数据聚类方法、装置和处理器及电子设备与流程
本技术涉及大数据领域,具体而言,涉及一种数据聚类方法、装置和处理器及电子设备。
背景技术:
1、聚类算法在初始化阶段需要确定聚类中心,即质心,现有技术中常常采用随机抽取的方式以确定预设数量的质心,然而,该方式存在抽取的质心分布过于分散或集中的情况,进而导致质心分布不够均匀,从而造成后续数据聚类的准确性较低。
2、针对相关技术中数据聚类的准确性较低的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术的主要目的在于提供一种数据聚类方法、装置和处理器及电子设备,以解决相关技术中数据聚类的准确性较低的问题。
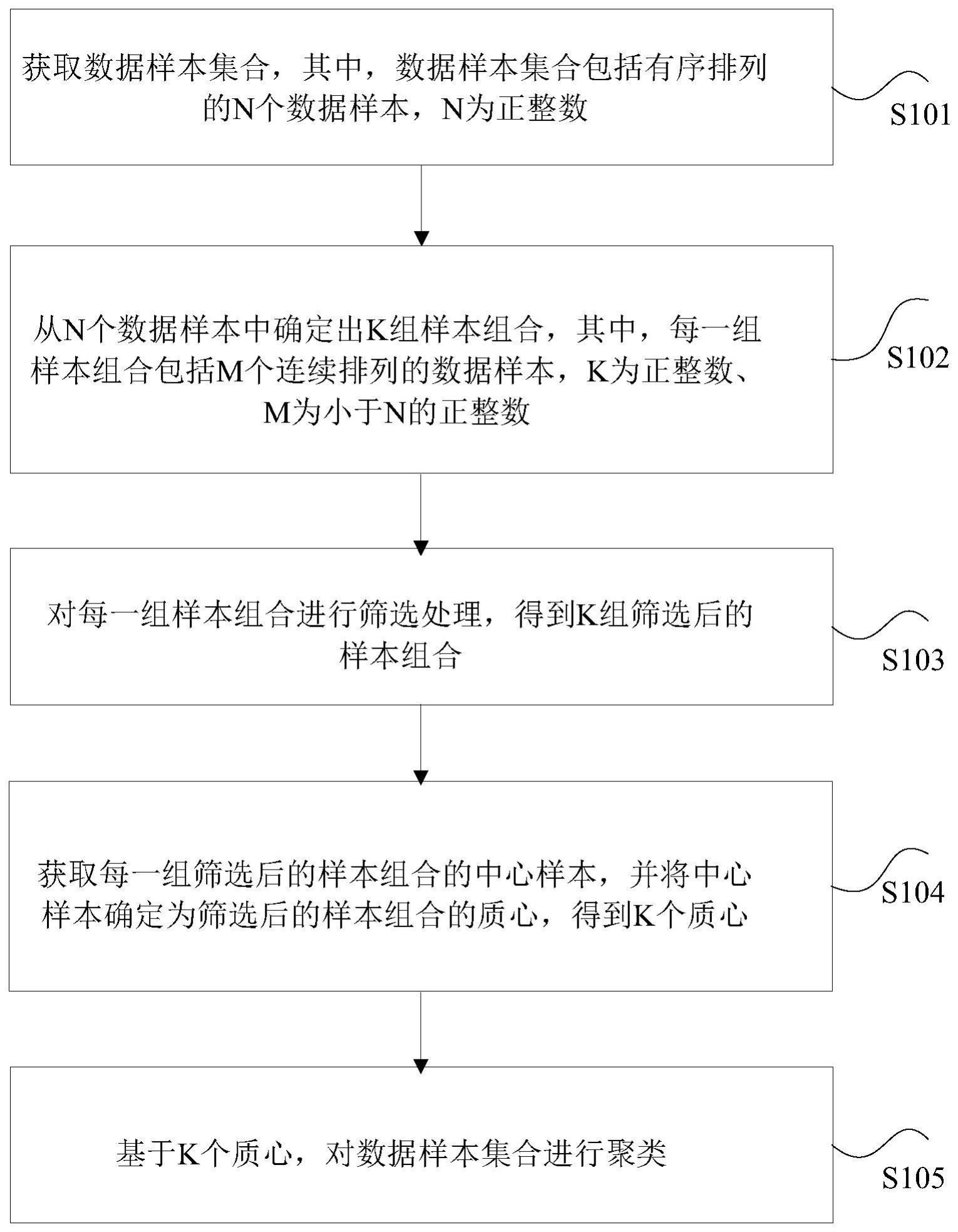
2、为了实现上述目的,根据本技术的一个方面,提供了一种数据聚类方法。该方法包括:获取数据样本集合,其中,上述数据样本集合包括有序排列的n个数据样本,n为正整数;从上述n个数据样本中确定出k组样本组合,其中,每一组样本组合包括m个连续排列的数据样本,k为正整数、m为小于n的正整数;对上述每一组样本组合进行筛选处理,得到k组筛选后的样本组合;获取每一组上述筛选后的样本组合的中心样本,并将上述中心样本确定为上述筛选后的样本组合的质心,得到k个质心;基于上述k个质心,对上述数据样本集合进行聚类。
3、作为一种可选的方案,上述对上述每一组样本组合进行筛选处理,得到k组筛选后的样本组合包括:获取第i组样本组合中密度最大的第一数据样本,其中,i为小于k的正整数;依次遍历上述第i组样本组合包括的全部数据样本,得到符合预设距离条件的目标数据样本,其中,上述第i组样本组合对应的上述筛选后的样本组合包括上述目标数据样本,上述预设距离条件用于指示上述目标数据样本与上述第一数据样本之间的余弦距离小于预设余弦距离阈值。
4、作为一种可选的方案,上述获取第i组样本组合中样本密度最大的第一数据样本包括:获取上述第i组样本组合包括的各个数据样本的样本密度,并从中确定出样本密度最大的上述第一数据样本;其中,获取上述第i组样本组合的当前数据样本的样本密度包括:获取上述当前数据样本关联的p个第一近邻数据样本,其中,上述p个第一近邻数据样本在上述第i组样本组合中与上述当前数据样本的余弦距离最近,上述第i组样本组合包括上述p个第一近邻数据样本;获取每一个第一近邻数据样本关联的p个第二近邻数据样本,其中,上述p个第二近邻数据样本在上述第i组样本组合中与上述第一近邻数据样本的余弦距离最近,上述第i组样本组合包括上述p个第二近邻数据样本;对上述p个第一近邻数据样本和上述每一个第一近邻数据样本关联的p个第二近邻数据样本做并集处理,得到上述当前数据样本关联的目标近邻数据样本集合;获取上述目标近邻数据样本集合包括的近邻数据样本的数量和值、以及获取上述目标近邻数据样本集合包括的各个近邻数据样本与上述当前数据样本的余弦距离的累加和值;将上述数量和值和上述累加和值的商确定为上述当前数据样本的样本密度。
5、作为一种可选的方案,上述从上述n个数据样本中确定出k组样本组合包括:获取第j个样本组合关联的窗口中心,其中,上述窗口中心用于指示上述n个数据样本中的第(2j-1)*n/2a个数据样本;将上述n个数据样本中的第(2j-1)*n/2a个数据样本至第(2j-1)*n/2a+m-1个数据样本在内的m个数据样本确定为上述第j个样本组合。
6、作为一种可选的方案,上述获取每一组上述筛选后的样本组合的中心样本,并将上述中心样本确定为上述筛选后的样本组合的质心包括:从上述筛选后的样本组合中选取一个数据样本作为初始质心近邻点;从上述筛选后的样本组合的其他数据样本确定出满足预设相似条件的至少一个目标数据样本,其中,上述预设相似条件用于指示上述至少一个目标数据样本与上述初始质心近邻点之间的余弦相似度大于预设相似度阈值;将上述至少一个目标数据样本的中心确定为上述中心样本。
7、作为一种可选的方案,上述获取数据样本集合包括:获取待排序的初始数据样本集合,其中,上述初始数据样本集合包括无序排列的n个初始数据样本;依次遍历上述n个初始数据样本,获取每一个初始数据样本的样本密度,并将样本密度最小的初始数据样本确定为边缘数据样本;根据其他初始数据样本与上述边缘数据样本之间的余弦距离,对上述其他初始数据样本进行排序,并将排序后的初始数据样本集合确定为上述数据样本集合,其中,上述边缘数据样本位于边缘位置,与上述边缘数据样本之间的余弦距离越大的数据样本的位置,与上述边缘位置相距越远、且靠前中心位置。
8、作为一种可选的方案,上述获取待排序的初始数据样本集合包括:从历史消费日志集合中获取上述初始样本集合,其中,上述历史消费日志集合包括客户端关联的账号在历史时间段的使用过程中产生的消费日志数据;在得到聚类后的目标样本集合之后,上述方法还包括:利用数据聚类结果,对上述账号关联的消费风险等级进行分类。
9、为了实现上述目的,根据本技术的另一方面,提供了一种数据聚类装置。该装置包括:第一获取单元,用于获取数据样本集合,其中,上述数据样本集合包括有序排列的n个数据样本,n为正整数;确定单元,用于从上述n个数据样本中确定出k组样本组合,其中,每一组样本组合包括m个连续排列的数据样本,k为正整数、m为小于n的正整数;筛选单元,用于对上述每一组样本组合进行筛选处理,得到k组筛选后的样本组合;第二获取单元,用于获取每一组上述筛选后的样本组合的中心样本,并将上述中心样本确定为上述筛选后的样本组合的质心,得到k个质心;聚类单元,用于基于上述k个质心,对上述数据样本集合进行聚类。
10、作为一种可选的方案,上述筛选单元,包括:第一获取模块,用于获取第i组样本组合中密度最大的第一数据样本,其中,i为小于k的正整数;第一遍历模块,用于依次遍历上述第i组样本组合包括的全部数据样本,得到符合预设距离条件的目标数据样本,其中,上述第i组样本组合对应的上述筛选后的样本组合包括上述目标数据样本,上述预设距离条件用于指示上述目标数据样本与上述第一数据样本之间的余弦距离小于预设余弦距离阈值。
11、作为一种可选的方案,上述获取模块,用于包括:第一获取子模块,用于获取上述第i组样本组合包括的各个数据样本的样本密度,并从中确定出样本密度最大的上述第一数据样本;其中,获取上述第i组样本组合的当前数据样本的样本密度包括:第二获取子模块,用于获取上述当前数据样本关联的p个第一近邻数据样本,其中,上述p个第一近邻数据样本在上述第i组样本组合中与上述当前数据样本的余弦距离最近,上述第i组样本组合包括上述p个第一近邻数据样本;第三获取子模块,用于获取每一个第一近邻数据样本关联的p个第二近邻数据样本,其中,上述p个第二近邻数据样本在上述第i组样本组合中与上述第一近邻数据样本的余弦距离最近,上述第i组样本组合包括上述p个第二近邻数据样本;第四获取子模块,用于对上述p个第一近邻数据样本和上述每一个第一近邻数据样本关联的p个第二近邻数据样本做并集处理,得到上述当前数据样本关联的目标近邻数据样本集合;第五获取子模块,用于获取上述目标近邻数据样本集合包括的近邻数据样本的数量和值、以及获取上述目标近邻数据样本集合包括的各个近邻数据样本与上述当前数据样本的余弦距离的累加和值;确定子模块,用于将上述数量和值和上述累加和值的商确定为上述当前数据样本的样本密度。
12、作为一种可选的方案,上述确定单元包括:第二获取模块,用于获取第j个样本组合关联的窗口中心,其中,上述窗口中心用于指示上述n个数据样本中的第(2j-1)*n/2a个数据样本;第一确定模块,用于将上述n个数据样本中的第(2j-1)*n/2a个数据样本至第(2j-1)*n/2a+m-1个数据样本在内的m个数据样本确定为上述第j个样本组合。
13、作为一种可选的方案,上述第二获取模块包括:第三获取模块,用于从上述筛选后的样本组合中选取一个数据样本作为初始质心近邻点;第二确定模块,用于从上述筛选后的样本组合的其他数据样本确定出满足预设相似条件的至少一个目标数据样本,其中,上述预设相似条件用于指示上述至少一个目标数据样本与上述初始质心近邻点之间的余弦相似度大于预设相似度阈值;第三确定模块,用于将上述至少一个目标数据样本的中心确定为上述中心样本。
14、作为一种可选的方案,上述第一获取单元包括:第四获取模块,用于获取待排序的初始数据样本集合,其中,上述初始数据样本集合包括无序排列的n个初始数据样本;第二遍历模块,用于依次遍历上述n个初始数据样本,获取每一个初始数据样本的样本密度,并将样本密度最小的初始数据样本确定为边缘数据样本;排序模块,用于根据其他初始数据样本与上述边缘数据样本之间的余弦距离,对上述其他初始数据样本进行排序,并将排序后的初始数据样本集合确定为上述数据样本集合,其中,上述边缘数据样本位于边缘位置,与上述边缘数据样本之间的余弦距离越大的数据样本的位置,与上述边缘位置相距越远、且靠前中心位置。
15、作为一种可选的方案,上述第四获取模块包括:第六获取子模块,用于从历史消费日志集合中获取上述初始样本集合,其中,上述历史消费日志集合包括客户端关联的账号在历史时间段的使用过程中产生的消费日志数据;上述装置还包括:分类模块,用于在得到聚类后的目标样本集合之后,利用数据聚类结果,对上述账号关联的消费风险等级进行分类。
16、通过本技术,采用以下步骤:获取数据样本集合,其中,上述数据样本集合包括有序排列的n个数据样本,n为正整数;从上述n个数据样本中确定出k组样本组合,其中,每一组样本组合包括m个连续排列的数据样本,k为正整数、m为小于n的正整数;对上述每一组样本组合进行筛选处理,得到k组筛选后的样本组合;获取每一组上述筛选后的样本组合的中心样本,并将上述中心样本确定为上述筛选后的样本组合的质心,得到k个质心;基于上述k个质心,对上述数据样本集合进行聚类。本技术基于初步排序后的数据样本集合,通过局部连续样本的筛选(窗口截取)方式得到多个窗口,并获取每一个窗口的中心样本以确定后续用于聚类的质心,其中,基于连续排列和窗口截取以及中心样本的确定方式,使得得到的新的质心点与初始质心点之间是“相对均匀关系”,保障了质心点选取的均匀性,从而实现提高后续基于质心的算法聚类的准确性的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!