一种基于ZYNQ平台的VGG16网络加速器设计实现方法
本发明涉及卷积神经网络,特别涉及一种基于zynq平台的vgg16网络加速器设计实现方法。
背景技术:
1、卷积神经网络是人工智能领域内一种重要的算法,被广泛地应用在许多深度学习系统上,并在全息图像重建、目标检测和自动驾驶等多种计算机视觉任务中取得了显著的成效。其中,vggnet的结构简洁,并在整个网络中都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。在保证具有相同感知野的条件下,提升了网络的深度,一定程度上提升了卷积神经网络的效果。
2、为了将卷积神经网络部署于低功耗的工作环境,多数设计开始使用zynq平台对卷积神经网络进行加速。zynq平台是由xilinx公司推出的一款支持软硬件协同设计的soc产品,它结合了cpu的指令控制能力和fpga的并行计算能力,保证了加速系统的灵活性和高性能。
3、随着卷积神经网络的发展,其规模和参数量越来越大,从而使卷积神经网络的硬件加速效果受到能耗、硬件资源有限等因素的限制,计算效率也较低。
技术实现思路
1、本发明要解决现有技术中的技术问题,提供一种基于zynq平台的vgg16网络加速器设计实现方法。
2、为了解决上述技术问题,本发明的技术方案具体如下:
3、一种基于zynq平台的vgg16网络加速器设计实现方法,包括以下步骤:
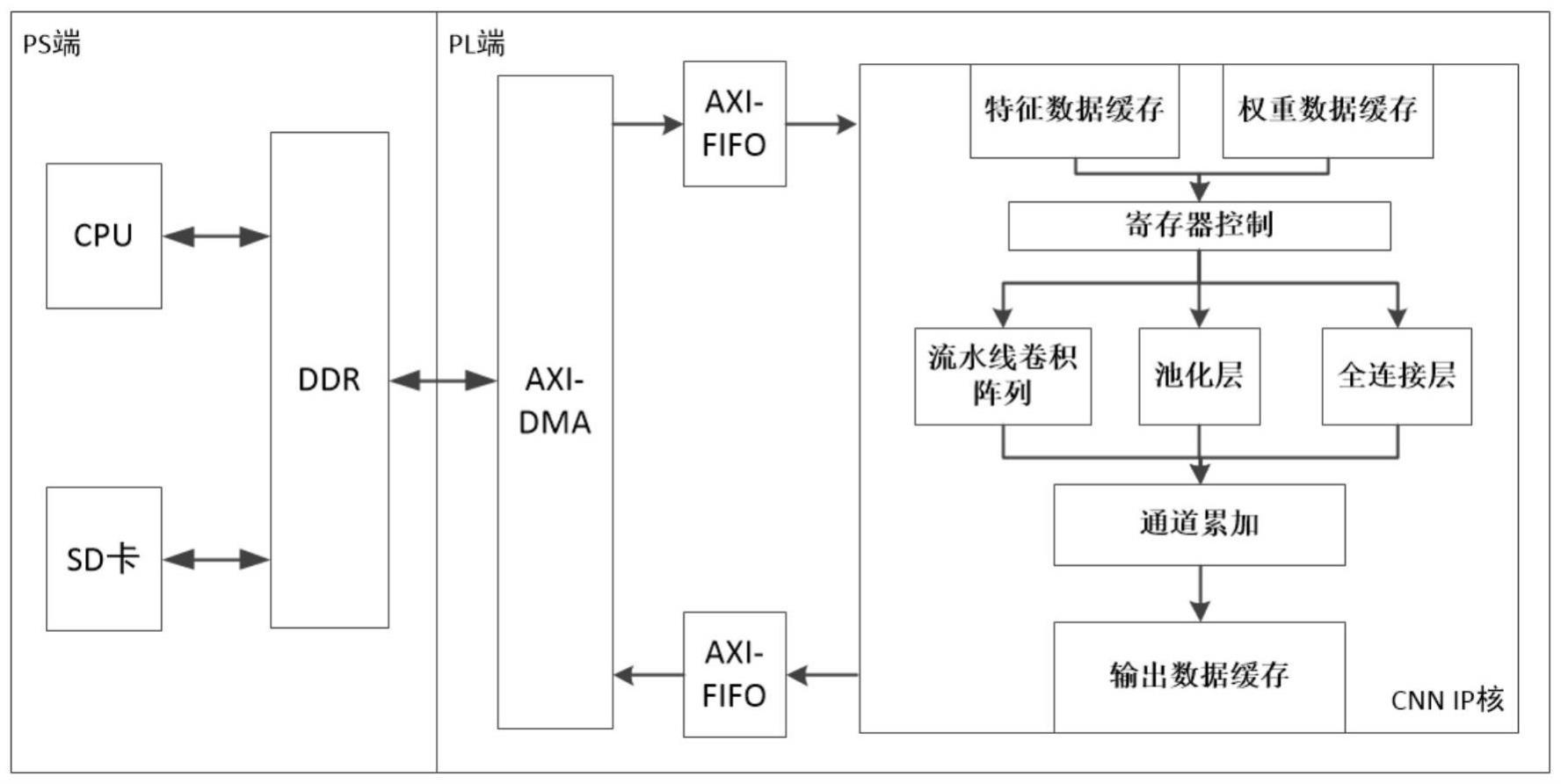
4、步骤1:zynq的ps端通过读取sd卡获取待计算的特征图数据和权重数据,并将其存入ddr内存,并设定pl端加速器的运行参数;
5、步骤2:ps端通过axi_dma将数据从ps端传输到pl端上的特征数据缓存模块和权重数据缓存模块中,并根据运行参数从数据缓存模块取出分块数据传输到卷积模块进行并行卷积运算,量化输出结果;
6、步骤3:根据运行参数决定对输出结果是否进行池化,之后输入通道累加与输出缓存模块后通过axi_dma输出到ps端ddr内存,并由ps端重新配置pl端加速器的控制寄存器来修改运行参数,进行下一层卷积神经网络计算;
7、步骤4:重复执行步骤2和步骤3,当卷积层全部完成后,运行三层全连接层,每层输出值存储在片上缓存中,直接输入下一层全连接层;
8、步骤5:所有层计算完成后,通过axi_dma将最终结果传输到ps端ddr中存储,zynq的ps端将结果通过串口传输给上位机。
9、在上述技术方案中,在步骤1中,ps端通过emio输出当前层数信号到pl端,pl端根据当前层数信号设定加速器的运行参数。
10、在上述技术方案中,所述运行参数包括:当前网络层中特征图尺寸、当前网络层卷积核个数、当前网络层计算时输出通道并行度、当前网络层计算时输入通道并行度。
11、在上述技术方案中,在步骤2中,所述ps端通过axi_dma将数据从ps端传输到pl端上的特征数据缓存模块和权重数据缓存模块中,使用两路axi-dma分别传输特征数据和权重数据,并分别将特征数据和权重数据传输到特征数据缓存模块和权重数据缓存模块。
12、在上述技术方案中,在步骤2中,所述特征数据缓存模块由六组bram组成,每组存储多个输入通道的一行数据,采用串入并出的工作逻辑,并复用感受野间重叠的行列数据,输出4×4尺寸的多通道特征数据切片。
13、在上述技术方案中,在步骤2中,所述权重数据缓存模块存储经过winograd预变换后的权重数据,并将其切分后存储在多个bram中,读取时同时从多个bram中读取数据并组合为整个矩阵合并的权重数据。
14、在上述技术方案中,在步骤2中,所述量化输出结果,是将经过卷积和累加后位宽增加的计算结果数据通过移位和约去小数位的方式重新得到int8数据,其中移位后根据小数位的值判断是否进位,并根据移位后数据大小和int8数据范围的关系判断是否对数据进行截断操作。
15、在上述技术方案中,在步骤3中,所述池化操作直接衔接于卷积计算之后,并对winograd卷积计算输出的矩阵通过比较树的方式两两比较得到池化数据。
16、在上述技术方案中,在步骤3中,所述通道累加与输出缓存模块使用乒乓缓存的方式设计为两组,一组累加输入时另一组输出,完成后两组功能切换,使数据输入不会因数据输出而中断。
17、在上述技术方案中,在步骤4中,最后一层卷积层计算完成后,数据不再输出到ps端ddr中,而是直接保存于片上缓存,输出到量化模块或全连接层模块中使用。
18、本发明具有以下有益效果:
19、1、本发明设计的硬件8bit定点量化方案降低了网络模型大小和内存带宽需求。
20、2、本发明通过参数化设计复用硬件结构,节省了片上有限的硬件资源。
21、3、本发明通过串入并出、重叠数据复用、乒乓缓存等方式提高数据传输效率,实现了特征数据的行列数据复用,提高了数据复用率。
22、4、本发明在通道累加与输出缓存模块实现无缝计算输出,避免因数据输出而阻塞计算。
23、5、本发明设计池化模块和全连接层模块使用层融合的设计思想,减少层间时间损耗。
技术特征:
1.一种基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤1中,ps端通过emio输出当前层数信号到pl端,pl端根据当前层数信号设定加速器的运行参数。
3.根据权利要求2所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,所述运行参数包括:当前网络层中特征图尺寸、当前网络层卷积核个数、当前网络层计算时输出通道并行度、当前网络层计算时输入通道并行度。
4.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤2中,所述ps端通过axi_dma将数据从ps端传输到pl端上的特征数据缓存模块和权重数据缓存模块中,使用两路axi-dma分别传输特征数据和权重数据,并分别将特征数据和权重数据传输到特征数据缓存模块和权重数据缓存模块。
5.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤2中,所述特征数据缓存模块由六组bram组成,每组存储多个输入通道的一行数据,采用串入并出的工作逻辑,并复用感受野间重叠的行列数据,输出4×4尺寸的多通道特征数据切片。
6.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤2中,所述权重数据缓存模块存储经过winograd预变换后的权重数据,并将其切分后存储在多个bram中,读取时同时从多个bram中读取数据并组合为整个矩阵合并的权重数据。
7.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤2中,所述量化输出结果,是将经过卷积和累加后位宽增加的计算结果数据通过移位和约去小数位的方式重新得到int8数据,其中移位后根据小数位的值判断是否进位,并根据移位后数据大小和int8数据范围的关系判断是否对数据进行截断操作。
8.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤3中,所述池化操作直接衔接于卷积计算之后,并对winograd卷积计算输出的矩阵通过比较树的方式两两比较得到池化数据。
9.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤3中,所述通道累加与输出缓存模块使用乒乓缓存的方式设计为两组,一组累加输入时另一组输出,完成后两组功能切换,使数据输入不会因数据输出而中断。
10.根据权利要求1所述的基于zynq平台的vgg16网络加速器设计实现方法,其特征在于,在步骤4中,最后一层卷积层计算完成后,数据不再输出到ps端ddr中,而是直接保存于片上缓存,输出到量化模块或全连接层模块中使用。
技术总结
本发明涉及一种基于ZYNQ平台的VGG16网络加速器设计实现方法,包括步骤:ZYNQ的PS端通过读取SD卡获取待计算的特征图数据和权重数据;PS端通过AXI_DMA将数据从PS端传输到PL端上的特征数据缓存模块和权重数据缓存模块中;根据运行参数决定对输出结果是否进行池化。本发明中硬件8bit定点量化方案降低了网络模型大小和内存带宽需求;通过参数化设计复用硬件结构,节省了片上有限的硬件资源;通过串入并出、重叠数据复用、乒乓缓存等方式提高数据传输效率,实现了特征数据的行列数据复用,提高了数据复用率;在通道累加与输出缓存模块实现无缝计算输出,避免因数据输出而阻塞计算;池化模块和全连接层模块使用层融合的设计思想,减少层间时间损耗。
技术研发人员:孙海江,牛朝旭
受保护的技术使用者:中国科学院长春光学精密机械与物理研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!