一种数据同步的方法和装置与流程
本发明涉及计算机,尤其涉及一种数据同步的方法和装置。
背景技术:
1、在现有的数据处理过程中,对于不同的数据处理需要使用不同的机器学习模型,且每个终端上同一时间只能安装一个当前应用的机器学习模型。因此,现有技术是将多个机器学习模型均是存储在远端网盘的,在每次需要测试模型或者更新/恢复模型时,从远端的网盘中拉取需要的目标模型到本地的服务目录中,以使模型使用平台可以根据服务目录中的模型文件进行模型加载。
2、但是,随着机器学习模型的快速更新换代,当模型的版本需要多次重复更新或恢复时,依赖多次从网盘进行数据的拉取,例如从模型a更新为模型b,从模型b恢复为模型a时,需要先拉取一次模型b,再拉取一次模型a,受限于系统网络带宽、存储介质等原因,会导致模型状态恢复时间较长,恢复稳定性较差等问题。
技术实现思路
1、有鉴于此,本发明实施例提供一种数据同步的方法和装置,通过设置本地备份目录,将远端网盘中存储的模型文件预先拉取到本地,当需要利用服务目录进行模型加载时,无需多次重复拉取模型文件,仅需修改服务目录中与目标模型对应的第一索引节点编码以及与当前应用模型对应的第二索引节点编码的索引节点的个数即可,避免复制失败导致的文件不完整问题,节省数据同步时间,实现了模型的快速处理。
2、为实现上述目的,根据本发明实施例的一个方面,提供了一种数据同步的方法。
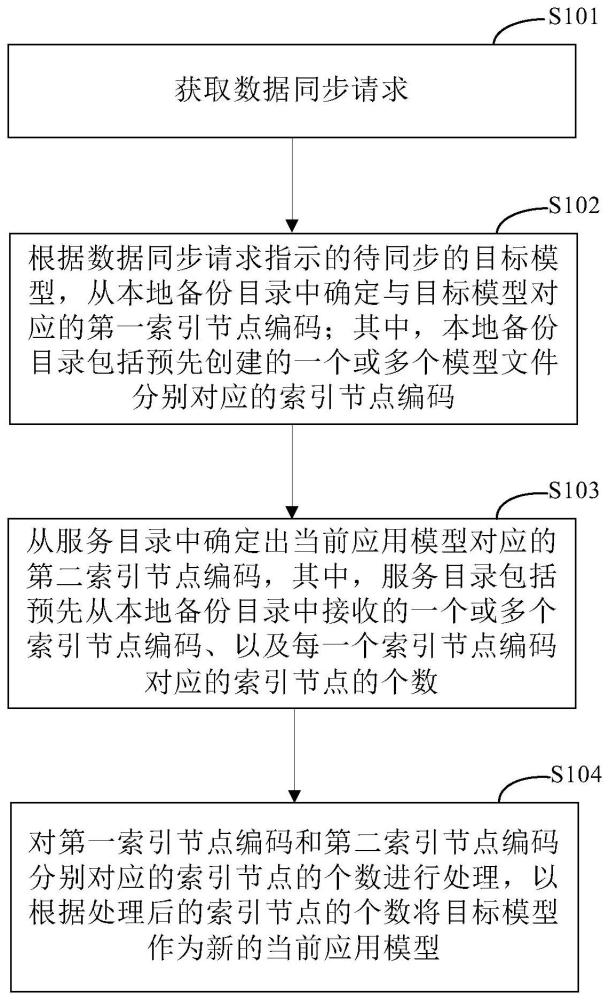
3、本发明实施例的一种数据同步的方法包括:获取数据同步请求;根据所述数据同步请求指示的待同步的目标模型,从本地备份目录中确定与所述目标模型对应的第一索引节点编码;其中,所述本地备份目录包括预先创建的一个或多个模型文件分别对应的索引节点编码;从服务目录中确定出当前应用模型对应的第二索引节点编码,其中,所述服务目录包括预先从所述本地备份目录中接收的一个或多个所述索引节点编码、以及每一个所述索引节点编码对应的索引节点的个数;对所述第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理,以根据处理后的索引节点的个数将所述目标模型作为新的当前应用模型。
4、可选地,该方法还包括:在所述服务目录中创建与所述目标模型对应的索引节点,并删除所述当前应用模型对应的索引节点。
5、可选地,所述对所述第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理,包括:根据所述本地备份目录以及所述服务目录中的索引节点的个数,确定所述第一索引节点编码对应的第一节点数量、以及所述第二索引节点编码对应的第二节点数量;递增所述第一节点数量,并递减所述第二节点数量,以对所述第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理。
6、可选地,在所述获取数据同步请求之前,还包括:利用本地备份目录获取一个或多个模型文件,并创建各个所述模型文件分别对应的索引节点以及所述索引节点对应的索引节点编码。
7、可选地,所述从本地备份目录中确定与所述目标模型对应的第一索引节点编码,包括:在所述本地备份目录中不存在所述第一索引节点编码的情况下,利用本地备份目录获取与所述目标模型对应的目标模型文件,并为所述目标模型文件创建对应的第一索引节点编码。
8、可选地,该方法还包括:对所述模型对应的版本编码、模型文件进行校验,在校验通过的情况下,利用加载机器学习模型对所述目标模型进行加载;根据加载结果,确定所述目标模型的服务状态。
9、可选地,在所述获取数据同步请求之后,还包括:将所述服务目录中的模型的服务状态修改为模型更新中或模型恢复中;所述根据加载结果,确定所述目标模型的服务状态,包括:在加载成功的情况下,确定所述目标模型的服务状态为更新完成或恢复完成。
10、可选地,还包括:在加载失败的情况下,确定所述目标模型的服务状态为更新失败或恢复失败,并将所述服务状态上报至报警系统,以提示所述数据同步请求处理失败。
11、为实现上述目的,根据本发明实施例的又一方面,提供了一种数据同步的装置。
12、本发明实施例的一种数据同步的装置包括:获取模块,用于获取数据同步请求;第一确定模块,用于根据所述数据同步请求指示的待同步的目标模型,从本地备份目录中确定与所述目标模型对应的第一索引节点编码;其中,所述本地备份目录包括预先创建的一个或多个模型文件分别对应的索引节点编码;第二确定模块,用于从服务目录中确定出当前应用模型对应的第二索引节点编码,其中,所述服务目录包括预先从所述本地备份目录中接收的一个或多个所述索引节点编码、以及每一个所述索引节点编码对应的索引节点的个数;处理模块,用于对所述第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理,以根据处理后的索引节点的个数将所述目标模型作为新的当前应用模型。
13、为实现上述目的,根据本发明实施例的又一方面,提供了一种电子设备。
14、本发明实施例的一种电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明实施例的一种数据同步的方法。
15、为实现上述目的,根据本发明实施例的再一方面,提供了一种计算机可读存储介质。
16、本发明实施例的一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本发明实施例的一种数据同步的方法。
17、上述发明中的一个实施例具有如下优点或有益效果:通过设置本地备份目录,将远端网盘中存储的模型文件预先拉取到本地,当需要利用服务目录进行模型加载时,无需多次重复拉取模型文件,仅需修改服务目录中与目标模型对应的第一索引节点编码以及与当前应用模型对应的第二索引节点编码的索引节点的个数即可,避免复制失败导致的文件不完整问题,节省数据同步时间,实现了模型的快速处理。
18、上述的非惯用的可选方式所具有的进一步效果将在下文中结合具体实施方式加以说明。
技术特征:
1.一种数据同步的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,还包括:
3.根据权利要求1所述的方法,其特征在于,所述对所述第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理,包括:
4.根据权利要求1所述的方法,其特征在于,在所述获取数据同步请求之前,还包括:
5.根据权利要求4所述的方法,其特征在于,所述从本地备份目录中确定与所述目标模型对应的第一索引节点编码,包括:
6.根据权利要求1所述的方法,其特征在于,还包括:
7.根据权利要求1所述的方法,其特征在于,在所述获取数据同步请求之后,还包括:将所述服务目录中的模型的服务状态修改为模型更新中或模型恢复中;
8.根据权利要求7所述的方法,其特征在于,还包括:
9.一种数据同步的装置,其特征在于,包括:
10.一种电子设备,其特征在于,包括:
11.一种计算机可读介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如权利要求1-8中任一所述的方法。
技术总结
本发明公开了一种数据同步的方法和装置,涉及计算机技术领域。该方法的具体实施方式包括:获取数据同步请求;根据数据同步请求指示的目标模型,从本地备份目录中确定与目标模型对应的第一索引节点编码;从服务目录中确定出当前应用模型对应的第二索引节点编码,其中,服务目录包括预先从本地备份目录中接收的一个或多个索引节点编码、以及每一个索引节点编码对应的索引节点的个数;对第一索引节点编码和第二索引节点编码分别对应的索引节点的个数进行处理,以根据处理后的索引节点的个数将目标模型作为新的当前应用模型。该实施方式无需多次重复拉取模型文件,实现了模型的快速处理。
技术研发人员:李健,吕惠东,齐浩,金均生,王昆垚,李雪莹,王叶
受保护的技术使用者:北京沃东天骏信息技术有限公司
技术研发日:
技术公布日:2024/12/5
- 还没有人留言评论。精彩留言会获得点赞!