一种基于可见红外图像融合与改进yolov5的低光照场景下目标检测方法
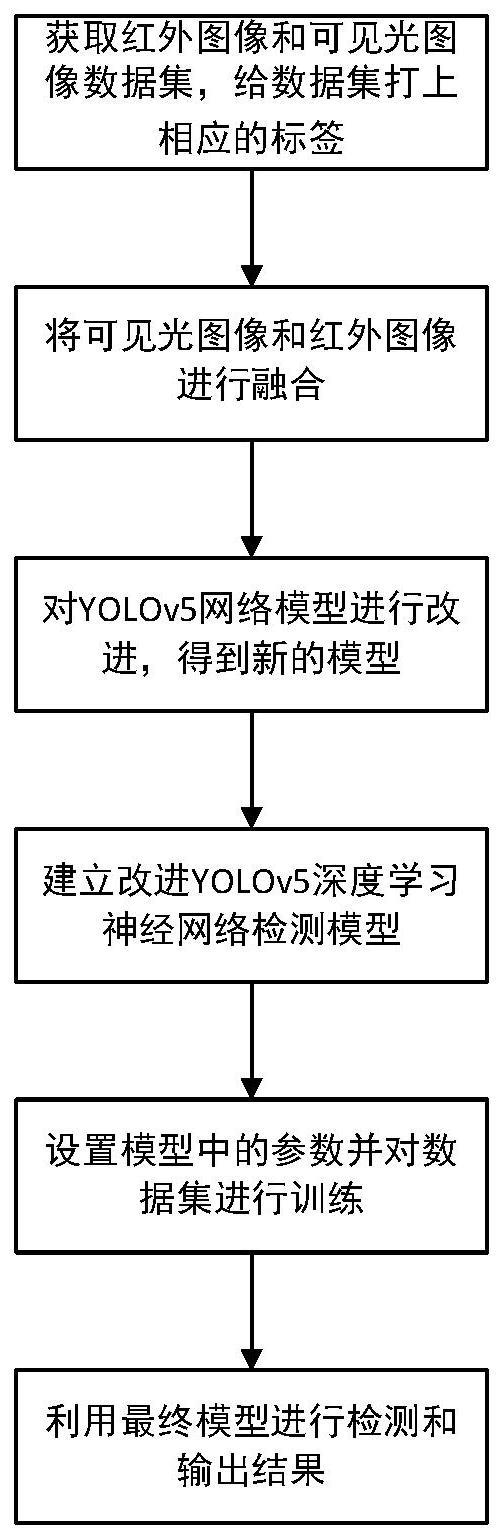
本发明涉及低光照场景下目标检测,尤其涉及一种基于可见红外图像融合与改进yolov5的低光照场景下的目标检测方法。
背景技术:
1、目标检测是计算机视觉领域的重要任务之一,在许多场景中具有广泛的应用,例如实例分割、目标跟踪和行人检测任务等等。在目标检测应用场景中,所拍摄图像的照明度是影响检测精度的重要因素之一。
2、低光照场景是指夜晚或者光照环境较差的场景,不充分的光照会严重损害并降低图像的视觉质量,在低光照场景下拍摄的图片存在可见度低、对比度差和色彩偏差等缺点,不仅令人眼对图像的主观感受产生偏差,而且对于计算机视觉网络来说识别此类图片也具有一定的难度。
3、现有的许多目标检测模型基本都是在光照条件充足的情况下才能有效的运行,如果不加修改将其应用到低光照的场景下时,模型的性能将会受到严重的影响。因此,为了能够提高目标检测模型在低光照场景下的检测精度,急需有效的低光照场景下的目标检测技术。
技术实现思路
1、本发明所要解决的主要技术问题是:针对低光照场景下的图像,如何更加有效的提取更多的图像特征,提高目标检测精度。具体来讲,考虑到红外图像具有不受光照条件限制的优点,本发明利用在同一场景下的红外图像特征,将红外图像和可见光图像进行融合,使得融合后的图像结合可见光和红外图像的优点,而后将融合好的图像使用yolov5目标检测算法进行模型训练。此外,考虑到模型比较庞大,参数量过多,欲对yolov5网络进行轻量化处理,将yolov5的backbone换成ghost轻量化网络,以减少模型的参数。
2、本发明解决上述技术问题所采用的技术方案为:一种基于图像融合与改进yolov5的低光照场景下目标检测方法,包括以下所示步骤:
3、步骤(1):将红外图像和可见光图像分别采用均值滤波方法生成基础层,经多次对比实现,发现均值滤波窗口设置为35时,其运行速度快以及滤波后的图像质量较好,故本文均值滤波窗口大小设为35,具体计算公式如下:
4、
5、
6、其中分别表示可见光图像和红外图像,x,y表示图像的长和宽,μ(x,y)表示加权矩阵,分别表示得到的可见光基础层和红外图像基础层;
7、步骤(2):在得到基础层后,通过原始图像与基础层图像相减得到细节层图像,具体公式如下:
8、
9、
10、其中分别表示可见光图像和红外图像,x,y表示图像的长和宽,分别表示可见光基础层图像和红外基础层图像,分别表示可见光细节层图像和红外细节层图像;
11、步骤(3):分别将可见光图像基础层和红外图像基础层、可见光图像细节层和红外图像细节层进行融合,具体实施过程如下所示:
12、步骤(3.1):基础层的融合,使用平均的策略进行融合,具体公式如下:
13、
14、其中分别表示得到的可见光基础层和红外图像基础层,表示可见光图像基础层和红外图像基础层融合后的图像;
15、步骤(3.2):细节层的图像采用的是加权平均的策略进行融合,其中加权系数是通过将原始图像分别采用均值滤波和中值滤波处理,而后将均值滤波得到的图像减去中值滤波得到的图像并取绝对值得到相应的系数矩阵,具体公式如下:
16、
17、其中表示原图像经过均值滤波后得到的图像,表示原图像经过中值滤波得到的图像,ε(x,t)表示得到的系数矩阵。
18、步骤(3.3):通过得到的可见光图像的系数矩阵和红外图像的系数矩阵,基于这两个系数矩阵,得到细节层的融合系数矩阵,具体公式如下:
19、
20、
21、其中ε1(x,y),ε2(x,y)分别表示可见光图像的系数矩阵和红外图像的系数矩阵,分别表示得到的可见光图像和红外图像的融合系数矩阵;
22、步骤(3.4):将得到的融合系数矩阵用于细节层的融合,具体公式如下:
23、
24、其中分别表示可见光图像和红外图像系数融合矩阵,分别表示可见光图像和红外图像细节层,表示将可见光图像细节层和红外图像细节层加权平均融合后得到的细节层图像;
25、步骤(4):在得到融合后的基础层和细节层之后,通过简单的加法将融合后的基础层和细节层进行融合,具体公式如下:
26、
27、其中表示融合后的基础层,表示融合后的细节层,γ(x,y)表示可见光图像和红外图像融合后的图像;
28、步骤(5):将yolov5模型主干网络中的c3模块换成c3ghost,c3ghost相比于传统的c3模块,其将输入特征进行分解重组,可产生多样化的特征表示,这种多样性可以增加模型对不同尺度语义特征的感知能力,有助于提高模型对复杂场景和目标的识别定位能力,并且c3ghost参数量更少;同时将yolov5的卷积神经网络改进成ghostconv网络,在几乎不影响模型检测精度时,降低模型复杂度,使得模型轻量化;传统的卷积层输出特征图中,许多都是两两相似的,对于这些相似的特征,ghostconv采用简单的变化进行特征提取,可更好的利用特征之间的相关性和冗余性。ghostconv首先通过常规卷积提取特征信息,获取一般特征图,而后将一般特征图中每一个通道的特征做线性运算,获取同等通道数的附带特征图(即ghost特征图)。ghost特征图就是冗余的特征图数量,使之可以在几乎不影响检测精度的同时降低普通卷积conv的冗余性,降低计算复杂度,从而减少模型参数;
29、步骤(6):对步骤(4)得到的融合后的图像输入到改进后的yolov5模型中的输入层进行马赛克数据增强、自适应锚框计算、自适应图片缩放预处理得到特征图(640*640);
30、步骤(7):对步骤(6)中预处理得到的特征图输入到主干网络层提取类别特征,backbone层由ghostconv模块、c3ghost网络模块和空间金字塔池化模块组成,经过以上模块处理后得到三个尺寸的特征图;
31、步骤(8):对步骤(7)中得到的不同尺寸的特征图输入的neck层进行上采样和特征融合得到80*80、40*40和20*20三种尺寸的张量;
32、步骤(9):对步骤(8)中经neck层处理得到的三种尺寸的张量输入到预测层,计算得到预测框的位置,并利用平均精度值参数进行评价;
33、与传统方法相比,本发明方法的优势在于:
34、首先,本发明考虑到低光照情况下,可见光图像所能提供的特征信息有限,故将红外图像与可见光图像进行融合,使得融合后的图像具有两类图像各自的优点,承载着更多的特征信息用于目标检测;其次,本发明在yolov5的基础上进行轻量化改进,使得网络的参数量极大的减少,同时融合红外图像提升目标检测的精度。可以说,本发明方法是一种更为优选的低光照场景下的目标检测方法;
技术特征:
1.一种基于图像融合与改进yolov5的低光照场景下目标检测方法,包括以下步骤:
2.如权利要求1所述的图像融合方法,其特征在于,
3.如权利要求1所述的改进yolov5网络结构的轻量化目标检测方法,其特征在于,
4.如权利要求3所述的改进yolov5网络结构的轻量化目标检测方法,其特征在于,
技术总结
本发明公开一种新的基于图像融合与改进yolov5的低光照场景下目标检测方法,旨在针对低光照场景下,提取更多的图像特征,提高目标检测的精确度。本发明方法的核心是引入红外图像,结合红外图像不受光照条件影响的优点,以提供更多的图像特征,将可见光图像和红外图像进行融合,使得融合后的图像具有可见光图像和红外图像的优点,而后将融合好的图像使用YOLOv5目标检测算法进行模型训练,考虑到模型的参数量过多,计算量大,本发明在YOLOv5模型的基础上,引入Ghost网络,减少模型的参数量,相较于其他传统的方法,该方法可以更好地在低光照场景下进行目标检测,并且获得较高的精确度。可以说,本发明方法是一种更为优选的低光照场景下的目标检测方法。
技术研发人员:宋冰,李聪,侍洪波,谭帅,陶阳
受保护的技术使用者:华东理工大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!