一种基于交叉环境注意力的指代图像分割方法
本发明属于指代图像分割领域,具体涉及一种基于交叉环境注意力的指代图像分割方法。
背景技术:
1、随着人工智能时代的到来,人们对基于语言的人机交互和智能化图像编辑的需求越来越高。尽管传统的语义分割任务能够提供丰富的图像语义信息,但是它对图像中目标的识别能力和关联关系的理解仍非常有限。因此,指称图像分割任务的相关研究应运而生。该任务旨在根据文本描述分割图像中相匹配的区域,是实现人机交互和图像智能编辑等任务的关键技术。与语义分割任务相比,指称图像分割通常面对更复杂的场景,同时要求对复杂多变的语言描述进行深入解析,实现语义和视觉特征的系统分析,因而更具挑战性。
2、该任务主要关注两个问题:(1)图像和文本特征的提取;(2)图像和文本特征融合。特征提取方向上,现有的工作主要使用卷积神经网络、循环神经网络或transformer模型进行特征提取。特征融合上,现有的工作主要利用连接、注意力机制或多模态transformer模型融合图像和文本两个模态的特征,最终输出目标区域掩码。
3、目前针对指称图像分割问题的方法大多存在着以下几个问题:(1)在利用注意力机制在计算多模态特征间的相似度时候,只考虑了本模态特征和另一个模态所有特征之间的相似度,忽略了本模态其他特征的作用;(2)在不同文本和视觉特征组合下,文本和图像中的同一对特征可能有着不同的连接关系,如果只学习文本和图像特征之间的相似性,而不考虑二者组合构成的环境背景,会降低模型预测的效果。
技术实现思路
1、发明目的:本发明主要针对上述指代图像分割方法的不足之处进行改善,提出了一种基于交叉环境注意力的指代图像分割方法。首先,挖掘图像和文本的全局语义特征;其次,构建图文多模态图结构,利用利用图注意力机制计算多模态特征相似性,进而得到图文注意力矩阵,实现更高质量的图文特征融合,最终输出目标区域掩膜。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种基于交叉环境注意力的指代图像分割方法,其步骤包括:
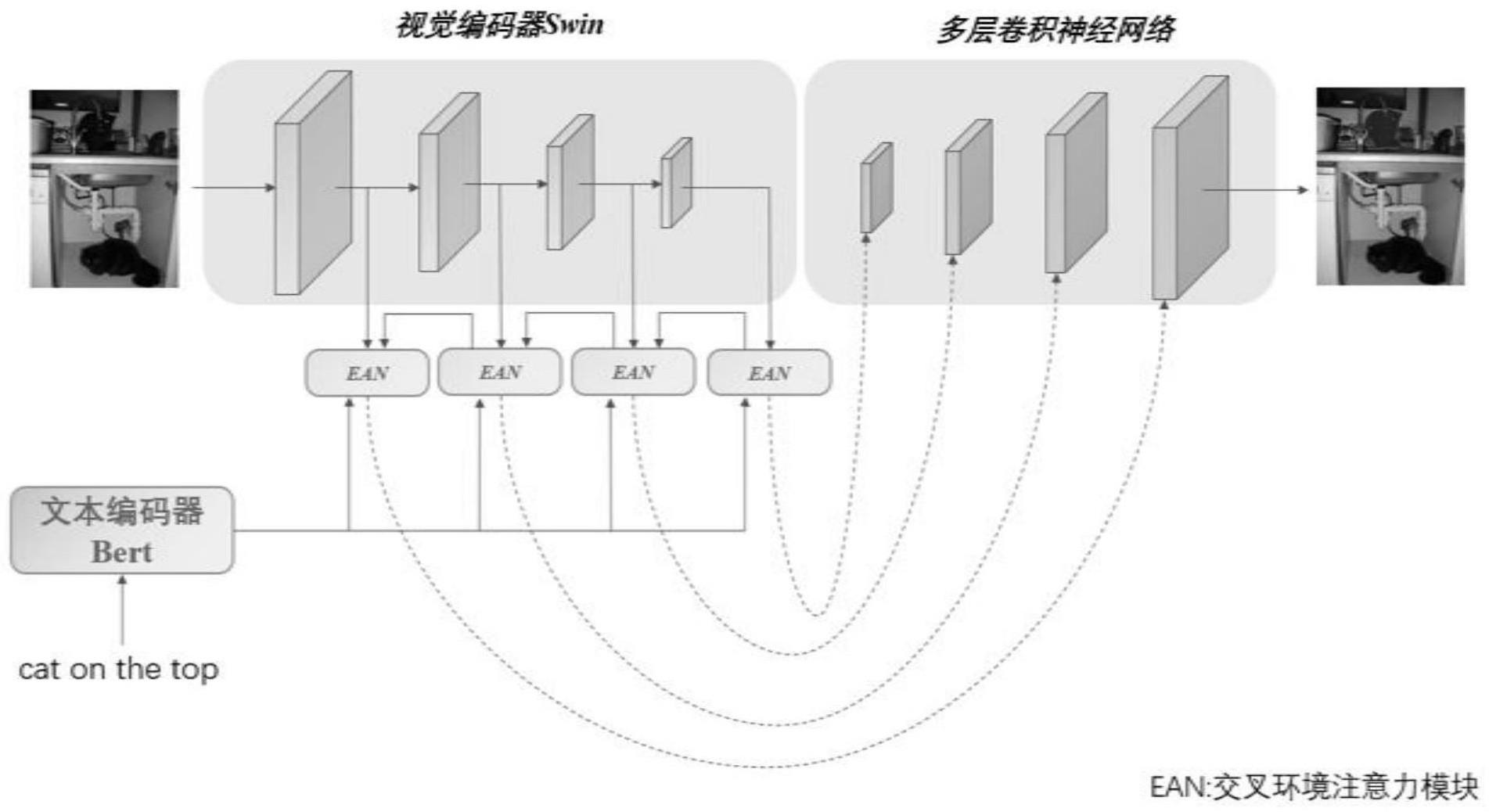
4、步骤s1:提取图文特征,利用预训练模型swin transformer提取四个不同尺寸的图像特征,四个特征按照其输出顺序依次编号为一、二、三、四。利用预训练模型bert提取文本特征;
5、步骤s2:将得到的四个不同尺度的图像特征分别和文本特征作为原始特征输入环境注意力模块,获得四层图文特征关系矩阵;
6、进一步,所述步骤s2具体为:
7、步骤s21:对原始文本特征和原始图像特征分别通过不同的线性层和gelu激活函数,变换成相同的尺寸后将二者连接起来,再通过一层线性层获得边特征嵌入,在通道维度上进行切分,将特征分成h个头;
8、步骤s22:对第四层的原始图像特x4征进行恒等映射,三、二、一层的原始图像特征x3,x2,x1分别乘上上层掩码s4,s3,s2。记作处理后的图像特征;
9、步骤s23:对原始文本特征和处理后图像特征分别通过全局平均池化层、线性层和激活函数,将二者连接后通过一层线形层获得环境语义信息,在通道维度上进行切分,将特征分成h个头;
10、步骤s24:将边嵌入和环境语义信息每个头两两一组,分别正则化后相乘,再通过激活函数,得到每对头中每条边的存在概率矩阵,即为h组原始图像和原始文本特征关系矩阵;
11、步骤s3:利用得到的四个不同尺寸的原始图像特征和原始文本特征以及四层图文关系矩阵,将文本特征转化为多模态特征,和对应层的原始图像特征进行融合;
12、进一步,所述步骤s3具体为:
13、步骤s31:将原始文本特征通过一层线形层,在通道维度上进行切分,将特征分成h个头,得到用于查询的文本特征;
14、步骤s32:将用于查询的文本特征每个头和对应一组关系矩阵相乘,获得了转移到视觉模态下的文本特征,将所有头连接起来,通过一组线性层和正则化层融合,得到了初步的多模态特征;
15、步骤s33:将初步的多模态特征矩阵和通过一组线形层、正则化、激活函数的原始图像特征矩阵连接,所得矩阵再通过一个多层感知机和一层正则化层,就得到了最终融合的多模态特征;
16、步骤s34:对于第四、三、二层的多模态特征,分别利用双线性插值上采样到与三、二、一层图像特征大小相同的尺寸,再通过一层线性层和激活函数,作为步骤s22中的掩码s4,s3,s2。
17、步骤s4:将四层多模态特征传入多层卷积神经网络,获得最终目标区域掩码;
18、进一步,所述步骤s4具体为:
19、步骤s41:将第四层多模态特征通过双线性插值上采样到与第三层多模态特征相同尺寸,连接二者,通过多层卷积模块融合,得到融合后的第三层多模态特征;
20、步骤s42:将融合后的第三层多模态特征通过双线性插值上采样到与第二层多模态特征相同尺寸,连接二者,通过多层卷积模块融合,得到融合后的第二层多模态特征;
21、步骤s43:将融合后的第二层多模态特征通过双线性插值上采样到与第一层多模态特征相同尺寸,连接二者,通过多层卷积模块融合,得到融合后的第一层多模态特征;
22、步骤s44:对融合后的第一层多模态特征用一层线性层降维,得到最终目标区域掩码,将掩码用双线性插值上采样,得到与输入图片相同尺寸的掩码,完成基于文本的实例分割任务。
23、步骤s5:利用交叉熵损失函数训练模型,所得模型即为实现基于文本的实例分割功能模型;
24、本发明与现有技术相比具有以下有益效果:
25、(1)与大多数方法中跨模态注意力机制不同,本发明利用图文全局语义信息引导生成图文关系矩阵,这使得模型可以更高效地利用两个模态的信息。该发明根据不同的全局语义特征,自适应地调整多模态对应关系,增强了模型对跨模态信息的理解能力。(2)大多数方法的跨模态注意力机制只考虑了本层图像信息和文本信息之间的关系,本发明用深层输出的多模态信息作为信号自适应地调整浅层的图像全局语义信息间的关联性,实现了多尺度多模态融合特征间的信息交流,增强了模型对环境语义信息的理解能力。
技术特征:
1.一种基于交叉环境注意力的指代图像分割方法,其特征在于,步骤包括:
2.根据权利要求1所述的一种基于交叉环境注意力的指代图像分割方法,其特征在于,所述步骤s3具体为:
3.根据权利要求1或2所述的一种基于交叉环境注意力的指代图像分割方法,其特征在于,所述步骤s4具体为:
4.根据权利要求2所述的一种基于交叉环境注意力的指代图像分割方法,其特征在于,所述的步骤s33中,多层感知机是由线性层、gelu层、线性层组成。
5.根据权利要求3所述的一种知识图谱指导的多张场景图像生成方法,其特征在于,所述的步骤s41中,多层卷积模块的结构为卷积层、gn层、relu层、卷积层、gn层、relu层。
技术总结
本发明属于指代图像分割领域,具体涉及一种基于交叉环境注意力的指代图像分割方法。首先用语言编码器和视觉编码器提取文本和图像的原始特征,并分别构建语义图和视觉图结构;其次利用交叉注意力机制将文本和图像节点特征映射到多模态特征空间中,通过学习交叉环境信息对边特征进行嵌入,进而计算跨模态关系矩阵,得到文本和图像的跨模态特征表示;最后利用在多个尺度上整合多模态特征得到最终的分割掩膜。本发明根据不同的全局语义特征,自适应地调整多模态对应关系,增强了模型对跨模态信息的理解能力。通过利用真实的多模态数据集评估本发明,验证了本发明的性能达到了国际先进水平。
技术研发人员:刘骏华,孔雨秋
受保护的技术使用者:大连理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!