Ki67影像预测模型的伪标签自蒸馏优化方法
本发明涉及一种医学图像的处理方法,具体地说是一种ki67影像预测模型的伪标签自蒸馏优化方法。
背景技术:
1、肾癌是全球常见的恶性肿瘤之一,其预后和治疗策略与肿瘤的生物学行为密切相关。ki67是一种重要的肿瘤生物标记物,其表达水平与肿瘤的增殖能力和侵袭性相关。因此,对ki67的表达进行准确预测,对于肾癌的诊断和治疗具有重要的临床意义。
2、cn115482232a公开了一种负样本引导的自蒸馏病理图像分析方法,该方法构造了两个结构相同的分类网络,通过自蒸馏的方式进行训练,再同时利用阴性整张病理图像中所有的图像块都是阴性的先验知识,引导这一自蒸馏的过程,从而实现端到端的训练,构成了一个实例级别的分类器。然而,该方法需要大量的标注数据,没有考虑到有标注数据稀缺的情况。
3、cn114066882a公开了一种基于深度影像组学的肺腺癌ki67表达水平无创检测方法及装置,该方法利用深度学习,影像组学和临床特征融合预测肺腺癌中ki67的状态。但是,该方法的模型参数巨大,计算复杂度也偏高。
4、综上,当前的深度学习方法在预测ki67表达时面临着两大挑战:一是由于标注样本稀缺,模型的训练效果受限;二是由于深度学习模型通常具有大量的参数,导致模型的计算复杂度高,内存占用大,不易于实际部署。
5、因此,如何在标签稀缺的情况下,利用伪标签技术和自蒸馏技术,设计出一个能够准确预测ki67表达、计算复杂度低、易于部署的模型,是当前肾癌ct图像ki67表达预测技术面临的重要问题。
技术实现思路
1、本发明的目的就是提供一种ki67影像预测模型的伪标签自蒸馏优化方法,以解决目前预测ki67表达存在的标注样本稀缺和模型计算复杂度高的问题。
2、本发明的目的是这样实现的:一种ki67影像预测模型的伪标签自蒸馏优化方法,包括以下步骤:
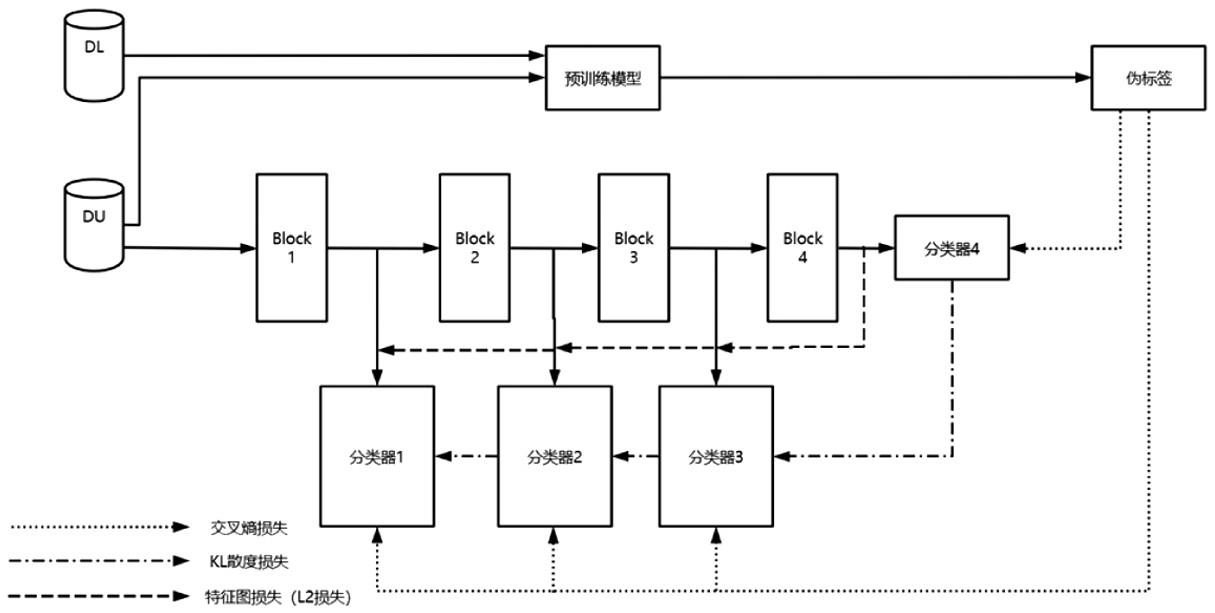
3、s1、收集若干用ki67表达标签标注的肾癌ct图像样本,构成数据集dl;收集若干没有用ki67表达标签标注的肾癌ct图像样本,构成数据集du。
4、s2、选择resnet-101作为基础训练模型,用数据集dl进行预训练,训练出能够预测ki67表达的预训练模型mt。
5、s3、将数据集du输入预训练模型mt,使数据集du中的每个样本生成一个预测的ki67表达值,用该表达值作为该样本的伪标签,从而使没有标签的数据集du转变成为带有伪标签的数据集du。
6、s4、构建以resnet-18作为骨干网络的自蒸馏模型ms,所述自蒸馏模型ms包括四个瓶颈层、四个全连接层和四个softmax层;其最深层部分为教师分类器,其他的浅层部分为学生分类器;学生分类器通过教师分类器进行学习和调整。
7、s5、自蒸馏模型ms的自蒸馏过程,具体包括以下子步骤:
8、s5-1将带有伪标签的数据集du中的伪标签与样本图像一并输入自蒸馏模型ms。
9、s5-2自蒸馏模型ms的分类器根据样本图像生成对应的分类标签预测,再计算预测标签与伪标签之间的交叉熵,将其作为自蒸馏过程的第一个损失函数。
10、s5-3计算学生分类器根据样本图像生成的预测标签与教师分类器生成的教师标签之间的kl散度,将其作为自蒸馏过程的第二个损失函数。
11、s5-4计算最深层部分与每个浅层部分之间的特征图之间的l2损失,将其作为自蒸馏过程的第三个损失函数。
12、s5-5自蒸馏模型ms中的分类器为:其中,c为自蒸馏模型ms中分类器的个数;第i个分类器的softmax输出为:qi(i=1,2,3,4);最深分类器的softmax输出特别表示为qc,即q4=qc。
13、每输入一个样本图像x,自蒸馏模型ms即输出一个预测标签。
14、自蒸馏过程的第一个损失函数lc为通过预训练模型mt得到的伪标签与分类器的softmax输出qi之间的交叉熵之和,即:
15、
16、其中,为交叉熵。
17、自蒸馏过程的第二个损失函数lk为第c个分类器与每个浅层分类器的softmax输出之间的kl散度之和,即:
18、
19、其中,kl(qi,qc)为kl散度。
20、自蒸馏过程的第三个损失函数ll是自蒸馏模型ms中最深层部分与每个浅层部分之间的l2距离之和,即:
21、
22、其中,fi为输入到分类器θi的特征,fc为输入到分类器θc的特征(由瓶颈层输出)。
23、将这三个损失函数合并,作为自蒸馏过程的总损失函数:
24、
25、其中,α和λ分别为平衡参数。
26、s6、自蒸馏模型ms的优化训练,具体包括以下子步骤:
27、s6-1先进行数据增强:对数据集dl和数据集du中的每个样本图像都进行随机旋转、随机平移和随机缩放。
28、s6-2训练自蒸馏模型ms:使用数据集dl对自蒸馏模型ms进行训练;采用adam优化器,初始学习率设为0.001,每训练10个epoch降低10%;最大训练epoch为100。
29、s6-3训练过程中监控模型的表现,当自蒸馏模型ms在验证集上的性能在连续10个epoch中没有提高时,停止训练,得到训练好的自蒸馏模型ms。
30、进一步地,步骤s2的训练过程中采用adam优化器进行参数优化。
31、进一步地,步骤s3中,在每个样本的伪标签生成过程中,是选择预训练模型mt预测的置信度最高的标签作为该样本的伪标签。
32、进一步地,步骤s4中,学生分类器通过分别对齐学生预测和教师预测,学生预测和伪标签,学生特征图和教师特征图进行学习和调整。。
33、本发明预测方法利用伪标签技术,可以充分利用未标注的数据,提高模型的预测准确性。同时,通过自蒸馏技术,可以有效地降低模型的计算复杂度,使模型更易于实际部署应用。
34、本发明预测方法对于多种类型的图像分类和预测任务都具有广泛的应用潜力。同时,由于其结构简单,实现起来易于操作,因此具有较强的实用性和可操作性。本发明预测方法利用深度学习技术,特别是伪标签自蒸馏技术,对肾癌ct图像进行ki67表达预测,特别适用于医学图像分析、肿瘤病理诊断、药物研发等领域。
35、本发明预测方法通过利用伪标签和自蒸馏过程,有效地利用了未标记的肾癌ct图像,压缩了模型大小,提高了模型的预测性能。同时,这种方法也可广泛应用于其他的医学图像处理任务。本发明预测方法能够在未来的医学图像处理任务中发挥更大的作用,也可应用于其他类型的医学图像,如mri、pet等。
技术特征:
1.一种ki67影像预测模型的伪标签自蒸馏优化方法,其特征是,包括以下步骤:
2.根据权利要求1所述的ki67影像预测模型的伪标签自蒸馏优化方法,其特征是,在步骤s2的训练过程中,采用adam优化器进行参数优化。
3.根据权利要求1所述的ki67影像预测模型的伪标签自蒸馏优化方法,其特征是,步骤s3中,在每个样本的伪标签生成过程中,是选择预训练模型mt预测的置信度最高的标签作为该样本的伪标签。
4.根据权利要求1所述的ki67影像预测模型的伪标签自蒸馏优化方法,其特征是,步骤s4中,学生分类器通过分别对齐学生预测和教师预测,学生预测和伪标签,学生特征图和教师特征图进行学习和调整。
技术总结
本发明涉及一种Ki67影像预测模型的伪标签自蒸馏优化方法,包括以下步骤:①提供一个标注有Ki67表达标签的肾癌CT图像数据集和一个未标注的肾癌CT图像数据集。②运用带有Ki67表达标签的数据集,训练预设模型以预测Ki67的表达。③通过预训练模型,处理未标注的肾癌CT图像数据集,产生Ki67表达的伪标签。④设计并执行一个自蒸馏模型,使其深层部分为浅层部分提供教学引导。⑤将伪标签与原始图像一同输入自蒸馏模型中,执行模型训练。⑥在模型训练过程中,形成训练损失,作为自蒸馏的指导。⑦通过这种自蒸馏方法,得到能够准确预测Ki67表达的模型。本发明解决了深度网络规模大且难以部署以及医学影像标注数量少的问题,具有临床应用价值。
技术研发人员:杨昆,张轩旗,刘琨,崔振宇,刘爽,薛林雁,李民,许天笑
受保护的技术使用者:河北大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!