一种基于多层分组聚合的横向联邦学习故障检测方法
本发明属于横向联邦学习,尤其适用于解决工业系统故障检测中的数据异质、数据存储及数据修改的问题,为一种基于多层分组聚合的横向联邦学习故障检测方法。
背景技术:
1、在当代制造业中,设备是制造业生产的核心。故障检测是提高机电设备安全性的重要技术,不仅可以预测早期故障、避免恶性事故的发生;还可以从根本上解决设备定期维修中的维修不足和过剩维修的问题。然而,由于传感器的多样性、不稳定网络通信、非独立分布且数据异质等问题,模型建立过程中企业敏感数据泄漏、模型易受差分攻击等一系列问题,从而导致样本质量低下、难以分析和利用。随着时间的推移,人们对数据安全、数据隐私的需求越来越迫切,在不同组织间收集和分享数据将会变得越来越困难。因此,在工业故障检测的应用中,有必要解决数据模型的异质性问题。
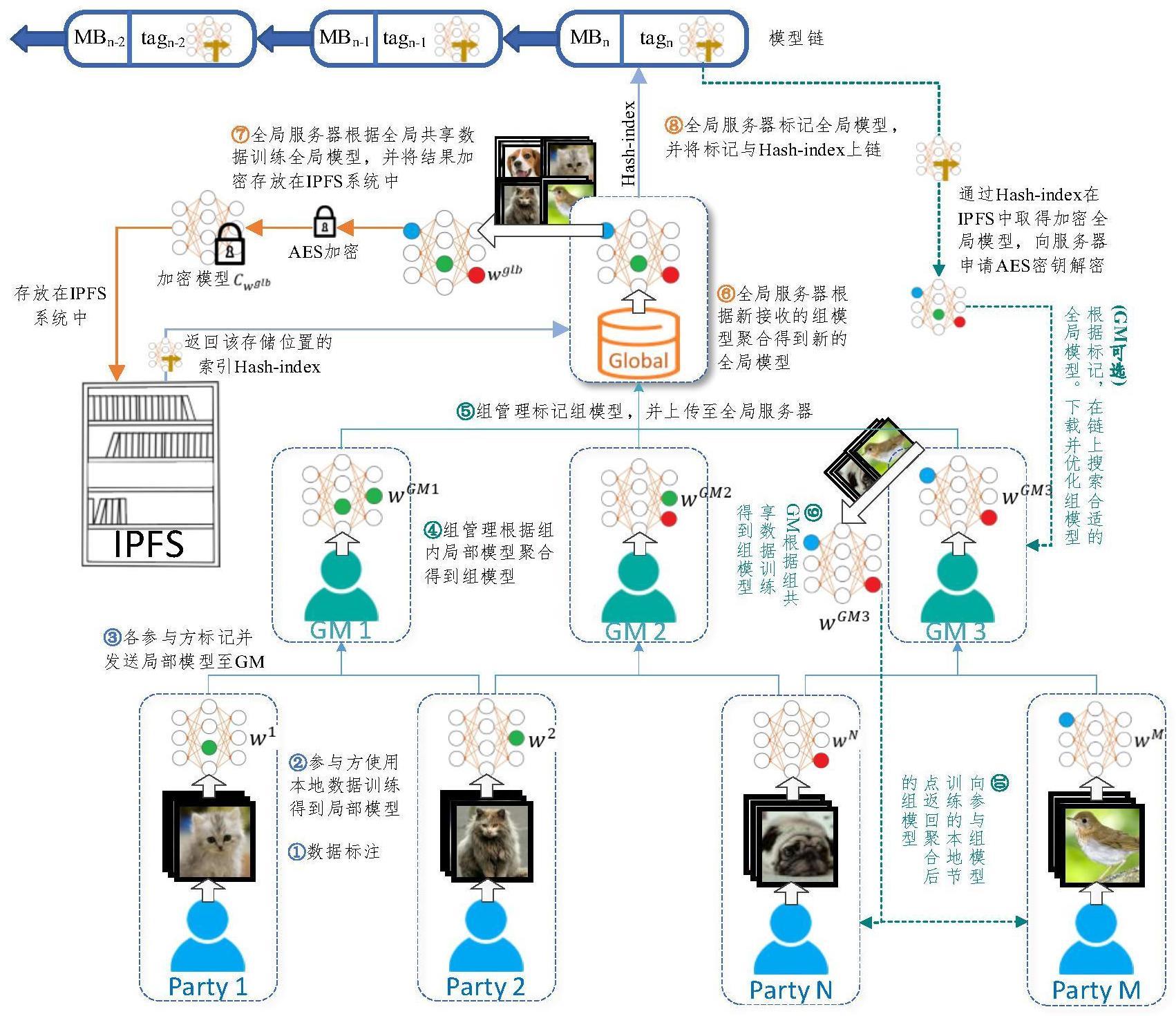
2、在故障检测的模型训练中,按照地理位置与样本数据的相似性对本地数据进行分类,为其分配参与方进行初步的局部模型训练,各参与方标记后发送给组管理;组管理训练局部模型聚合得到组模型,发送给全局服务器;全局服务器在对组模型进行聚合得到全局模型。
3、当系统在训练横向联邦学习的过程中,需要考虑到每一部分学习的角色、模型的存储、修改和数据的隐私性,可将全局服务器训练出来的全局模型加密后存储在星际文件系统(interplanetary file system,ipfs)上,存储后ipfs会返回一个哈希索引,用来访问该存储位置,将哈希索引存储上链。当组管理需要修改模型的访问控制权限时,可向全局服务器提交申请,由组管理使用变色龙哈希对密钥链上的密钥值进行修改。在此过程中,为保证哈希数据的安全存储和修改,关键时要允许全局服务器拥有所有的哈希解密密钥,防止组管理对数据的随意修改。
技术实现思路
1、为了克服上述现有技术的不足,达到上述情景的需求,本发明的目的在于提供一种基于多层分组聚合的横向联邦学习故障检测方法。基于多层分组聚合的理论,对联邦学习参与节点进行“参与方-组管理-全局服务器”三层分类,再将各层级相似标签的数据进行聚合训练,最后将训练模型加密存储在ipfs中并将标签的密钥存储在区块链上。利用变色龙哈希函数,在不改变哈希值的情况下,可对区块链上的密钥信息进行修改。通过此方法可提高模型训练的精度,降低通信开销,实现了区块链上的数据编辑与撤销。
2、为了实现上述目的,本发明采用的技术方案是:
3、一种基于多层分组聚合的横向联邦学习故障检测方法,定义三种角色,分别为参与方、组管理和全局服务器,其特征在于,包括如下步骤:
4、步骤1,获取与故障相关的图像数据集,进行数据标注;
5、步骤2,各参与方使用本地数据训练得到其局部模型;所述参与方是联邦学习系统中进行局部训练的客户端;根据地理位置与样本数据的相似性,分配不同的参与方同步进行局部模型训练,各参与方之间的训练相互独立;
6、步骤3,各参与方标记并发送局部模型至组管理;所述组管理是根据共识算法选举出的拥有更高算力的节点,负责聚合区域相近的客户端提供的局部模型;
7、步骤4,组管理根据组内局部模型聚合得到组模型;
8、步骤5,组管理标记组模型并上传至全局服务器;
9、步骤6,全局服务器根据新接收的组模型聚合得到全局模型,即故障预测模型;
10、步骤7,全局服务器根据全局共享数据训练所述全局模型,并将结果加密存放在ipfs系统中;
11、步骤8,全局服务器标记全局模型,并将标记与hash-index上链;
12、步骤9,通过hash-index在ipfs中取得加密全局模型,向服务器申请aes密钥解密;根据标记,在链上搜索合适的全局模型下载并优化组模型。
13、假设u为某一正整数,表示模型训练组内的所有成员,记符号w表示横向联邦学习过程中的模型,则第i个参与方训练的本地模型为wi,其中i∈u。假设t为某一正整数,表示模型训练的最大轮数,当训练轮数为第k轮时,记模型符号为wk,其中,k∈[0,t]。记符号wi,k为第i个参与方训练的第k轮数据模型,当第k轮模型训练轮数增加一轮时,记模型符号为wk+1,则记wi,k+1为第i个参与方训练的第k+1轮数据模型。记符号glb表示全局服务器,符号gm表示组管理,符号wglb表示全局服务器训练模型,表示第k轮全局服务器的训练模型,表示第i个参与方第k轮全局服务器的训练模型,符号wgm为组管理的训练模型。假设d为某一正整数集合,表示模型训练中的数据集,令第i个参与方训练的本地数据集为di,γ为贡献值,则记γi,k为第i个参与方第k轮的贡献值,其中γi,k+1∈[0,1)。kl(·)为kl(kullback-leibler divergence)散度函数,用来描述wk与wk+1模型间的差异;ds(·)为证据理论融合函数,用来计算贡献值的评分,则:其中|·|表示计算集合中的个数,为参与方i的数据集比重。根据全局模型聚合理论,提出了新的模型训练方法:
14、基于标签的自适应模型匹配策略,组模型可以匹配到更适合自己的全局模型,提高了组模型的收敛效率;根据地理分布与预测任务的属性划分,利用“同层组内同步-三层组间异步”同步异步相结合的方法,数据异质性与设备异质性的问题得到了改善;采用区块链双链结构与联邦学习相结合,公链存放训练模型的哈希索引,私链存放解密模型所需要的密钥,实现了数据公开透明原则的同时,保护了模型数据的隐私,解决了传统(异步)联邦学习中产生的资源浪费。
15、与现有技术相比,该方法可提供如下方面的效率优势和安全性:
16、1)基于标签的自适应模型匹配策略,组模型可以匹配到更适合自己的全局模型,提高了组模型的收敛效率。
17、2)根据地理分布与预测任务的属性划分,利用“同层组内同步-三层组间异步”相结合的多层先分组再聚合的横向联邦学习故障检测方法,数据异质性与设备异质性的问题得到了改善,提高了通信效率。
18、3)全局服务器将哈希值索引与标签进行区块链上链操作,组管理结合变色龙哈希函数对区块链上的信息进行修改,实现了区块链数据的可撤销性;
19、4)采用区块链双链结构,公链存放训练模型的哈希索引,私链存放解密模型所需要的密钥。
技术特征:
1.一种基于多层分组聚合的横向联邦学习故障检测方法,定义三种角色,分别为参与方、组管理和全局服务器,其特征在于,包括如下步骤:
2.根据权利要求1所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤1,采用severstal带钢缺陷的图像数据集,第i个参与方partyi对其本地数据进行包括图像压缩、分割,几何变换的预处理后得到固定规格的图像并进行标注,将所有信息存放在本地故障检测数据集中。
3.根据权利要求2所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤2,获取局部模型的方法如下:
4.根据权利要求3所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤3,假设d为某一正整数集合,表示故障检测局部参与方模型训练中的图像数据集,记为本地图像数据集,第i个参与方训练的图像数据集为di,第i个参与方训练的组内共享数据集为符号假设acc为某一小数,acc∈[0,1],表示准确率;当partyi的损失值li(w)满足条件或训练轮次已达到最大轮次时停止训练。在系统初始化和新节点加入系统阶段,系统参照模型的地理位置与预测目标对模型中的各个图像进行属性划分。
5.根据权利要求4所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤4,记wi,t表示故障检测局部参与节点i的经过t轮后的训练模型,组管理接收到所有组内参与方发送的局部模型wi,t与标签tag后,将其组内所有局部模型平均聚合得到组模型其中|·|表示计算集合中的个数,∑i∈uwi,t表示对组内最后一轮的局部模型进行求和运算。
6.根据权利要求4所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤5,组管理按照出现次数降序排列所有参与方发送的标签tag,仅保留前|u|个出现次数最多的标签tag并记为taggm,将组模型wgm与组标签taggm一起发送至全局服务器。
7.根据权利要求1所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤6,当训练轮数为第k轮时,记模型符号为wk,其中,k∈[0,t],记符号wi,k为第i个参与方训练的第k轮数据模型,当第k轮模型训练轮数增加一轮时,记模型符号为wk+1,记符号表示第k轮全局服务器的训练模型,则记wi,k+1为第i个参与方训练的第k+1轮数据模型;每当全局服务器接收到一个组管理发送的组模型wgm与组标签taggm时,在区块链上根据taggm寻找适配于该组模型的全局模型假设d为某一正整数集合,令第i个参与方训练的本地数据集为di,记符号γ为贡献值,则符号γi,k表示为故障检测模型中第i个参与方第k轮的贡献值,符号γi,k+1表示为第i个参与方第k+1轮的贡献值,其中γi,k∈[0,1)、γi,k+1∈[0,1);kl(·)表示kl(kullback-leibler divergence)散度函数,用来描述wk与wk+1模型间的差异;ds(·)为证据理论融合函数,用来计算贡献值的评分,则:其中|·|表示计算集合中的个数,则为参与方i的数据集比重;为提高模型训练精度,根据全局模型聚合理论,得到新的全局模型:
8.根据权利要求1所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤7,设x为某一整数,表示局部故障检测训练图像的编号,x∈[0,m],m表示故障检测数据集中图像的总数量,样本的数量,y为样本x的真实标签;记符号为模型wi,k关于故障检测图像样本x的预测值,lsup为故障检测的全局图像样本在模型训练中的交叉熵损失函数,其计算如下:记符号r为故障检测的全局模型特征,符号rgm为组模型特征,符号rgm-为组模型上一轮特征,sim(.)为余弦相似度函数,τ为某一常数,表示温度系数,lcon为额外定义的用来衡量故障检测中全局模型与组模型特征距离的损失函数,其计算如下:记符号dglb表示全局共享工业故障检测图像的数据集,符号dgm表示组共享数据集,符号lglob表示全局模型训练的损失值,arg min lglob表示在全局模型训练的过程中,使损失函数取最小值时的lsup和lcon变量值的最小值;通过sgd训练得到新的全局模型wglb;全局sgd的目标为最小化复合损失函数arg min lglob=lsup+lcon。
9.根据权利要求1所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤8,记符号tagglb为全局模型预测任务类型的标签;当损失值lglob满足条件或训练轮次已达到最大轮次时,停止训练;若该组管理贡献值大于参与该全局模型训练的其他组管理的平均贡献值,则全局服务器按照组标签taggm在前、全局标签tagglb在后的方式组合两种标签并重新排列,得到新的全局标签tagglb;否则将按照组标签taggm在后的方式排列;假设用符号c表示密文信息,表示全局模型加密后的密文,全局服务器将新的全局模型wglb使用组管理的私钥加密得到密文将密文存储在ipfs系统中并获得存储位置索引hash-index;全局模型将hash-index与新的全局标签tagglb,上传至模型链mbc上。
10.根据权利要求1所述基于多层分组聚合的横向联邦学习故障检测方法,其特征在于,所述步骤9,包括:
技术总结
在工业系统故障检测领域中,由于设备异构与故障数据分布有偏等情况,联邦学习经常会出现不稳定网络通信和数据异质等现实问题。因此如何融合不同参与方的异质数据并建立一种积极有效的学习模型显得至关重要。本发明提供了一种基于多层分组聚合的横向联邦学习故障检测方法,通过对联邦学习结构的部分修改,降低了数据异质性与设备异构性带来的联邦学习精度损失与通信开销。实验分析表明,与其他相关工作相比,此方法验证了多层联邦学习聚合方法的可行性和有效性,为联邦学习的聚合架构提供了一种新的设计思路。
技术研发人员:王鑫,师鹏柔,张昊基,吴浩宇
受保护的技术使用者:陕西科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!