一种基于改进Yolov4-tiny算法的交通标志检测方法
本发明涉及智能交通,特别是指一种基于改进yolov4-tiny算法的交通标志检测方法。
背景技术:
1、交通标志中蕴含着大量语义信息,即时检测远处的小目标交通标志可为自动驾驶决策系统提供更长反应时间,有效降低交通事故发生率,确保行车安全。因此,可靠即时的交通标志检测技术是当前汽车辅助驾驶系统的关键组成部分,在城市交通领域具有重要研究意义。
2、交通标志检测易受天气、阴影、光照强度变化等环境因素影响,是一种极具挑战性的小目标检测任务。目前,交通标志检测技术分为传统方法和基于深度学习的方法。首先,由于传统方法主要采用人工设计特征,具有一定的特征提取局限性,因此很难应用于实际交通标志检测任务中。其次,以更多的存储和计算能力开销为代价的基于深度学习的双阶段检测方法也不适用,因为交通标志检测任务通常部署在边缘网络或移动设备中。由于上述两种方法的缺点,基于深度学习的单阶段检测方法是目前比较理想的方法,因为它具有比传统方法更好的检测鲁棒性以及比双阶段检测算法更快的检测速度。但现有单阶段检测方法往往不能很好的兼顾模型轻量化与检测精度和速度,且没有考虑到特征融合过程中干扰信息对于多尺度特征表达的影响性,导致算法在复杂场景下交通标志检测效果不佳。此外,数据的质量对于深度学习算法而言也是至关重要的,它决定了模型在训练过程中对特征学习的好坏。
3、针对以上背景问题,对交通标志检测的研究需要提高对小目标检测的精度,并且兼具模型的轻量化及实时性。此外,如何合理构建高质量数据集也是所需考虑的关键问题之一。
技术实现思路
1、针对上述背景技术中存在的不足,本发明结合交通标志图像的特点,提出了一种基于改进yolov4-tiny算法的交通标志检测方法,解决了复杂场景下交通标志检测效果不佳的技术问题。
2、本发明的技术方案是这样实现的:
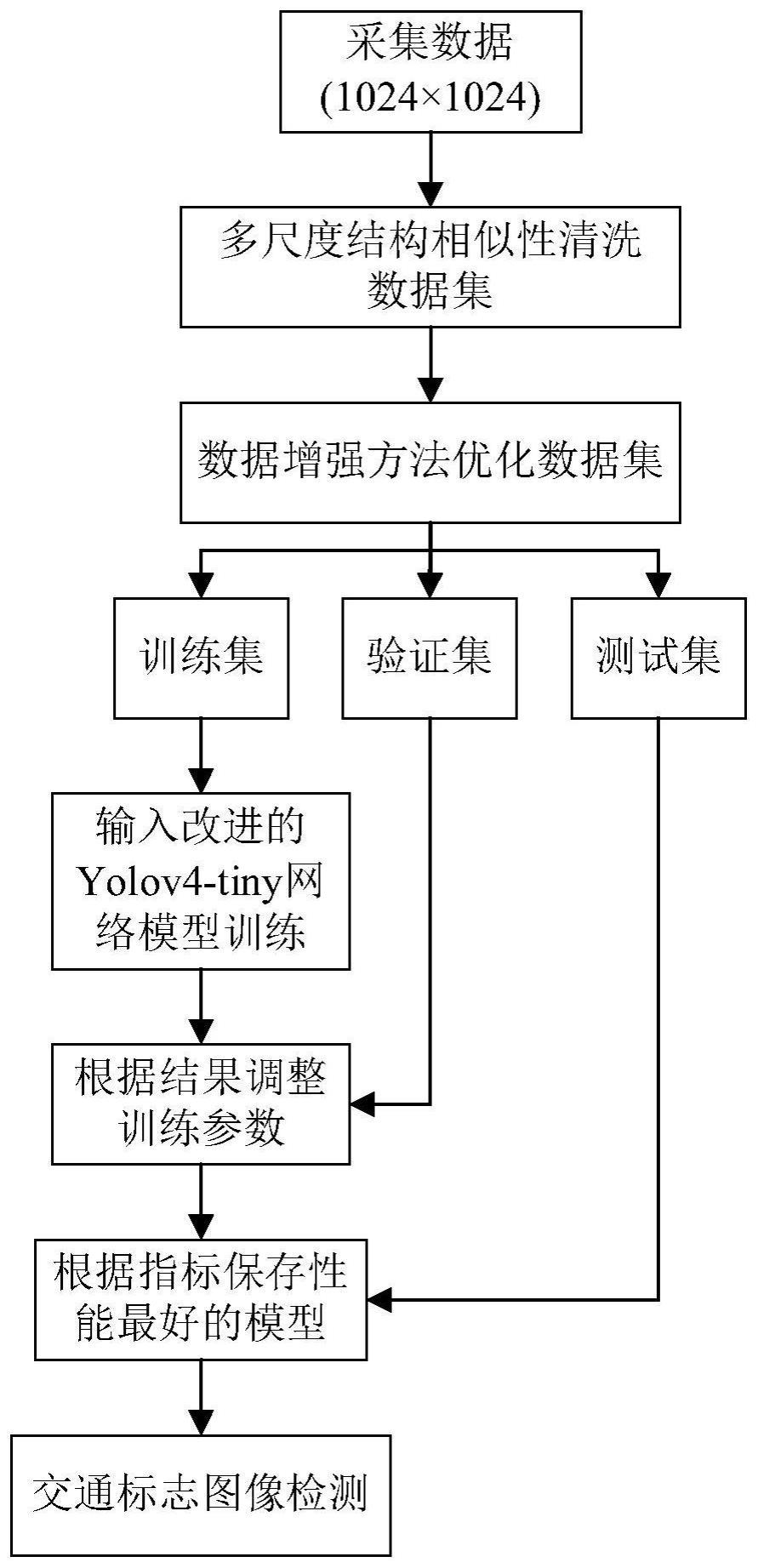
3、一种基于改进yolov4-tiny算法的交通标志检测方法,其步骤如下:
4、s1、采集不同地点、时间、天气下的交通标志图像,使用labelimg软件对交通标志图像进行标注,并对标注后的交通标志图像进行预处理,得到交通标志数据集;将交通标志数据集划分为训练集、验证集和测试集;
5、s2、构建改进yolov4-tiny算法的卷积神经网络模型:将高效层聚合轻量型模块(e-dsc)作为基础模块构建新的主干网络,将特征提纯复用结构(eerm)替换fpn特征融合结构,在主干网络末端增加轻量级感受野模块(s-rfb);
6、s3、将训练集和验证集输入改进yolov4-tiny算法的卷积神经网络模型中进行训练,选用adam优化器进行优化,通过余弦退火法调整学习率,通过观察训练过程中改进yolov4-tiny算法的卷积神经网络模型在验证集上的性能,调整训练超参数值,以进行最优训练;
7、s4、将测试集输入至训练后的改进yolov4-tiny算法的卷积神经网络模型中进行性能测试,根据评价指标保存性能最好的卷积神经网络检测模型;并利用卷积神经网络检测模型对交通标注图像进行检测。
8、优选地,所述对标注后的交通标志图像进行预处理包括相似数据清洗和数据增强;
9、相似数据清洗的方法为:每次从数据集中读取n张图片,通过多尺度结构相似性(ms-ssim)方法将第一张图片与其它n-1张图片进行相似度计算,设定相似度阈值,剔除高于所设定阈值的图片,保留低于所设定阈值的图片;其中,ms-ssim方法的计算公式为:
10、
11、其中,αm表示亮度相似性的重要性参数,βj表示对比度相似性的重要性参数,γj表示结构相似性的重要性参数;lm(x,y)表示图像x和y的亮度相似性,cj(x,y)表示图像x和y的对比度相似性,sj(x,y)表示图像x和y的结构相似性;其计算公式分别为:
12、
13、
14、
15、其中,μx表示图像x的均值,μy表示图像y的均值,σx表示图像x的标准差,σy表示图像y的标准差,σxy代表图像x和y协方差;c1、c2和c3分别是由下式给出的常数:
16、c1=(k1l)2,c2=(k2l)2,c3=c2/2;
17、其中,l是像素值的动态范围,k1和k2是两个小于1的常数;
18、数据增强方法具体为:包括图像亮度、饱和度、对比度的随机变换,水平方向和垂直方向的翻转及60°、90°、150°、270°的随机角度旋转,高斯噪声、椒盐噪声的噪声处理;随机使用上述数据增强方法对交通标志图像进行数据增强,将数据增强后的图像与原图像合并,生成交通标志数据集。
19、优选地,所述改进yolov4-tiny算法的卷积神经网络模型的结构为:cbl-i、e-dsc-i、e-dsc-ii、e-dsc-iii、第一最大池化层、e-dsc-iv、第二最大池化层、s-rfb、ffrm-i、ffrm-ii、cbl-ii、cbl-iii、卷积层i、卷积层ii;cbl-i的输入为输入图像,cbl-i的输出端与e-dsc-i的输入端相连接,e-dsc-i的输出端与e-dsc-ii的输入端相连接,e-dsc-ii的输出端分别与e-dsc-iii的输入端、ffrm-ii的输入端相连接,e-dsc-iii的输出端与第一最大池化层的输入端相连接,第一最大池化层的输出端分别与e-dsc-iv的输入端、ffrm-i的输入端相连接,e-dsc-iv的输出端与第二最大池化层的输入端相连接,第二最大池化层的输出端与s-rfb的输入端相连接,s-rfb的输出端与ffrm-i的输入端相连接,ffrm-i的输出端与cbl-ii的输入端相连接,cbl-ii的输出端与卷积层i的输入端相连接,卷积层i的输出端为第一目标检测层;ffrm-ii的输出端与cbl-iii的输入端相连接,cbl-iii的输出端与卷积层ii的输入端相连接,卷积层ii的输出端为第二目标检测层。
20、优选地,所述e-dsc的结构为:dsc-i、dsc-ii、dsc-iii、dsc-iv、dsc-v;输入特征分别输入dsc-i和dsc-ii的输入端,dsc-i的输出端与dsc-iii的输入端相连接,dsc-iii的输出端与dsc-iv的输入端相连接,dsc-i的输出端、dsc-ii的输出端、dsc-iii的输出端和dsc-iv的输出端进行融合后输入至dsc-v;其中,dsc-i、dsc-ii、dsc-iii、dsc-iv、dsc-v的结构均为:深度卷积层→bn→relu6→点卷积层→bn→relu6;
21、cbl-i、cbl-ii、cbl-iii的结构均为:conv→bn→leakyrelu。
22、优选地,所述ffrm的结构包括:语义信息提纯模块、双线性插值上采样和纹理信息提纯模块;首先由高层特征图m2经过语义信息提纯模块提取语义特征,然后通过双线性插值上采样操作与低层特征图m1进行拼接得到融合特征图m3;利用纹理信息提纯模块过滤融合特征图m3中的干扰信息后,使用相加操作输出特征图m′;表达式如下:
23、
24、式中:rc代表语义信息提纯模块;rt代表纹理信息提纯模块;代表拼接操作;代表相加操作;↑2×代表双线性插值上采样。
25、优选地,所述语义信息提纯模块和纹理信息提纯模块的结构均是基于mobilenetv2中的反瓶颈残差结构,融合高效坐标注意力(eca)机制;
26、eca机制的结构为:对于输入特征图x∈rc×h×w,分别使用大小为(h,1)和(1,w)的全局平均池化核avg和全局最大池化核max沿水平、垂直坐标方向对每个通道进行编码,将水平和垂直方向的输入特征分别聚合为四个独立的方向感知特征图;其中,高度为h的第c通道全局平均池化和全局最大池化输出分别表示为:
27、
28、
29、式中:xc(h,i)表示输入特征图x中坐标为(h,i)、通道为c的分量;表示经全局平均池化核后高度为h的第c通道输出分量,表示经全局最大池化核后高度为h的第c通道输出分量;
30、同理,宽度为w的第c通道全局平均池化和全局最大池化的输出结果分别表示为:
31、
32、
33、式中:xc(j,w)表示输入特征图x中坐标为(j,w)、通道为c的分量;表示经全局平均池化核后宽度为w的第c通道输出分量,表示经全局最大池化核后宽度为w的第c通道输出分量;
34、分别将输出分量和和通过元素相加合并,表示如下:
35、
36、
37、其中,表示经过元素相加后高度为h的第c通道输出分量,表示经过元素相加后宽度为w的第c通道输出分量;
38、将两个输出分量和在空间维度上进行拼接,生成特征图z∈rc×1×(w+h),将特征图z沿通道方向划分为g组,即z=[z1,...,zg],zk∈rc×1×(w+h)/g,k=1,2,…,g;对每组特征图通过共享的1×1卷积变换函数f进行降维,表述为:
39、f=δ(f(zk));
40、式中:δ表示h-swish激活函数;f∈rc×1×(w+h)/g×r为第g组中间映射特征图,其中r为控制模块尺寸缩小的比例;
41、得到中间映射特征图后,通过通道混洗操作将不同组特征图的通道顺序进行打乱重排;以第g组中间映射特征图为例,沿空间维度通过split操作将其分为两个单独的特征张量,分别为fh∈rc×h×1/r和fw∈rc×1×w/r;使用两个1×1卷积升维变换函数fh和fw分别将两个张量的通道数与输入特征图通道数保持一致,具体表述为:
42、ph=σ(fh(fh));
43、pw=σ(fw(fw));
44、式中:σ表示sigmoid激活函数;
45、将两个输出张量分别作为注意力特征,通过广播机制进行拓展,与输入特征图x相乘以赋予注意力权重,得到最终的输出特征图y;表达式为:
46、
47、其中,yc(i,j)表示输出特征图y中坐标为(i,j)的第c通道的输出分量;xc(i,j)表示输入特征图x中坐标为(i,j)的第c通道的输出分量;表示宽度为h的第c通道的注意力特征权重,表示表示宽度为w的第c通道的注意力特征权重。
48、优选地,所述s-rfb的结构为:首先使用卷积率分别为1、3、5的空洞卷积分别对大小为(c,h,w)的输入特征进行特征提取,获得三种不同大小的感受野特征图;然后使用大小为1×1、个数为c/4的卷积核对大小为(c,h,w)的输入特征进行连接,得到中间特征图;最后,使用拼接操作将感受野特征图和中间特征图进行融合,聚合网络上下文信息。
49、优选地,所述训练超参数包括batch size、epoch、学习率、最低学习率和动量。
50、优选地,所述评价指标选用精确率p、召回率r、平均精度map、fps和模型参数量params;其中,精确率用来衡量算法对目标的分类能力,召回率用来衡量算法对目标的检测能力,map用以综合评判算法检测性能;精确率、召回率和平均精度计算公式如下:
51、
52、
53、
54、式中:tp表示检测为正样本且结果正确;fp表示检测为正样本且结果错误;fn表示检测为负样本且结果错误;c表示目标类别数;
55、fps表示网络每秒检测图片的帧数,用来评估模型检测实时性;模型参数量是指模型训练中需要训练的参数总数,计算公式如下:
56、params=kh×kw×cin×cout;
57、式中:kh和kw分别表示卷积核长和宽的大小,cin和cout分别表示卷积核输入和输出通道数。
58、与现有技术相比,本发明产生的有益效果为:
59、1)通过使用ms-ssim方法和数据增强方法对所制作的数据集进行处理,相比于现有技术来说,可以有效防止卷积神经网络模型在训练过程中对某些场景出现过拟合现象,并有效提高模型鲁棒性和泛化能力。
60、2)对原来的csp-darknet53-tiny主干网络进行重新设计和替换,通过一种融合深度可分离卷积的高效层聚合轻量型模块,合理设计梯度路径,在使用较少过渡层的情况下使整个网络的最短梯度路径快速变长,通过将不同特征层的权值进行拼接组合使网络学习到更多样化的特征,有效提升主干网络特征提取能力。
61、3)构建基于高效坐标注意力机制的特征提纯复用结构,将原来的fpn特征融合结构进行替换,可以有效解决不同尺度的特征图在通过上采样操作融合后,出现由于自身语义信息差异及干扰信息使多尺度特征不能准确表达的问题,并能够从图像复杂背景中辨识目标关键特征,抑制无用特征信息表达。
62、4)在主干网络末端增加本轻量级感受野模块,解决yolov4-tiny网络感受野单一固定问题,在主干网络中引入上下文信息,提高模型检测准确度。
63、5)分别使用下采样倍数为4和8的特征图作为预测头,相比于原算法,可以充分利用具有更多细节信息的底层特征图,增强对小目标检测识别能力。
64、6)本发明可以有效提高所制作交通标志数据集的质量,优化深度学习模型训练效果,且本发明所提出的改进yolov4-tiny算法对小目标交通标志具有良好的检测效果。
- 还没有人留言评论。精彩留言会获得点赞!