一种多源异构大数据处理系统的制作方法
本发明涉及大数据,更具体地说,它涉及一种多源异构大数据处理系统。
背景技术:
1、大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分,对于来源范围有限的大数据,例如地区政务大数据,对于大数据进行结构化和统一化的需求大于对于大数据的挖掘的需求,但是通过人工进行特征提取来进行大数据的结构化和统一化耗时较长。
技术实现思路
1、本发明提供一种多源异构大数据处理系统,解决相关技术中通过人工进行特征提取来进行大数据的结构化和统一化耗时较长的技术问题。
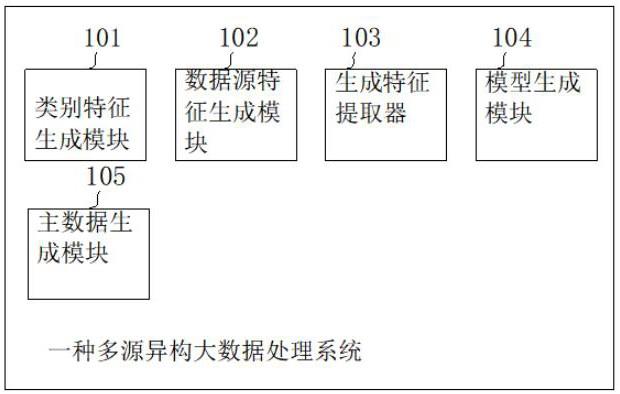
2、本发明提供了一种多源异构大数据处理系统,包括:
3、类别特征生成模块,其基于主数据的字段名称来生成主数据类别特征,一个主数据的字段名称对应一个主数据类别特征;数据源特征生成模块,其基于主数据所链接的原始数据集来生成数据源特征;生成特征提取器,其用于从原始数据集中随机提取字符和/或词来生成单元特征向量,然后将单元特征向量组合获得生成特征;模型生成模块,其用于生成主数据生成模型;主数据生成模型包括特征合成模块、第二特征生成器、第一神经网络、第二神经网络,其中特征合成模块用于将主数据类别特征与生成特征进行合成来生成基本特征,第一神经网络输入基本特征,然后输出第一特征;第二特征生成器从主数据集合中随机选择n个主数据,为提取的每个主数据生成一个主数据特征,将生成的所有主数据特征和主数据类别特征合成生成第二特征;第二特征和第一特征输入第二神经网络,第二神经网络,第二神经网络的输出映射到分类空间,分类空间包含两个分类标签,分别表示输入为第二特征和输入为第一特征;
4、主数据生成模块,其用于将使用者输入的主数据的字段名称输入类别特征生成模块,生成主数据类别特征;将该主数据类别特征与从待生成主数据的原始数据集中生成的生成特征合成基本特征,将该基本特征输入主数据生成模型的第一神经网络,基于第一神经网络生成的第一特征获得待生成主数据的原始数据集的主数据和主数据对应的字段名称。
5、进一步地,主数据所链接的原始数据集是指需要与该主数据关联的原始数据集。
6、进一步地,第一神经网络和第二神经网络均为多层感知机。
7、进一步地,主数据特征和主数据类别特征合成时在主数据类别特征之后拼接主数据特征。
8、进一步地,主数据类别特征与生成特征进行合成时在主数据类别特征之后拼接随机特征向量。
9、进一步地,第一特征和第二特征的维度相同,第一特征和第二特征进行矩阵化之后表示为:,表示矩阵u中的第一行的第i个元素,表示第i个主数据类别特征;表示矩阵u中的第j行的第i列的元素,表示第j个主数据对应于第i个主数据类别特征的字段,m表示主数据的总数,n表示一个主数据的主数据类别特征的总数。
10、进一步地,第二神经网络经过softmax层进行输出,输出的值为概率值。
11、进一步地,对于第一神经网络和第二神经网络是进行联合训练的,训练的损失函数为:
12、
13、其中表示损失值,等于训练集的训练样本的数量,y为设置的常数值,表示第二神经网络输入第t个训练样本的第二特征时输出的对应于第二特征的分类标签的概率值,表示第二神经网络输入第t个训练样本的第g个第一特征时,输出的对应于第一特征的分类标签的概率值。
14、进一步地,联合训练的训练样本来源于已经构建主数据的原始数据集,生成特征提取器从一个作为训练样本的原始数据集进行多次提取可以获得多个生成特征,因此可以合成多个基本特征,通过第一神经网络生成多个第一特征。
15、进一步地,主数据生成模块从待生成主数据的原始数据集中生成多个生成特征,分别合成多个基本特征,将合成的多个基本特征分别输入第一神经网络获得多组主数据,从多组主数据中删除重复的主数据之后获得最终的主数据集合。
16、本发明的有益效果在于:本发明能够对于来源范围有限的大数据自动化地生成与之匹配的主数据,通过主数据对大数据进行结构化和统一化。
技术特征:
1.一种多源异构大数据处理系统,其特征在于,包括:
2.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,主数据所链接的原始数据集是指需要与该主数据关联的原始数据集。
3.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,第一神经网络和第二神经网络均为多层感知机。
4.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,主数据特征和主数据类别特征合成时在主数据类别特征之后拼接主数据特征。
5.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,主数据类别特征与生成特征进行合成时在主数据类别特征之后拼接随机特征向量。
6.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,第一特征和第二特征的维度相同,第一特征和第二特征进行矩阵化之后表示为:,表示矩阵u中的第一行的第i个元素,表示第i个主数据类别特征;表示矩阵u中的第j行的第i列的元素,表示第j个主数据对应于第i个主数据类别特征,m表示主数据的总数,n表示一个主数据的主数据类别特征的总数。
7.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,第二神经网络经过softmax层进行输出,输出的值为概率值。
8.根据权利要求7所述的一种多源异构大数据处理系统,其特征在于,对于第一神经网络和第二神经网络是进行联合训练的,训练的损失函数为:,其中表示损失值,等于训练集的训练样本的数量,y为设置的常数值,表示第二神经网络输入第t个训练样本的第二特征时输出的对应于第二特征的分类标签的概率值,表示第二神经网络输入第t个训练样本的第g个第一特征时,输出的对应于第一特征的分类标签的概率值。
9.根据权利要求8所述的一种多源异构大数据处理系统,其特征在于,联合训练的训练样本来源于已经构建主数据的原始数据集,生成特征提取器从一个作为训练样本的原始数据集进行多次提取可以获得多个生成特征,因此可以合成多个基本特征,通过第一神经网络生成多个第一特征。
10.根据权利要求1所述的一种多源异构大数据处理系统,其特征在于,主数据生成模块从待生成主数据的原始数据集中生成多个生成特征,分别合成多个基本特征,将合成的多个基本特征分别输入第一神经网络获得多组主数据,从多组主数据中删除重复的主数据之后获得最终的主数据集合。
技术总结
本发明涉及大数据技术领域,公开了一种多源异构大数据处理系统,包括:类别特征生成模块,其基于主数据的字段名称来生成主数据类别特征,一个主数据的字段名称对应一个主数据类别特征;数据源特征生成模块,其基于主数据所链接的原始数据集来生成数据源特征;生成特征提取器,其用于从原始数据集中随机提取字符和/或词来生成单元特征向量,然后将单元特征向量组合获得生成特征;模型生成模块,其用于生成主数据生成模型;主数据生成模块,其用于生成待生成主数据的原始数据集的主数据和主数据对应的字段名称;本发明能够对于来源范围有限的大数据自动化的生成与之匹配的主数据,通过主数据对大数据进行结构化和统一化。
技术研发人员:张晶,董哲
受保护的技术使用者:河北维嘉信息科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!