一种基于深度强化学习的图着色方法
本发明属于深度学习领域,具体涉及一种基于深度强化学习的图着色方法。
背景技术:
1、图形着色问题(gcp)是运筹学领域著名的组合优化问题。该问题的目标是使用最少的颜色对图形的节点进行着色,同时确保相邻节点没有相同的颜色。gcp有许多实际应用,例如创建时间表、故障诊断、移动无线电频率分配和寄存器分配等。传统解决图形着色问题的方法主要包括精确算法、近似算法和启发式算法。精确算法,如使用分支定界或其他枚举方法的算法,可以为小规模问题产生最优解。然而,由于其非多项式时间复杂度,这些方法对于大规模问题变得难以处理。近似算法可以提高计算效率并提供理论上的最优解,但无法保证在需要高质量解决方案的场景下得到最小的色数。启发式算法,例如禁忌搜索,可以在可接受的时间内找到良好的解决方案,但这些算法的设计需要广泛的领域知识。此外,这些算法的本质是迭代的,每个新实例都需要进行新的搜索,因此不适用于有时间限制且需要灵活性的实际场景。因此,寻求一个能够适应快速求解的需求并且具有泛化性能的图着色方法是至关重要且具有深远意义的。
技术实现思路
1、本发明的目的是提供一种基于深度强化学习的图着色方法来对图的节点进行着色。
2、本发明的技术方案如下:
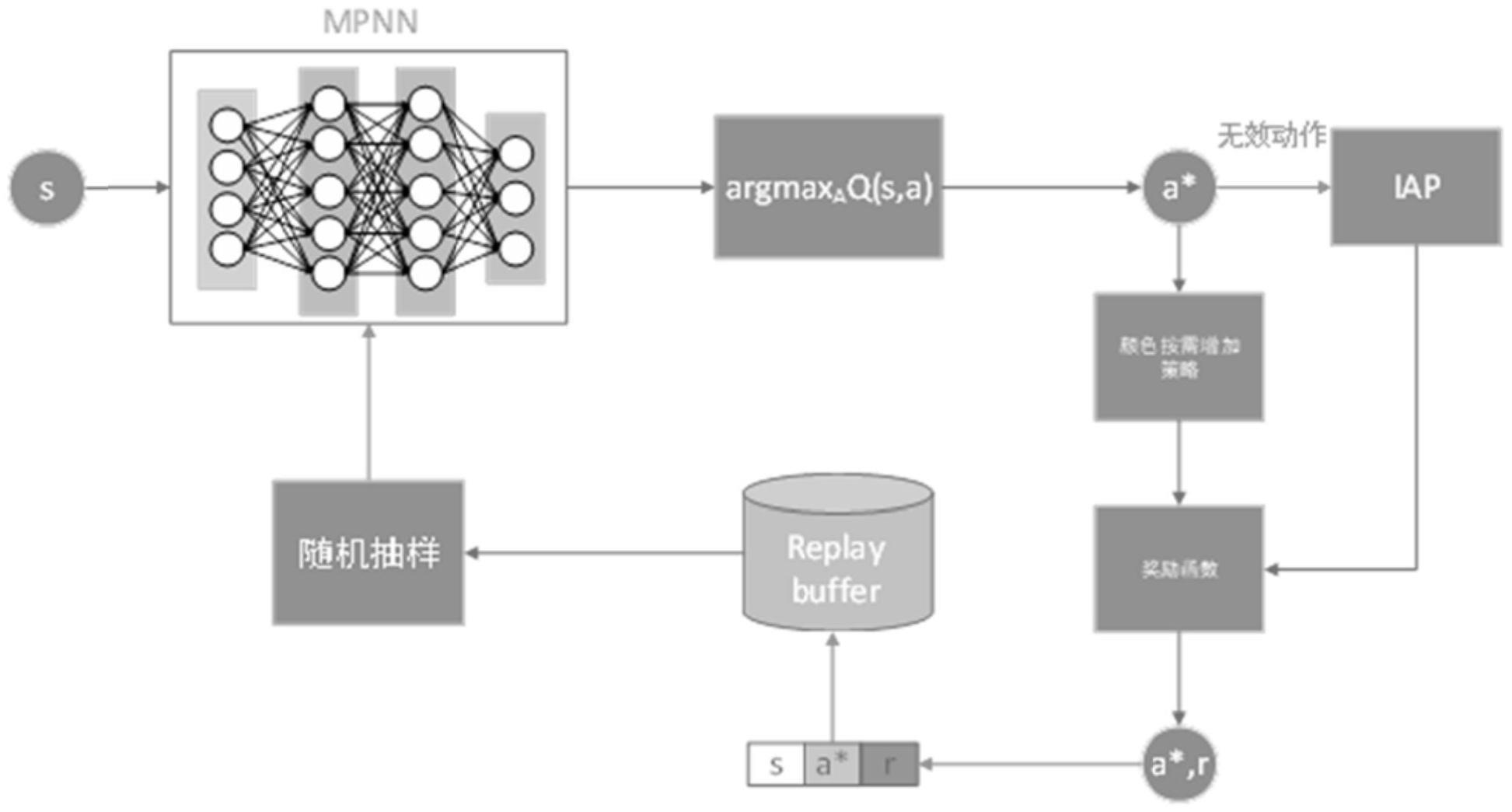
3、一种基于深度强化学习的图着色方法,其特征在于,
4、创建图着色环境;利用消息传递神经网络作为深度强化学习的智能体;
5、所述智能体以ε-greedy策略在所述图着色环境中随机探索,将每一步生成的数据存入经验回放池;
6、当经验回放池中的数据达到数量m时,从经验回放池随机取样所述生成数据的transition信息来做估值更新,将当前状态输入到所述智能体中输出每个动作的q-value,取最大的q-value所对应的顶点作为最优动作,计算奖励值,训练所述智能体;
7、利用训练好的智能体对图进行着色,并给出着色方案以及颜色数。
8、进一步的,所述创建图着色环境具体为:
9、将图形着色问题转化为单向的markov链模型并构建各个状态之间的势能关系,然后采用按需增加颜色数的策略来创建图着色环境。
10、进一步的,设计带有iap的奖励函数引导智能体学习最优着色策略。
11、进一步的,所述iap的设计原则具体为:
12、iap应优先于其他惩罚;因为智能体的目标是最大化回报,当增加色数的奖励小于无效动作的奖励时,智能体可能会选择一个无效的动作,而不是导致色数增加的动作,这会导致智能体的探索停滞不前,无法在有限的步数内完成图着色任务。
13、iap和主体的奖励应该始终保持协调;惩罚过大会影响智能体对主要目标的学习。
14、进一步的,所述奖励函数公式为:
15、
16、其中,χ(st)是状态st的色数,表示无效动作的集合,a表示当前执行的动作即选择着色的顶点。
17、进一步的,所述按需增加颜色数的策略具体为:
18、颜色数初始化为1,在递增构造解的过程中,当现有的颜色数量满足不了相邻顶点颜色数不同的约束时才增加颜色数。
19、进一步的,训练所述智能体。
20、本发明的技术效果:
21、本发明提出了一种基于深度强化学习的图着色方法。将图着色问题转化为一个单向的markov链模型,使得智能体在探索过程中不会陷入循环轨迹,并构建各个状态之间的势能关系。递增构造解的过程中设计了按需增加颜色数的策略,使得不需要颜色数的先验知识。最后设计了带有iap的奖励函数引导智能体学习最优着色策略。
技术特征:
1.一种基于深度强化学习的图着色方法,其特征在于,
2.根据权利要求1所述的基于深度强化学习的图着色方法,其特征在于,所述创建图着色环境具体为:
3.根据权利要求1所述的基于深度强化学习的图着色方法,其特征在于,设计带有无效动作惩罚iap的奖励函数引导智能体学习最优着色策略。
4.根据权利要求3所述的基于深度强化学习的图着色方法,其特征在于,所述iap的设计原则具体为:
5.根据权利要求3所述的基于深度强化学习的图着色方法,其特征在于,所述奖励函数公式为:
6.根据权利要求2所述的基于深度强化学习的图着色方法,其特征在于,所述按需增加颜色数的策略具体为:
技术总结
一种基于深度强化学习的图着色方法;创建图着色环境;利用消息传递神经网络作为深度强化学习的智能体;所述智能体在所述图着色环境中随机探索,将每一步生成的数据存入经验回放池;从经验回放池随机取样所述生成数据的信息来做估值更新,将当前状态输入到所述智能体中输出每个动作的Q‑value,取最大的Q‑value所对应的顶点作为最优动作,计算奖励值,训练所述智能体;利用训练好的智能体对图进行着色,并给出着色方案以及颜色数。本发明将图着色问题转化为一个单向的Markov链模型,使得智能体在探索过程中不会陷入循环轨迹,递增构造解的过程中设计了按需增加颜色数的策略,使得不需要颜色数的先验知识,最后设计了奖励函数引导智能体学习最优着色策略。
技术研发人员:李小龙,黄珂,陈晓红,董莉
受保护的技术使用者:湖南工商大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!