一种运算加速架构、系统及使用方法与流程
本申请涉及运算加速电路结构领域,尤其涉及一种运算加速架构、系统及使用方法。
背景技术:
1、随着微控制器应用的普及和发展,当前微控制器的应用也在不断升级。成熟的微控制器(arm/8051/pi c)内核为通用设计考虑,内核一般不具备负责运算加速功能,比如除法/开方这些基本运算以及复杂的正余弦/滤波算法。为了扩展微控制器的应用,需要在系统设计时增加这些运算加速模块。在内核中直接增加这些运算加速特性一般是不被推荐的,因为这需要对内核的执行结构进行比较大的改动,增加了不确定性。另外复杂的运算往往需要多周期完成,对于顺序执行的控制构架,这将会严重的影响到整体的执行效率。
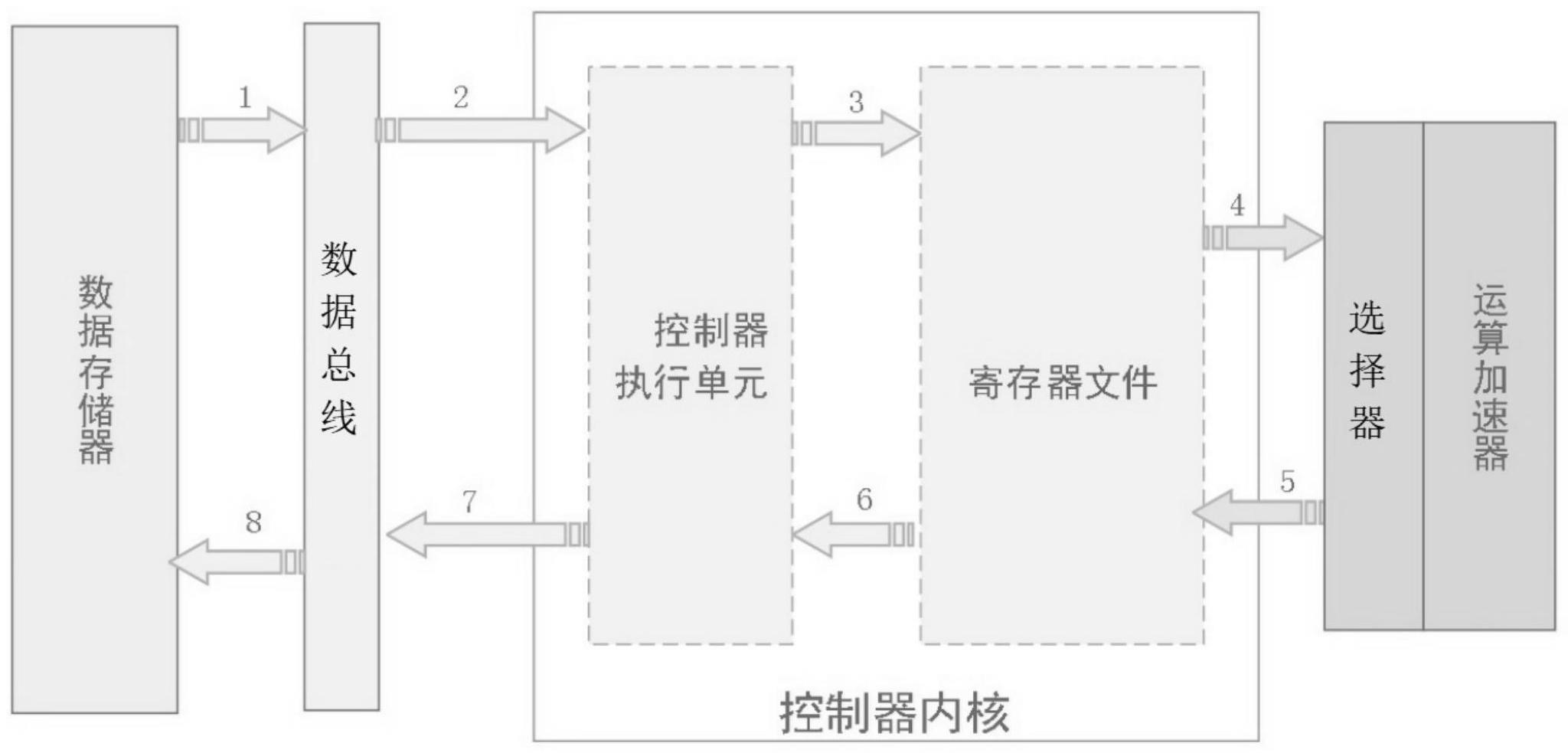
2、如图1所示,传统实现运算加速是把运算加速设计为独立的i/o外设,内核通过数据存储总线实现访问,无需对内核进行修改。这种实现方式比较灵活,但效率并不高。如图1所示为现有的传统运算加速外设方式,传统运算加速器扩展在实际应用中的数据流图,数据按照图1中阿拉伯数字标记的顺序经过1 2步完成。以一个8周期的3 2位除法运算为例,因为软件使用一个函数来实现对运算加速器的使用,数据通过函数参数传递到函数内部,软件将数据写到加速器内部的寄存器执行运算,然后函数返回运算结果,这是软件的数据流。但实际上,软件编译后产生执行的指令,微控制器执行这些指令,内核的整个数据流过程就如图1所示。
3、首先内核通过数据总线读所需数据,读到内部的通用寄存器文件(1/2/3步为函数的参数传递),然后将通用寄存器文件中的数据通过ld/s t指令,经过总线写到运算加速器(4/5/6步),在等到运算加速器运算完成后,内核将结果通过总线读到通用寄存器文件(7/8/9步),最后再将通用寄存器文件中的运算结果通过ld/st指令写到数据存储器中(10/11/12步),完成函数的返回。
4、一般对于3 2位处理器,1/2/3步需要2个l d执行周期+至少1个总线周期,4/5/6步需要2个s t周期+至少1个总线周期,7/8/9步需要2个ld周期+至少1个总线周期,10/11/12步是回写结果需要2个s t指令周期+至少1个总线周期,运算加速这里假设是8个周期。对于c语言的函数传递/返回,有特定的通用寄存器文件使用规则,因此这里还会有通用寄存器文件之间的数据传递(至少4个周期)。这样完成一个除法运算,至少需要2 8个周期,其中实际运算加速只占8个周期,其他时间都是花在数据传递上。对于基础运算的扩展(乘法/乘加/除法/开方/余弦函数),一般都会在1 0个周期内完成,这样数据传递所消耗的代价就比较大。特别是对于8位处理器,数据传输效率更低,因此对于8位处理的运算扩展,其效率将远远低于32位设计。
5、总体而言,传统的实现方式中,真正运算加速的时间在整个过程中的时间占比较小、即效率并不高。
技术实现思路
1、为解决上述问题,本申请提供一种运算加速架构,通过将运算加速器耦合到控制器内核的寄存器文件上,使得执行单元存入寄存器的数据可以直接进入运算加速器,减少寄存器数据进入运算加速器或从运算加速器返回的步骤,提高运算时间在整个流程中的占比,即提高运算加速的效率。
2、为达到上述目的,本申请采取的技术方案如下:
3、一种运算加速架构,包括:
4、控制器内核;所述控制器内核包括执行单元和寄存器;所述寄存器中设有若干寄存器文件;所述执行单元与所述寄存器文件连接以读写指令或数据;
5、选择器;所述选择器与所述执行单元连接,以接收执行单元的选通指令;所述选择器与所述寄存器文件连接,以根据选通指令选通需要的寄存器文件;
6、运算加速器;所述运算加速器与所述选择器连接,以接收所述选择器选通的寄存器文件的数据,进行加速运算后返回计算结果。
7、进一步的,所述选择器与所述寄存器文件采用直接耦合连接结构。
8、进一步的,所述选择器位于所述寄存器内。
9、进一步的,所述选择器位于所述运算加速器内。
10、一种运算加速系统,包括数据存储器、数据总线和如上所述的运算加速架构;所述数据存储器用于存储程序及数据;所述数据总线分别与所述执行单元和数据存储器连接,以使执行单元通过数据总线与所述数据存储器进行数据交互。
11、一种运算加速系统使用方法,应用于如上所述的运算加速系统,具体包括如下步骤:
12、根据编译器规范确定当前编译器使用的临时存放数据的寄存器文件;
13、根据使用的寄存器文件发送相应的选通指令配置选择器;
14、选择器选通当前使用的寄存器文件,以使当前使用的寄存器文件直接与运算加速器建立连接;
15、运算加速器接收选通寄存器文件的数据并进行运算;
16、运算结束,运算加速器将运算结果传递到选通的寄存器文件。
17、进一步的,所述运算加速器将运算结果传递到选通的寄存器文件时,运算结果会直接更新到编译器规范指定的函数返回值寄存器文件,避免多余的寄存器文件之间数据复制或传递。
18、进一步的,所述编译器规范采用abi规范。
19、进一步的,所述运算加速系统使用方法还包括以下步骤:
20、执行单元读取运算结果并通过数据总线保存到数据存储器中。
21、进一步的,所述运算加速系统使用方法还包括以下步骤:
22、执行单元读取数据存储器中的数据,并存入当前编译器使用的寄存器文件。
23、本申请提供一种运算加速架构,包括:控制器内核;所述控制器内核包括执行单元和寄存器;所述寄存器中设有若干寄存器文件;所述执行单元与所述寄存器文件连接以读写指令或数据;选择器;所述选择器与所述执行单元连接,以接收执行单元的选通指令;所述选择器与所述寄存器文件连接,以根据选通指令设置选通需要的寄存器文件;运算加速器;所述运算加速器与所述选择器连接,以接收所述选择器选通的寄存器文件的数据,进行加速运算后返回计算结果。通过使用一个选择器,在寄存器文件和硬件的运算加速器之间建立一个快速通道,使得在进行加速运算时,寄存器文件的数据不用再通过执行单元、数据总线才到运算加速器,运算加速器的数据也不用经过数据总线和执行单元才能返回寄存器文件,寄存器文件的数据可以直接进入运算加速器,或者运算加速器的数据可以直接进入寄存器文件,减少了执行周期、提高了工作效率。同时,选择器通过直接选通当前编译器使用的寄存器文件,免除了寄存器文件之间的数据传递,进一步提高了数据传输效率。
技术特征:
1.一种运算加速架构,其特征在于,包括:
2.根据权利要求1所述的运算加速架构,其特征在于,所述选择器与所述寄存器文件采用直接耦合连接结构。
3.根据权利要求1所述的运算加速架构,其特征在于,所述选择器位于所述寄存器内。
4.根据权利要求1所述的运算加速架构,其特征在于,所述选择器位于所述运算加速器内。
5.一种运算加速系统,其特征在于,包括数据存储器、数据总线和如权利要求1至4任一项所述的运算加速架构;所述数据存储器用于存储程序及数据;所述数据总线分别与所述执行单元和数据存储器连接,以使执行单元通过数据总线与所述数据存储器进行数据交互。
6.一种运算加速系统使用方法,其特征在于,应用于如权利要求5所述的运算加速系统,具体包括如下步骤:
7.根据权利要求6所述的运算加速系统使用方法,其特征在于,所述运算加速器将运算结果传递到选通的寄存器文件时,运算结果会直接更新到编译器规范指定的函数返回值寄存器文件,避免多余的寄存器文件之间数据复制或传递。
8.根据权利要求6所述的运算加速系统使用方法,其特征在于,所述编译器规范采用abi规范。
9.根据权利要求6所述的运算加速系统使用方法,其特征在于,还包括以下步骤:
10.根据权利要求6所述的运算加速系统使用方法,其特征在于,还包括以下步骤:
技术总结
本申请提供一种运算加速架构,包括:控制器内核;所述控制器内核包括执行单元和寄存器;所述寄存器中设有若干寄存器文件;所述执行单元与所述寄存器文件连接以读写指令或数据;选择器;所述选择器与所述执行单元连接,以接收执行单元的选通指令;所述选择器与所述寄存器文件连接,以根据选通指令设置选通需要的寄存器文件;运算加速器;所述运算加速器与所述选择器连接,以接收所述选择器选通的寄存器文件的数据,进行加速运算后返回计算结果。通过使用一个选择器,在寄存器文件和硬件的运算加速器之间建立一个快速通道,使得在进行加速运算时减少了执行周期、提高了工作效率。
技术研发人员:周防,黄泽军
受保护的技术使用者:深圳市锐骏半导体股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!