一种文本数据实体关系联合抽取方法及系统与流程
本公开涉及文本数据处理领域,具体涉及一种文本数据实体关系联合抽取方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
2、随着互联网的不断发展,每时每刻都会产生海量的文本数据,如微博、博客和新闻等都会产生大量的非结构化文本信息,而如何从其中提取出结构化信息,为后续的数据挖掘和数据分析带来便利,则是亟待解决的问题。为了满足这类需求,信息抽取应运而生。信息抽取的核心子任务是命名实体识别和关系抽取,命名实体识别是在待处理文本中提取出可能存在的命名实体对,关系抽取是提取出实体对可能存在的关系,最终整合为<头实体,关系,尾实体>的三元组。
3、目前最常见的信息抽取方式是联合抽取,对于联合抽取模型,目前主要有两大类别:共享参数的联合抽取模型和联合解码的联合抽取模型。绝大多数的研究都是基于共享参数模型的,makoto等使用依存结构树先抽取实体,再进行softmax关系分类,katiyar引入了指针网络,zeng引入了copy机制和seq2seq,但这些方法应对三元组重叠问题的效果并不十分显著,而且计算量比较大。对于这一问题,bekoulis等指出了当前联合抽取存在的两个瓶颈,即:目前联合抽取模型依赖外部的nlp工具提取特征,模型性能严重依赖nlp工具的性能;之前的工作没有考虑实体关系重叠问题。于是提出了一个多头选择模型,将实体关系联合抽取问题看作是一个多头选择问题(multi-head selection)的问题,即任何一个实体都可能与其他实体存在关系,目的是解决关系重叠问题,从而使得每个实体能够与其他所有实体判断关系,此外,不再将关系抽取任务当作一个每个关系互斥的多分类任务,而是看作每个关系独立的多个二分类任务,从而能够判断每一对实体是否可能有多个关系存在。通过使用sigmoid损失来预测多个关系,使用crf来预测实体。通过这种方式,能够独立地预测不互斥的类,而不是在标记之间分配相等的概率值。尽管当前的实体关系抽取取得了很显著的研究进展,但仍旧有实体重叠、误差累计传播和实体关系抽取任务联系不够紧密等问题。
技术实现思路
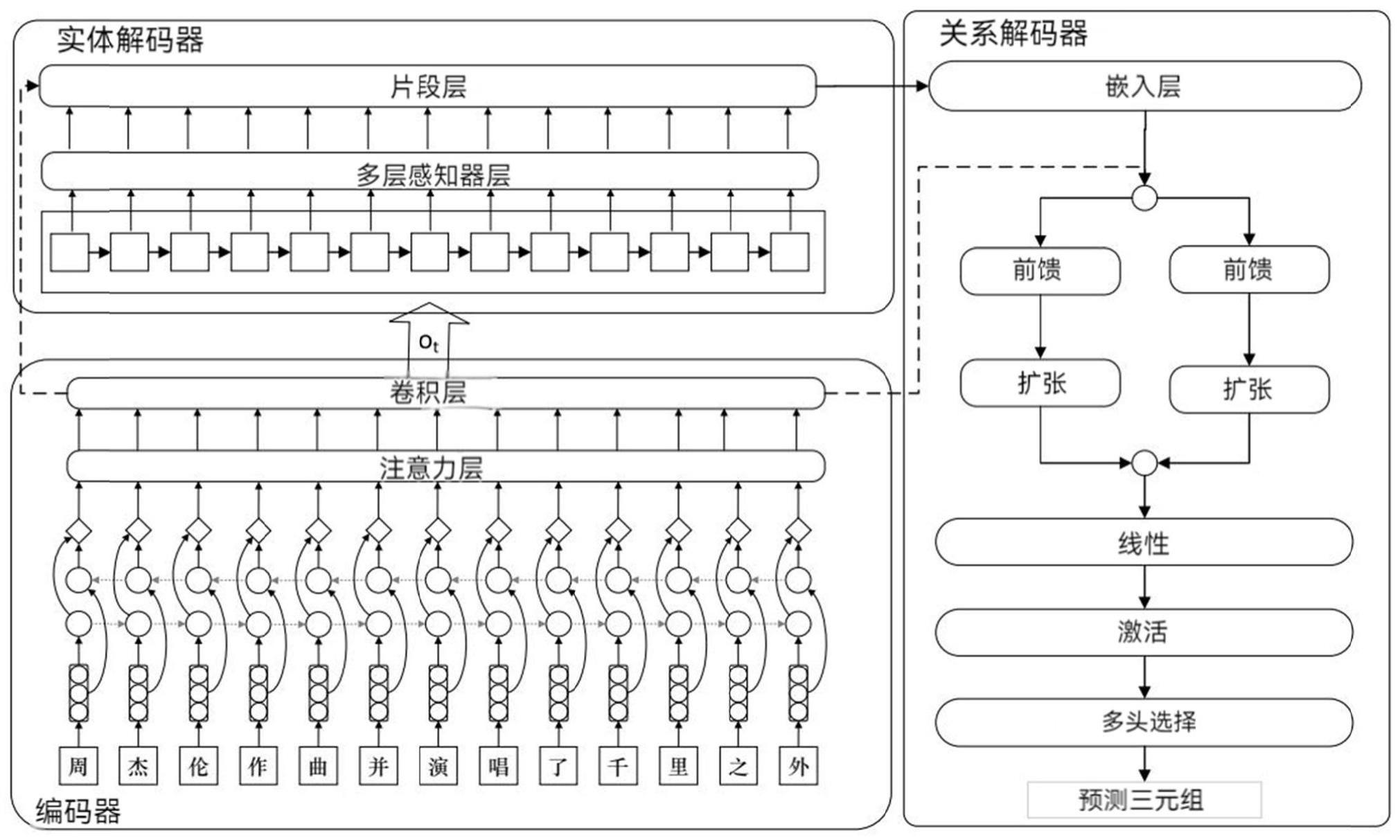
1、本公开为了解决上述问题,提出了一种文本数据实体关系联合抽取方法及系统,提出一种基于片段排列与多头选择的联合抽取模型,将实体识别与关系识别共享编码层;采用片段排列与多头选择的联合抽取结构,实体识别采用片段排列的方法,以片段作为基本单位来进行抽取,由注意力机制(attention)生成特征之后再进行类别判断,解决实体重叠问题。
2、根据一些实施例,本公开采用如下技术方案:
3、一种文本数据实体关系联合抽取方法,包括:
4、获取待抽取的文本语句,对文本语句转换为离散文本序列,再将文本序列划分为连续的分词,将一段连续的分词作为一个集合,该集合为一个片段;
5、以片段作为基本单位,先通过枚举,获取所有可能出现的实体,采用注意力机制提取语义特征之后进行类别判断,获取实体识别的结果;
6、提取片段的语义特征向量,将实体识别的结果与语义特征向量进行拼接,经过全连接层后得到实体向量,再进行一次拼接得到关系矩阵,最后通过激活函数计算出实体在各个关系类别上的分布概率,由此获取实体关系的分类。
7、根据一些实施例,本公开采用如下技术方案:
8、一种文本数据实体关系联合抽取系统,包括:
9、数据获取模块,用于获取待抽取的文本语句,对文本语句转换为离散文本序列,再将文本序列划分为连续的分词,将一段连续的分词作为一个集合,该集合为一个片段;
10、联合抽取模块,用于以片段作为基本单位,先通过枚举,获取所有可能出现的实体,采用注意力机制提取语义特征之后进行类别判断,获取实体识别的结果;
11、提取片段的语义特征向量,将实体识别的结果与语义特征向量进行拼接,经过全连接层后得到实体向量,再进行一次拼接得到关系矩阵,最后通过激活函数计算出实体在各个关系类别上的分布概率,由此获取实体关系的分类。
12、根据一些实施例,本公开采用如下技术方案:
13、一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行所述的一种文本数据实体关系联合抽取方法。
14、根据一些实施例,本公开采用如下技术方案:
15、一种终端设备,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行所述的一种文本数据实体关系联合抽取方法。
16、与现有技术相比,本公开的有益效果为:
17、本公开中提出了一种新的基于片段排列与多头选择机制的联合抽取模型,实体抽取和关系抽取共用编码层,实体抽取采用片段排列,从span的层面来解决实体重叠问题,关系抽取采用改良的多头选择机制来预测关系,最终通过损失函数来辅助信息抽取任务。解决了实体重叠、误差累计传播和实体关系抽取任务联系不够紧密的问题。
技术特征:
1.一种文本数据实体关系联合抽取方法,其特征在于,包括:
2.如权利要求1所述的一种文本数据实体关系联合抽取方法,其特征在于,利用双向长短期记忆网络将初始的文本语句转化为离散文本序列向量表示,文本语句中每一个字都有对应的向量进行表示。
3.如权利要求2所述的一种文本数据实体关系联合抽取方法,其特征在于,根据每一个文本语句中的每一个字所对应的向量表示建立一个字典查找表,通过每个字的索引来查询对应的向量表示,并在训练的过程中不断更新所述字典查找表。
4.如权利要求1所述的一种文本数据实体关系联合抽取方法,其特征在于,以片段作为基本单位,通过设置一个长度阈值参数来对长度进行限制,不同的片段长度不同,采用最大池化来进行维度对齐,获取维度对齐后的片段。
5.如权利要求1所述的一种文本数据实体关系联合抽取方法,其特征在于,对每个片段的实体类型进行识别,对每一个片段进行相同且平行的预测,对于每个片段,计算出该片段对于所有实体类型的分数,之后分配给该片段分数最高的实体。
6.如权利要求5所述的一种文本数据实体关系联合抽取方法,其特征在于,对于每个片段,利用softmax函数获得实体类型的分布,分数计算如下:
7.一种文本数据实体关系联合抽取系统,其特征在于,,包括:
8.如权利要求7所述的一种文本数据实体关系联合抽取系统,其特征在于,利用双向长短期记忆网络将初始的文本语句转化为离散文本序列向量表示,文本语句中每一个字都有对应的向量进行表示。
9.一种计算机可读存储介质,其特征在于,其中存储有多条指令,所述指令适于由终端设备的处理器加载并执行权利要求1-6中任一项所述的一种文本数据实体关系联合抽取方法。
10.一种终端设备,其特征在于,包括处理器和计算机可读存储介质,处理器用于实现各指令;计算机可读存储介质用于存储多条指令,所述指令适于由处理器加载并执行如权利要求1-6中任一项所述的一种文本数据实体关系联合抽取方法。
技术总结
本公开提供了一种文本数据实体关系联合抽取方法及系统,涉及文本数据处理领域,方法包括获取待抽取的文本语句,对文本语句转换为离散文本序列,再将文本序列划分为连续的分词,将一段连续的分词作为一个集合,该集合为一个片段;以片段作为基本单位,先通过枚举,获取所有可能出现的实体,采用注意力机制提取语义特征之后进行类别判断,获取实体识别的结果;提取片段的语义特征向量,将实体识别的结果与语义特征向量进行拼接,经过全连接层后得到实体向量,再进行一次拼接得到关系矩阵,最后通过激活函数计算出实体在各个关系类别上的分布概率,由此获取实体关系的分类。
技术研发人员:郭俞,王馨莹,徐诗渊,陈凌曜,陈雷,田犁,祝永新,郑小盈,汪辉
受保护的技术使用者:上海核工程研究设计院股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!