一种模型无关的多模态情感分析方法
本申请属于多模态情感分析,尤其涉及一种模型无关的多模态情感分析方法。
背景技术:
1、随着社交媒体的蓬勃发展,人们表达自己观点的方式也越来越多。相较于从前较为单一的文字表述而言,现代的人们更乐于使用视频的方式来向其他人传达自己的情感。因此,如何利用视频中面部的表情、音调高低以及语言表述等这些多模态信息来更为准确地分析情感,仍是当前一个重要的挑战。
2、现有的多模态情感分析工作大多致力于不同模态之间的融合,从而得到一个统一的多模态表征来预测最终的情感。尽管,这些工作已经在多模态情感分析任务上取得了非常好的效果,但忽略了神经网络本身所建立的多模态数据和情感标签之间的虚假相关性。所以,当测试数据集的分布有所改变时,这些方法往往表现得就不尽如人意。因此,如何能让多模态情感分析模型真正地理解多模态数据,而不是利用数据集本身的分布来做出情感预测,仍是一个十分具有挑战性的问题,依然具有很强的理论和应用价值。
3、目前,随着因果推理在深度学习中的应用和发展,多模态情感分析领域中也出现了使用反事实推理手段来缓解多模态数据和情感标签之间虚假相关性的工作。然而,这一工作的框架只考虑了文本模态和情感标签之间存在的虚假相关,却并没有考虑其他非文本模态和情感标签之间所带来的影响。因此,在分布外的多模态情感分析任务中,仅仅考虑文本模态的虚假相关,仍然是不够的。
技术实现思路
1、本申请的目的是提供一种模型无关的多模态情感分析方法,该方法解决了各个模态与情感标签之间的虚假相关性,克服先前工作只单纯缓解文本模态与情感标签之间的虚假相关性的问题,以及进一步提升最终的情感分析性能。
2、为了实现上述目的,本申请技术方案如下:
3、一种模型无关的多模态情感分析方法,包括:
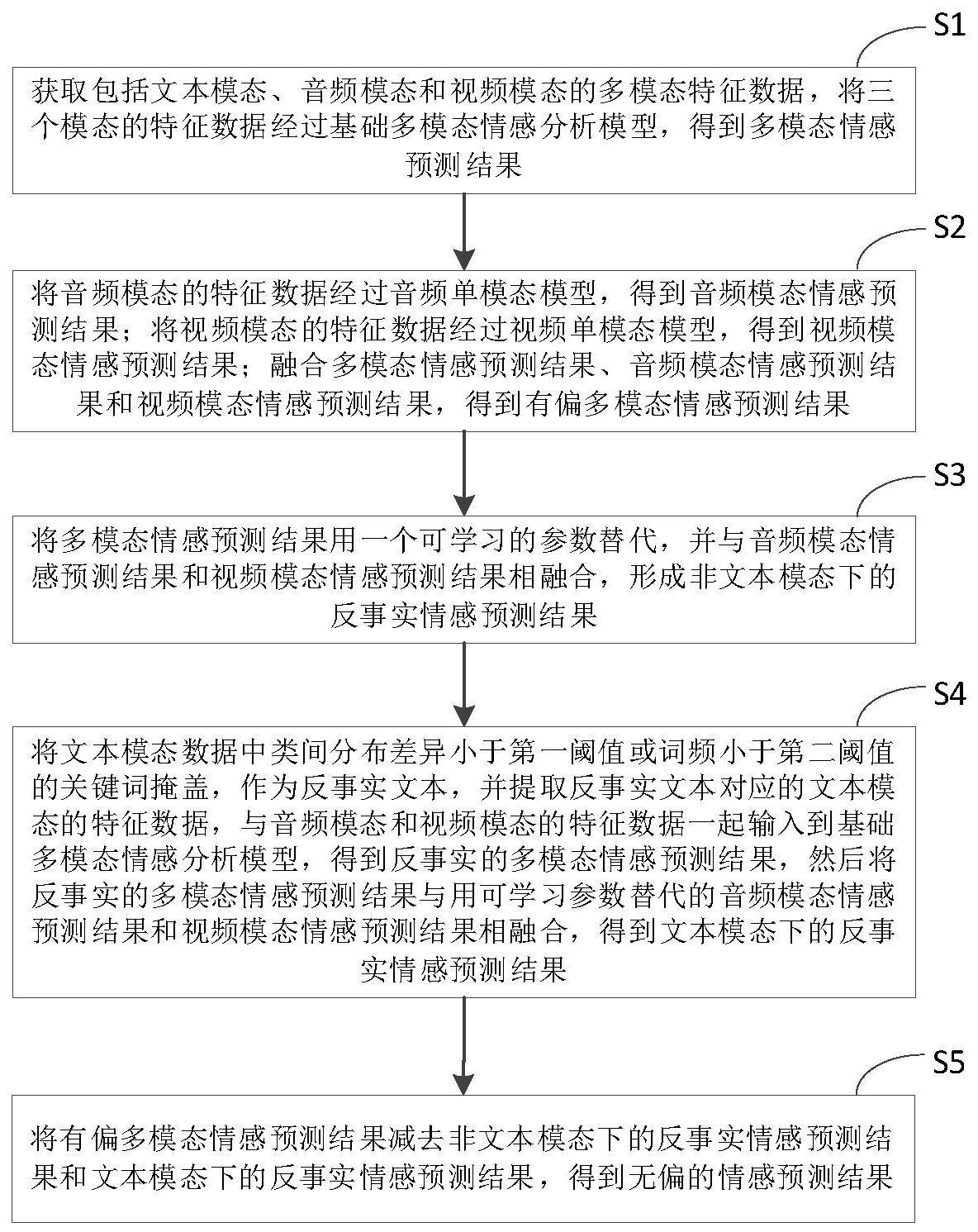
4、获取包括文本模态、音频模态和视频模态的多模态特征数据,将三个模态的特征数据经过基础多模态情感分析模型,得到多模态情感预测结果;
5、将音频模态的特征数据经过音频单模态模型,得到音频模态情感预测结果;将视频模态的特征数据经过视频单模态模型,得到视频模态情感预测结果;融合多模态情感预测结果、音频模态情感预测结果和视频模态情感预测结果,得到有偏多模态情感预测结果;
6、将多模态情感预测结果用一个可学习的参数替代,并与音频模态情感预测结果和视频模态情感预测结果相融合,形成非文本模态下的反事实情感预测结果;
7、将文本模态数据中类间分布差异小于第一阈值或词频小于第二阈值的关键词掩盖,作为反事实文本,并提取反事实文本对应的文本模态的特征数据,与音频模态和视频模态的特征数据一起输入到基础多模态情感分析模型,得到反事实的多模态情感预测结果,然后将反事实的多模态情感预测结果与用可学习参数替代的音频模态情感预测结果和视频模态情感预测结果相融合,得到文本模态下的反事实情感预测结果;
8、将有偏多模态情感预测结果减去非文本模态下的反事实情感预测结果和文本模态下的反事实情感预测结果,得到无偏的情感预测结果。
9、进一步的,所述融合多模态情感预测结果、音频模态情感预测结果和视频模态情感预测结果,得到有偏多模态情感预测结果,采用公式表示如下:
10、
11、其中,h(za,zm,zv)表示有偏多模态情感预测结果,za表示音频模态情感预测结果,zv表示视频模态情感预测结果,zm表示多模态情感预测结果。
12、进一步的,所述将多模态情感预测结果用一个可学习的参数替代,并与音频模态情感预测结果和视频模态情感预测结果相融合,形成非文本模态下的反事实情感预测结果,采用公式表示如下:
13、
14、
15、其中,表示非文本模态下的反事实情感预测结果,za表示音频模态情感预测结果,zv表示视频模态情感预测结果,表示多模态情感预测结果用一个可学习的参数cm替代的结果。
16、进一步的,所述将反事实的多模态情感预测结果与用可学习参数替代的音频模态情感预测结果和视频模态情感预测结果相融合,得到文本模态下的反事实情感预测结果,采用公式表示如下:
17、
18、
19、
20、其中,表示文本模态下的反事实情感预测结果,z′m表示反事实的多模态情感预测结果,表示音频模态情感预测结果用一个可学习的参数ca替代的结果,表示视频模态情感预测结果用一个可学习的参数cv替代的结果。
21、进一步的,所述将有偏多模态情感预测结果减去非文本模态下的反事实情感预测结果和文本模态下的反事实情感预测结果,得到无偏的情感预测结果,采用公式表示如下:
22、
23、其中,表示无偏的情感预测结果,λ1、λ2分别为非文本模态下的反事实情感预测结果和文本模态下的反事实情感预测结果的权重,za表示音频模态情感预测结果,zv表示视频模态情感预测结果,zm表示多模态情感预测结果,h(za,zm,zv)表示有偏多模态情感预测结果。
24、进一步的,所述模型无关的多模态情感分析方法,还包括:
25、计算多模态情感预测结果、音频模态情感预测结果和视频模态情感预测结果的联合交叉熵损失,以及计算多模态情感预测结果有偏多模态情感预测结果与非文本模态下的反事实情感预测结果、有偏多模态情感预测结果与文本模态下的反事实情感预测结果的kl散度损失,进行基础多模态情感分析模型、音频单模态模型和视频单模态模型的联合训练。
26、本申请提出的一种模型无关的多模态情感分析方法,对于各种模态所带来的偏差,想象两种反事实情况:非文本模态反事实和文本模态反事实。对于非文本模态反事实,采用两个额外的单模态模型来捕获。而对于文本模态反事实,则采取将输入文本关键词中类间分布差异较小的单词掩盖,从而仅保留背景单词和类间分布差异较大的关键词,来作为反事实文本输入。本申请方法不仅能够在测试集分布和训练集、验证集一致的情况下,有较好的性能,并且在训练集、验证集和测试集分布不一致的情况下,也能够保持较高的情感分析准确率。
技术特征:
1.一种模型无关的多模态情感分析方法,其特征在于,所述模型无关的多模态情感分析方法,包括:
2.根据权利要求1所述的模型无关的多模态情感分析方法,其特征在于,所述融合多模态情感预测结果、音频模态情感预测结果和视频模态情感预测结果,得到有偏多模态情感预测结果,采用公式表示如下:
3.根据权利要求1所述的模型无关的多模态情感分析方法,其特征在于,所述将多模态情感预测结果用一个可学习的参数替代,并与音频模态情感预测结果和视频模态情感预测结果相融合,形成非文本模态下的反事实情感预测结果,采用公式表示如下:
4.根据权利要求1所述的模型无关的多模态情感分析方法,其特征在于,所述将反事实的多模态情感预测结果与用可学习参数替代的音频模态情感预测结果和视频模态情感预测结果相融合,得到文本模态下的反事实情感预测结果,采用公式表示如下:
5.根据权利要求1所述的模型无关的多模态情感分析方法,其特征在于,所述将有偏多模态情感预测结果减去非文本模态下的反事实情感预测结果和文本模态下的反事实情感预测结果,得到无偏的情感预测结果,采用公式表示如下:
6.根据权利要求1所述的模型无关的多模态情感分析方法,其特征在于,所述模型无关的多模态情感分析方法,还包括:
技术总结
本发明公开了一种模型无关的多模态情感分析方法,首先进行有偏多模态情感预测,然后对于非文本模态反事实,采用两个额外的单模态模型来捕获,得到非文本模态下情感预测结果。而对于文本模态反事实,则采取将输入文本关键词中类间分布差异较小的单词掩盖,从而仅保留背景单词和类间分布差异较大的关键词,来作为反事实文本输入,并最后得到文本模态下情感预测结果。最后将有偏多模态情感预测结果减去非文本模态下的情感预测结果和文本模态下的情感预测结果,得到无偏的情感预测结果。本发明能够保持较高的情感分析准确率。
技术研发人员:宦若虹,钟国伟,梁荣华
受保护的技术使用者:浙江工业大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!