一种基于图匹配的域自适应目标检测方法
本发明涉及计算机视觉,尤其涉及一种基于图匹配的域自适应目标检测方法。
背景技术:
1、计算机视觉中的目标检测问题是指在图像或视频中自动检测出目标物体的位置和类别。目标检测在许多场景中都具有重要意义,例如自动驾驶、智能交通、无人机控制等领域。传统的目标检测算法通常假设测试数据集(又称作目标域)和训练数据集(又称作源域)服从于同一总体分布。在训练数据和测试数据总体分布一致的情况下,经过充分训练的目标检测模型已被证明能够达到相当可观的性能。然而,图像的背景、拍摄角度、成像质量甚至是采集设备参数的设置等变化都会导致数据分布的不一致。在新领域部署传统的目标检测方法会导致由于领域差异而出现灾难性的性能下降。若在新领域收集大量的样本,并对样本进行标注,则更会消耗海量的物力与人力。为了克服这一挑战,研究人员探索出了无监督域自适应方法来对齐无标注的目标域和有标注的源域。
2、无监督域自适应是指在源域上学习知识,并将学习到的知识迁移到无标注的目标域,使得模型在目标域和源域上都能取得良好的性能表现。在域自适应目标检测问题中,研究人员提出了多种解决方法,包括基于实例的方法、基于对抗学习的方法以及基于重建的方法等。这些方法不仅可以提高模型的泛化性能,还可以有效缓解目标检测任务中的过拟合问题,具有重要的理论和实践价值。
3、主流的域自适应目标检测工作采用逐像素的特征分布对齐方法,这些工作具有共同的特点,即建模域的类别中心并最小化域间类别中心的距离,使得源域与目标域在类别层次上缩小了域差距,这些方法存在一些显而易见的问题。首先,主流方法忽略了类内差异的重要性,直接人工制定类别中心来进行对齐。由于待检测目标的大小和形状各不相同,类内变化同样包含了表示类条件分布的重要信息,如比例和形状,这些信息也应该在域自适应中得到对齐。其次,主流方法存在同一训练批次中语义不匹配的问题,即只在两个域共同出现的类别上进行执行域自适应。主流方法忽略了缺失类别导致的语义知识丢失问题,致使域自适应效果不佳。
技术实现思路
1、本发明的实施例提供了一种基于图匹配的域自适应目标检测方法,用于解决现有技术中存在的问题。
2、为了实现上述目的,本发明采取了如下技术方案。
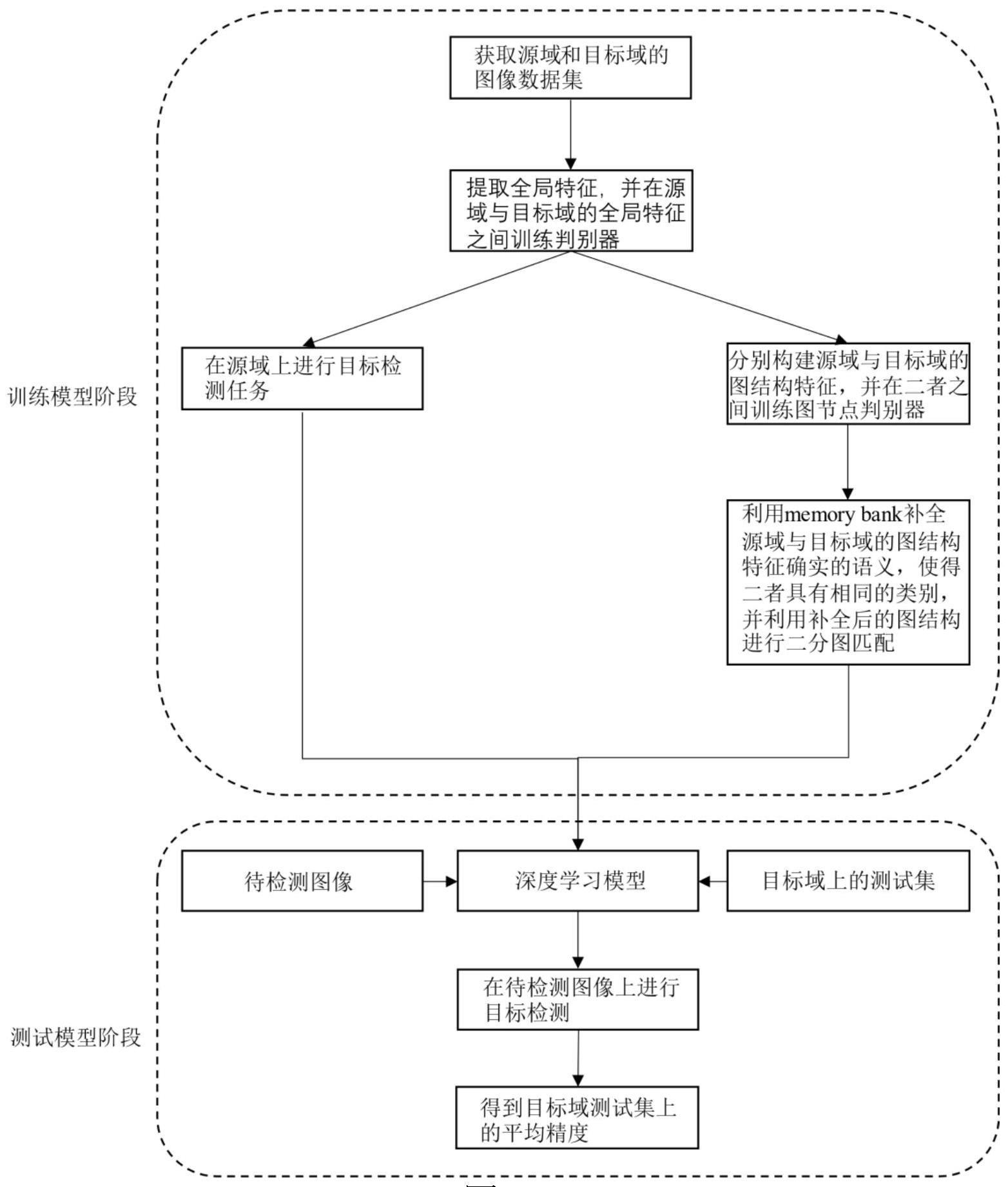
3、一种基于图匹配的域自适应目标检测方法,包括以下步骤:
4、步骤一:获取两个不同的图像数据集,其中一个是已标注的源域图像数据集,另一个是未标注的目标域图像数据集。
5、步骤二:使用共享的特征提取器提取全局特征,在源域和目标域的全局特征之间训练判别器得到全局特征的对抗性损失,并利用源域的全局特征进行目标检测任务,得到目标检测损失。对于源域的全局特征,模型使用均匀采样来采集标注框内的像素,并将其作为前景节点的样本。同时采样标注框外的像素作为背景样本。对于目标域的全局特征,模型将目标域的特征前向传播到fcos(fully convolutional one-stage object detection)的分类头,以获得伪分数图模型会采样满足的像素作为前景节点,同时采样标注框外的低分数像素,即的像素作为背景样本。在采样全局特征后,模型进行非线性投影以获得原始图节点,从而实现特征从视觉空间到图形空间的转换。在源域和目标域的图结构特征之间训练图节点判别器,得到图节点判别器的对抗性损失。
6、步骤三:针对步骤二获得的源域图结构特征和目标域图结构特征,模型进行图语义补全。为了在缺失的类别中生成伪节点,模型定义了一个图指导的拥有特定类别知识的memory bank,memory bank使用谱聚类进行更新。对于源域的缺失类别的补全,模型计算缺失类别ω对应目标域节点的标准方差,得到近似缺失类别分布的向量然后,模型从memory bank中加载相应的语义类别的memory seed来作为期望后用高斯采样和线性投影来获得缺失类别的伪节点,最终补全了源域的图结构特征的语义。目标域的图结构特征采取相同的方式进行补全。针对语义完整的图结构特征,模型在源域和目标域节点之间建立跨图交互,得到亲和度矩阵。最后模型在源域与目标域的亲和度矩阵之间进行二分图匹配,得到图匹配损失。
7、步骤四:将步骤二产生的两个对抗性损失和目标检测损失与步骤三产生的图匹配损失相加,得到一个总的损失函数作为最终的损失函数;然后将源域与目标域数据集的训练集分批次输入网络模型进行前向传播,计算出损失值,然后进行反向传播优化网络模型,直到所述的多任务学习损失值趋于收敛时停止训练,得到训练完毕的深度学习网络模型。
8、步骤五:获取目标域的测试集图像;将所述的测试集图像输入到训练完毕的深度学习模型中,得到该图像的目标检测结果并计算模型在测试集上的平均精度。
9、优选地,所述步骤一中的视觉空间特征到图形空间特征的转换使用的结构为:全连接层-层归一化-relu激活-全连接层。
10、优选地,所述步骤二中的特征提取网络为卷积神经网络,目标检测的检测头为一阶段目标检测器的检测头。
11、优选地,所述步骤三中的图结构的表示公式为其中,为顶点集合,每一个节点代表不同类别的特征。ε为中顶点构成的边的集合。
12、优选地,所述步骤三中的图匹配损失共包含三个部分的损失。第一部分用于正确匹配节点对,并增强了最佳匹配的正确情况。第二部分评估了节点亲和力和真实值之间的差异,以抑制错误激活的情况。第三部分引入了二次约束作为第三项,以最小化局部邻域内匹配节点对的结构差异。三部分损失相加即为图匹配损失。
13、优选地,所述步骤四的训练过程中,采用自适应矩估计(adam)优化方法对网络模型进行优化。
14、由上述本发明的实施例提供的技术方案可以看出,本发明公开了一种基于图匹配的域自适应目标检测方法。本发明方法获取源域和目标域数据后,通过特征提取网络得到全局特征并剑气转化为图结构特征。方法将网络划分为目标检测分支和域自适应分支。在目标检测分支中,方法采用交叉熵损失函数获得目标检测损失。在域自适应分支中,方法在图结构特征的基础上生成伪节点来补全缺失的类别,在补全的图结构特征上进行图匹配。本发明通过图结构引入了类内差异,通过生成伪节点来补全图结构特征中缺失的类别,从而获得更优更全面的特征表达,提高了域自适应目标检测的精度。
15、本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于图匹配的域自适应目标检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,步骤s2的过程中:
3.根据权利要求2所述的方法,其特征在于,通过式
4.根据权利要求1所述的方法,其特征在于,步骤s3中,所述的通过非线性投影将源域图像数据集和目标域图像数据集的全局特征转换为图结构特征的过程包括:
5.根据权利要求4所述的方法,其特征在于,步骤s3还包括:
6.根据权利要求1所述的方法,其特征在于,步骤s4的过程中:
7.根据权利要求1所述的方法,其特征在于,步骤s4中所述的通过损失值对深度学习网络模型进行反向传播的过程中采用自适应矩估计方法对深度学习网络模型进行优化。
技术总结
本发明公开了一种基于图匹配的域自适应目标检测方法。本发明方法获取源域和目标域数据后,通过特征提取网络得到全局特征并剑气转化为图结构特征。本方法将网络划分为目标检测分支和域自适应分支。在目标检测分支中,本方法采用交叉熵损失函数获得目标检测损失。在域自适应分支中,本方法在图结构特征的基础上生成伪节点来补全缺失的类别,在补全的图结构特征上进行图匹配。本发明通过图结构引入了类内差异,通过生成伪节点来补全图结构特征中缺失的类别,从而获得更优更全面的特征表达,提高了域自适应目标检测的精度。
技术研发人员:郎丛妍,史浩,陈乃月,李浥东
受保护的技术使用者:北京交通大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!