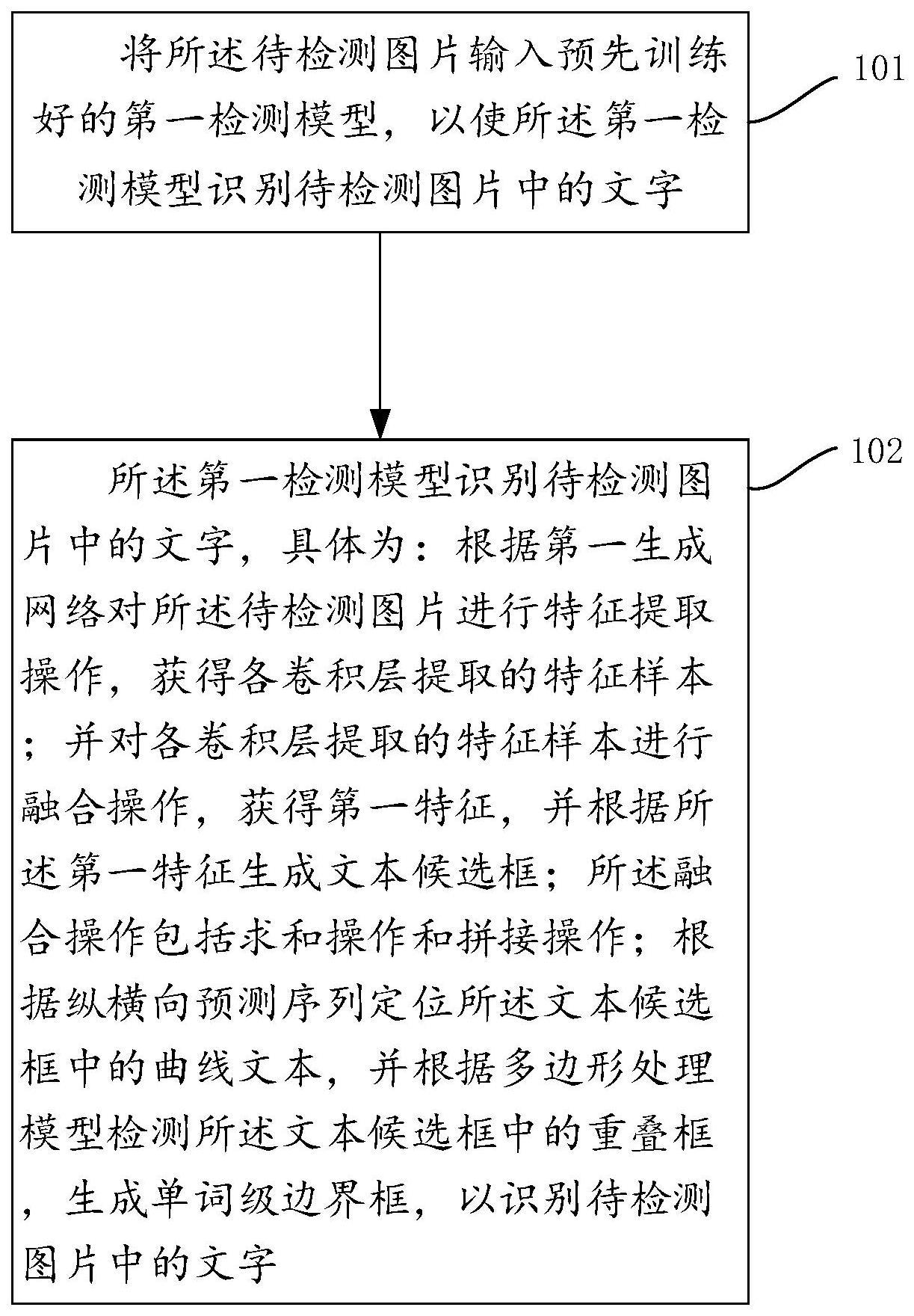
3、将待检测图片输入预先训练好的第一检测模型,以使所述第一检测模型识别待检测图片中的文字;
4、其中,所述第一检测模型识别待检测图片中的文字,具体为:
5、根据第一生成网络对所述待检测图片进行特征提取操作,获得各卷积层提取的特征样本;并对各卷积层提取的特征样本进行融合操作,获得第一特征,并根据所述第一特征生成文本候选框;所述融合操作包括求和操作和拼接操作;
6、根据纵横向预测序列定位所述文本候选框中的曲线文本,并根据多边形处理模型检测所述文本候选框中的重叠框,生成单词级边界框,以识别待检测图片中的文字。
7、本发明通过第一检测模型提取图片中的特征,并通过求和与拼接相结合的融合方式融合各卷积层之间的特征,由多个卷积层的输出融合创建新的表征特征以提高描述特征的多样性,令上层提取的信息能更平稳地传至下一层,各层能更准确地学习到从输入特征图中获取的差异性信息,提高整个模型对多尺度文本的鲁棒性;再基于纵横向预测序列检测文本框中的弯曲文本,以使无需外部连接也可定位出弯曲字体区域;最后通过基于多边形处理模型,对文字目标检测中的因物体褶皱等原因导致的重叠框加以抑制,并最终生成出更准确的单词级文本边界框,从而识别文本框中的文字,提高识别准确性。
8、进一步的,所述对各卷积层提取的特征样本进行融合操作,获得第一特征,并根据所述第一特征生成文本候选框,具体为:
9、对各个卷积层提取的特征样本进行求和操作,获取各个卷积层的特征求和结果;
10、对各个卷积层的特征求和结果进行拼接,获得第一特征,并根据所述第一特征对所述待检测图片生成文本候选框。
11、本发明先通过对不同卷积层之间的输出求和,使得上一层获得的信息更平稳地流到下一层,同时各层可以从输入的特征图中学习特征的差异性,最后再将不同层特征的求和结果拼接为新特征,既提高了收敛速度,也一定程度提升了模型得性能。
12、进一步的,在所述根据所述第一特征生成文本候选框之后,还包括:
13、对所述文本候选框进行修正操作,所述修正操作包括筛选、分组和区域修正。
14、进一步的,所述对所述文本候选框进行修正操作,具体为:
15、设置置信度阈值,筛选并保留所有置信度不低于所述置信度阈值的文本候选框;
16、根据各个文本候选框之间的交叉区域对各个文本候选框进行分组,并生成若干个区域候选边界框;
17、获取各个文本候选框的尺度因子,根据各个文本候选框的尺度因子调整所述区域候选边界框中各个文本候选框的尺寸,并将各个区域候选边界框设置为一个定值。
18、本发明通过对文本候选框进行修正操作,过滤置信度低的文本候选框,并对各个文本候选框进行分组和调整尺寸,从而使其各文本候选框中的文字定位结果更紧密,提高文本候选区域的准确性。
19、进一步的,所述根据纵横向预测序列定位所述文本候选框中的曲线文本,具体为:
20、根据目标检测特殊层连接循环神经网络,并设置所述目标检测特殊层的宽度偏移和高度偏移;
21、根据所述目标检测特殊层的宽度偏移和高度偏移分别预测所述文本候选框的横向偏移量和纵向偏移量,并根据所述横向偏移量和纵向偏移量检测所述文本候选框中的曲线文本。
22、进一步的,在所述根据所述目标检测特殊层的宽度偏移和高度偏移分别预测所述文本候选框的横向偏移量和纵向偏移量之前,还包括:
23、根据循环神经网络获取各个文本候选框的潜在特征,并根据所述潜在特征对各个文本候选框进行分类。
24、本发明通过将目标检测特殊层与循环神经网络进行连接,使得循环神经网络的时间序列数不被输入图像的大小所限制,并通过目标检测特殊层的宽度偏移和高度偏移分别预测文本候选框的横向偏移量和纵向偏移量,提高曲线文本的检测准确性。
25、进一步的,所述根据多边形处理模型检测所述文本候选框中的重叠框,生成单词级边界框,具体为:
26、将所述候选边界框映射到待检测图片中,并根据尺度因子对各个候选边界框进行缩放;
27、根据第一比例阈值对缩放后的候选边界框进行检测和过滤,并根据多边形非极大值抑制法对所述文本候选框中的重叠框进行删除,生成单词级边界框。
28、本发明通过多边形非极大值抑制法对所述文本候选框中的重叠框进行删除从而抑制文本框重叠现象,以生成单词级边界框,识别文本框中的文字,提高文字识别准确率。
29、第二方面,本发明提供了一种文字识别装置,所述文字识别装置将待检测图片输入预先训练好的第一检测模型,以使所述第一检测模型识别待检测图片中的文字
30、所述第一检测模型根据第一生成网络对所述待检测图片进行特征提取操作,获得各卷积层提取的特征样本;并对各卷积层提取的特征样本进行融合操作,获得第一特征,并根据所述第一特征生成文本候选框;所述融合操作包括求和操作和拼接操作;
31、根据纵横向预测序列定位所述文本候选框中的曲线文本,并根据多边形处理模型检测所述文本候选框中的重叠框,生成单词级边界框,以识别待检测图片中的文字。
32、第三方面,本发明提供了一种计算机设备,包括:处理器、通信接口和存储器,所述处理器、所述通信接口和所述存储器相互连接,其中,所述存储器存储有可执行程序代码,所述处理器用于调用所述可执行程序代码,执行所述的文字识别方法。
33、第四方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令被处理器执行时实现所述的文字识别方法。
技术特征:
1.一种文字识别方法,其特征在于,包括:
2.如权利要求1所述的文字识别方法,其特征在于,所述对各卷积层提取的特征样本进行融合操作,获得第一特征,并根据所述第一特征生成文本候选框,具体为:
3.如权利要求2所述的文字识别方法,其特征在于,在所述根据所述第一特征生成文本候选框之后,还包括:
4.如权利要求3所述的文字识别方法,其特征在于,所述对所述文本候选框进行修正操作,具体为:
5.如权利要求1所述的文字识别方法,其特征在于,所述根据纵横向预测序列定位所述文本候选框中的曲线文本,具体为:
6.如权利要求5所述的文字识别方法,其特征在于,在所述根据所述目标检测特殊层的宽度偏移和高度偏移分别预测所述文本候选框的横向偏移量和纵向偏移量之前,还包括:
7.如权利要求4所述的文字识别方法,其特征在于,所述根据多边形处理模型检测所述文本候选框中的重叠框,生成单词级边界框,具体为:
8.一种文字识别装置,其特征在于,所述文字识别装置将待检测图片输入预先训练好的第一检测模型,以使所述第一检测模型识别待检测图片中的文字
9.一种计算机设备,其特征在于,包括:处理器、通信接口和存储器,所述处理器、所述通信接口和所述存储器相互连接,其中,所述存储器存储有可执行程序代码,所述处理器用于调用所述可执行程序代码,执行如权利要求1至7中任一项所述的文字识别方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令被处理器执行时实现权利要求1至7中任意一项所述的文字识别方法。
技术总结
本发明公开了一种文字识别方法及装置,包括:将待检测图片输入预先训练好的第一检测模型,以使所述第一检测模型识别待检测图片中的文字;其中,所述第一检测模型识别待检测图片中的文字,具体为:根据第一生成网络对所述待检测图片进行特征提取操作,获得各卷积层提取的特征样本;并对各卷积层提取的特征样本进行融合操作,获得第一特征,并根据所述第一特征生成文本候选框;所述融合操作包括求和操作和拼接操作;根据纵横向预测序列定位所述文本候选框中的曲线文本,并根据多边形处理模型检测所述文本候选框中的重叠框,生成单词级边界框,以识别待检测图片中的文字。
技术研发人员:蔡君,唐亮,杨件,王靖聪
受保护的技术使用者:广东南方网络信息科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!