一种多层级智能体同步嵌套训练方法与流程
本发明涉及多智能体训练,具体而言,涉及一种多层级智能体同步嵌套训练方法。
背景技术:
1、随着人工智能技术的飞速发展,基于深度强化学习算法的智能体训练成为研究热点。在学术界,学者主要对深度强化学习算法进行研究和验证,通常基于相对简单的仿真场景构建单智能体或同级多智能体。但是,实际应用中通常是多阶段的复杂任务场景,为此,有人提出根据复杂场景中任务决策和行为决策需求,分别构建上级智能体和下级智能体,并给出多层智能体训练架构,如图1所示,该多层级智能体训练架构采用单层训练循环,上下级智能体基于全局评价器计算生成的全局奖励值同时进行迭代训练。但是,由于全局奖励通常比较稀疏,而下级智能体的决策频率较高,导致基于全局评价器的多层级智能体同步训练通常难以收敛。在工程实践中通常采用两种方式解决以上问题:
2、一是将全局评价器增加自定义奖励函数使得奖励密集,但是人工设置的奖励条件通常需要反复调整参数值才能引导智能体优化;
3、二是将下级智能体采用基于知识规则的弱智能体,只需对上级智能体进行训练,但其智能水平和泛化性不如基于神经网络构建的强智能体。
4、因此,针对多层级智能体训练收敛难的问题,需要通过研究提出更有效的解决方法。
技术实现思路
1、本发明旨在提供一种多层级智能体同步嵌套训练方法,以解决复杂仿真场景下多层级智能体训练难以收敛的问题。
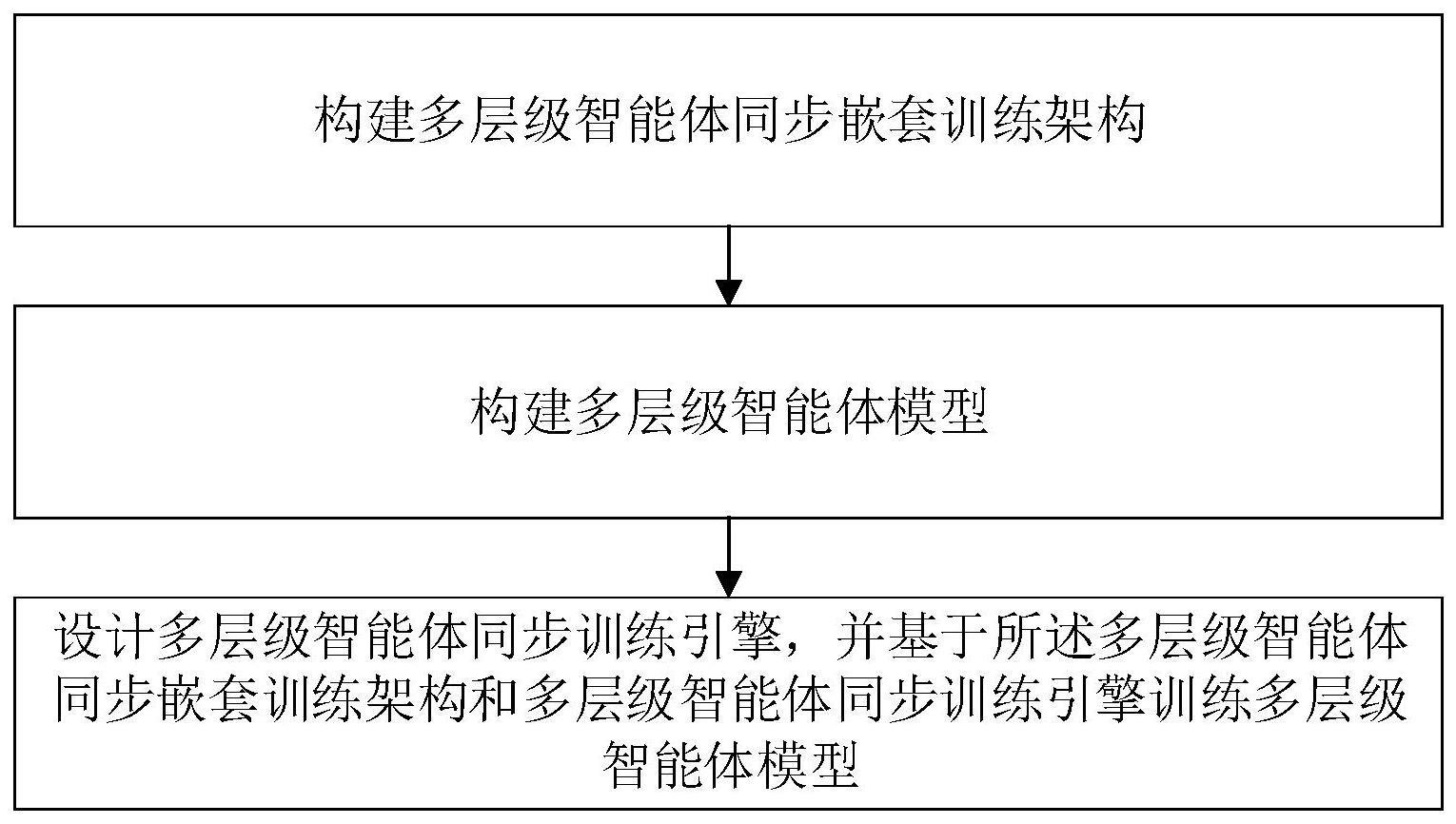
2、本发明提供的一种多层级智能体同步嵌套训练方法,包括:
3、构建多层级智能体同步嵌套训练架构;
4、构建多层级智能体模型;
5、设计多层级智能体同步训练引擎,并基于所述多层级智能体同步嵌套训练架构和多层级智能体同步训练引擎训练多层级智能体模型。
6、进一步的,所述多层级智能体同步嵌套训练架构包括训练上级智能体的外循环和嵌套在外循环内的训练下级智能体的内循环;
7、所述外循环的优化目标是通过调整上级智能体的神经网络参数最大化全局累积奖励值,即最大化全局即时奖励值的加权和;
8、所述内循环的优化目标是在上级策略不变的时间跨度内,通过调整下级智能体的神经网络参数最大化内部累积奖励值,即最大化内部即时奖励值的加权和。
9、其中,所述全局即时奖励值根据外部仿真环境反馈信息进行设计,所述内部即时奖励值根据上级生成的任务目标进行设计。具体地:
10、所述外循环的全局累积奖励值计算式表示为:
11、
12、所述内循环的全局累积奖励值计算式表示为:
13、
14、其中,π表示上级智能体的神经网络参数,ω表示下级智能体的神经网络参数;t表示单次运行最长任务时长,t0到t1表示子任务时间跨度;γ∈[0,1)表示奖励折扣因子,ft表示全局即时奖励函数,rt表示内部即时奖励函数,st,st+1分别表示在t和t+1时刻外部仿真环境反馈的态势信息state,gt表示上级智能体生成的任务决策结果goal,at表示下级智能体生成的行为决策结果action。
15、进一步的,所述构建多层级智能体模型为根据具体的训练场景进行多层级智能体模型的功能设计和代码开发,具体包括:
16、上级智能体基于较长时间跨度内的外部仿真环境反馈信息,进行包括任务目的、力量分配和协同队形的任务决策更新;所述较长时间跨度是指子任务时间跨度;
17、下级智能体根据上级智能体生成的任务决策结果,结合较短时间跨度内的外部仿真环境反馈信息生成包括平台机动和载荷运用的行为决策;所述较短时间跨度是指单仿真步长时间跨度;
18、每个所述上级智能体和下级智能体都包括初始神经网络结构ω0、状态空间st、决策空间gt或at以及奖励函数ft或rt的代码开发。
19、进一步的,为有效控制上级智能体和下级智能体的同步嵌套训练过程,所述多层级智能体同步训练引擎包括数据采样器、训练控制器、模型训练器和指令生成器;所述模型训练器包括上级智能体训练器和下级智能体训练器;
20、所述数据采样器用于采集外部仿真环境反馈信息,并通过预处理生成训练样本;
21、所述训练控制器用于自适应切换上级智能体训练器和下级智能体训练器运行,从而实现同步嵌套训练持续运行;所述同步嵌套训练的方法包括:根据下级智能体训练是否收敛控制内循环训练运行;根据单次任务是否结束以及上级智能体训练是否收敛控制外循环训练运行;基于多层级智能体同步嵌套训练架构,当上级智能体收敛,则多层级智能体实现同步收敛,结束训练。
22、所述模型训练器用于训练运行过程控制和多层级智能体模型训练优化;所述上级智能体训练器和下级智能体训练器均是根据训练样本中的外部仿真环境反馈信息,利用深度强化学习算法对对应的上级智能体和下级智能体的神经网络进行参数优化;其中:上级智能体训练器是基于训练样本中在全任务周期内基于各子任务的外部仿真环境反馈信息对上级智能体进行迭代训练;下级智能体训练器是基于训练样本中在子任务阶段内根据单仿真步长的外部仿真环境反馈信息对下级智能体进行迭代训练。
23、所述指令生成器用于根据智能决策结果生成控制指令;所述智能决策结果包括训练后的上级智能体输出的任务决策结果和下级智能体输出的行为决策结果。其中,需要按照预设的格式将智能决策结果转化为外部仿真环境能够识别的控制指令。
24、综上所述,由于采用了上述技术方案,本发明的有益效果是:
25、本发明提出一种多层级智能体同步嵌套训练架构,并通过设计合理的多层级智能体模型和有效的多层级智能体同步训练引擎,可支撑多层级智能体进行同步嵌套训练,从而实现复杂场景下的多层级智能体同步收敛。
技术特征:
1.一种多层级智能体同步嵌套训练方法,其特征在于,包括:
2.根据权利要求1所述的多层级智能体同步嵌套训练方法,其特征在于,所述多层级智能体同步嵌套训练架构包括训练上级智能体的外循环和嵌套在外循环内的训练下级智能体的内循环;
3.根据权利要求2所述的多层级智能体同步嵌套训练方法,其特征在于,所述全局即时奖励值根据外部仿真环境反馈信息进行设计,所述内部即时奖励值根据上级生成的任务目标进行设计。
4.根据权利要求3所述的多层级智能体同步嵌套训练方法,其特征在于,所述外循环的全局累积奖励值计算式表示为:
5.根据权利要求3所述的多层级智能体同步嵌套训练方法,其特征在于,所述内循环的全局累积奖励值计算式表示为:
6.根据权利要求2-5任一项所述的多层级智能体同步嵌套训练方法,其特征在于,所述构建多层级智能体模型为根据具体的训练场景进行多层级智能体模型的功能设计和代码开发,具体包括:
7.根据权利要求6所述的多层级智能体同步嵌套训练方法,其特征在于,所述多层级智能体同步训练引擎包括数据采样器、训练控制器、模型训练器和指令生成器;所述模型训练器包括上级智能体训练器和下级智能体训练器;
8.根据权利要求7所述的多层级智能体同步嵌套训练方法,其特征在于,所述同步嵌套训练的方法包括:
9.根据权利要求7所述的多层级智能体同步嵌套训练方法,其特征在于,所述上级智能体训练器和下级智能体训练器均是根据训练样本中的外部仿真环境反馈信息,利用深度强化学习算法对对应的上级智能体和下级智能体的神经网络进行参数优化;其中:
10.根据权利要求7所述的多层级智能体同步嵌套训练方法,其特征在于,所述指令生成器需要按照预设的格式将智能决策结果转化为外部仿真环境能够识别的控制指令。
技术总结
本发明提供一种多层级智能体同步嵌套训练方法,包括:构建多层级智能体同步嵌套训练架构;构建多层级智能体模型;设计多层级智能体同步训练引擎,并基于所述多层级智能体同步嵌套训练架构和多层级智能体同步训练引擎训练多层级智能体模型。本发明提出一种多层级智能体同步嵌套训练架构,并通过设计合理的多层级智能体模型和有效的多层级智能体同步训练引擎,可支撑多层级智能体进行同步嵌套训练,从而实现复杂场景下的多层级智能体同步收敛。
技术研发人员:马春华,张萌,王朝,刘盼盼,蒋少强,宿丁,何杰
受保护的技术使用者:中国电子科技集团公司第二十九研究所
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!