视网膜出血区域识别方法及系统与流程
本发明涉及图像处理,具体地涉及一种视网膜出血区域识别方法及一种视网膜出血区域识别系统。
背景技术:
1、传统的图像处理方法与深度学习方法在对视网膜眼底图像出血区域进行识别分割研究时,通常都是按照传统的预处理方式对数据进行处理,比如亮度平衡、对比度增强、去噪、标准化等等,然后直接利用模型对预处理数据进行识别分割研究。然而视网膜出血区域不同于其他眼底组织结构,比如血管、视盘、黄斑等。其他眼底组织结构在视网膜眼底图像中是作为显性目标是必定存在的,出血在正常的视网膜中是不会出现的症状。并且其形状特征没有规则,大小不一,分布情况随机,在进行识别时,必定会受到像血管、视盘等显性目标的影响。之前的学者在进行出血区域识别分割研究时,很少考虑到其他眼底组织结构对于出血区域的影响。
2、针对现有方案因为未考虑其他眼底组织结构对于出血区域的影响导致的视网膜出血识别结果不准确的问题,需要创造一种新的视网膜出血区域识别的方案。
技术实现思路
1、本发明实施方式的目的是提供一种视网膜出血区域识别方法及系统,以至少解决现有方案因为未考虑其他眼底组织结构对于出血区域的影响导致的视网膜出血识别结果不准确的问题。
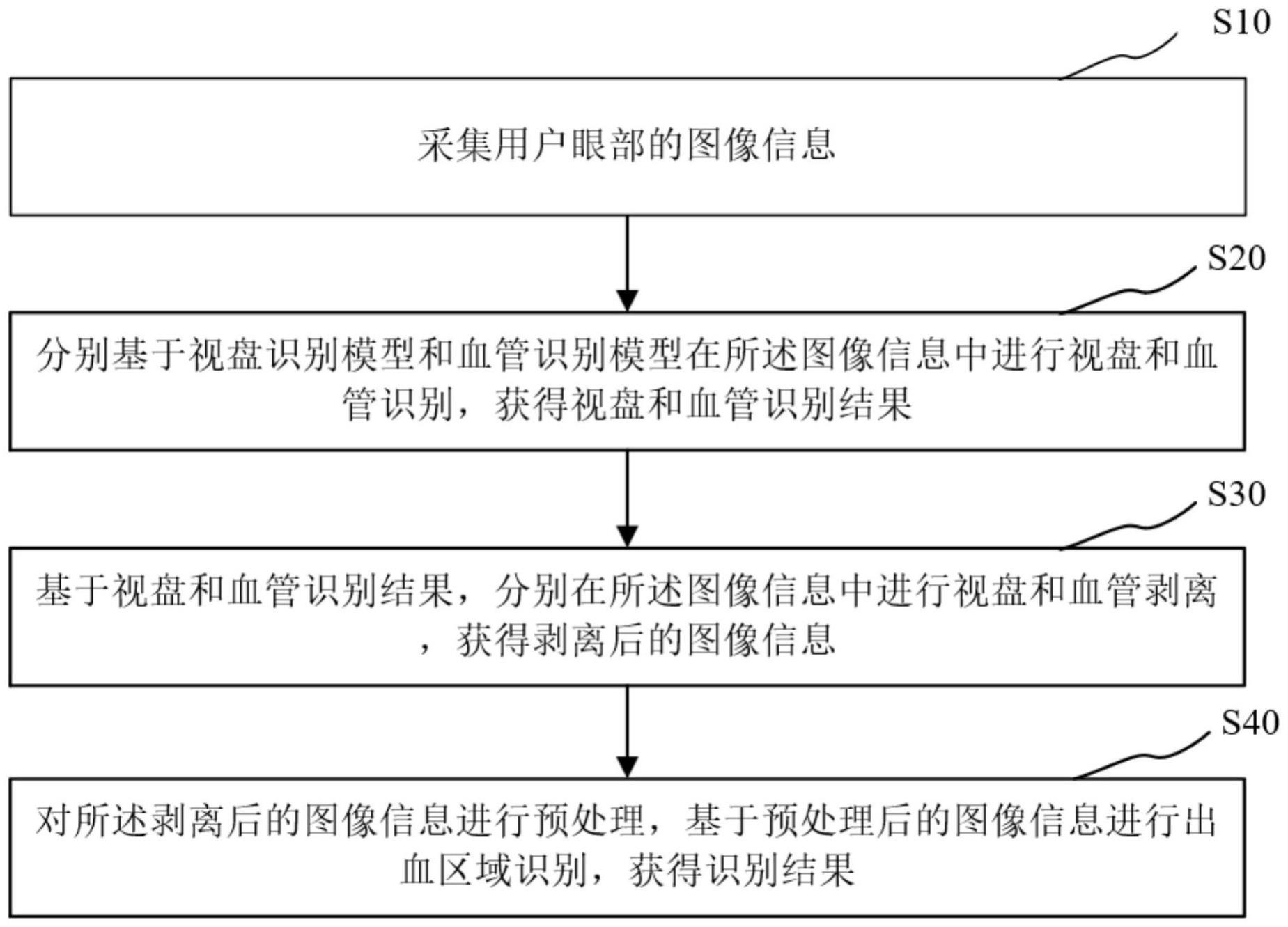
2、为了实现上述目的,本发明第一方面提供一种视网膜出血区域识别方法,所述方法包括:采集用户眼部的图像信息;分别基于视盘识别模型和血管识别模型在所述图像信息中进行视盘和血管识别,获得视盘和血管识别结果;基于视盘和血管识别结果,分别在所述图像信息中进行视盘和血管剥离,获得剥离后的图像信息;对所述剥离后的图像信息进行预处理,基于预处理后的图像信息进行出血区域识别,获得识别结果。
3、可选的,所述视盘识别模型为unet++模型;所述血管识别模型为dc-unet模型。
4、可选的,完成视盘和血管剥离后,所述方法还包括:对视盘和血管剥离区域进行像素填充,包括:将待填充区域的轮廓相邻区域像素值映射到三维坐标空间;基于待填充区域的轮廓相邻区域像素在所述三维坐标空间中的分布,利用三维空间坐标中像素的密度对所有像素值进行聚类,获得聚类后的像素值;基于所述聚类后的像素值对填充像素进行取值;基于取值的填充像素进行剥离区域像素填充;其中,
5、填充像素的计算式为:
6、
7、其中,m表示所有被归类的像素总个数;m表示一种聚类中所有像素个数;p为填充像素;n为种类数量。
8、可选的,利用三维空间坐标中像素的密度对所有像素值进行聚类,所使用的聚类算法为改进的dbscan算法,聚类过程包括:在三维空间坐标中预设初始半径和最小样本数;随机选择一个未被访问的像素点,基于初始半径找到基于该初始半径可以到达的所有像素点并统计点数量;对比统计的点数量和所述最小样本数,若统计的点数量大于所述最小样本数,则将本次选择的像素点作为核心点,并创建一个新的簇;反之,则将本次选择的像素点作为噪声;基于确定的核心点进行扩散聚类,直到遍历所有像素点。
9、可选的,所述对所述剥离后的图像信息进行预处理,包括:基于预设的不同的预处理模型,分别对所述剥离后的图像信息进行预处理,对应获得各预处理模型下的预处理后的图像信息;对比各预处理模型下的预处理后的图像信息,基于预设标准进行分割效果对比,识别出分割效果最好的预处理模型下的预处理后的图像信息,作为预处理结果。
10、可选的,所述不同的预处理模型包括:单一亮度平衡模型、单一对比度增强模型、单一去噪模型、亮度平衡和对比度增强组合模型、去噪和亮度平衡组合模型、去噪和对比度增强组合模型、去噪加亮度平衡加对比度增强组合模型。
11、可选的,所述基于预处理后的图像信息进行出血区域识别,包括:在预处理完成后,将预处理后的图像信息作为入参,在预构建的出血识别模型中进行训练,获得训练结果;基于训练结果判断所述预处理后的图像信息是否存在出血区域;若存在,进行出血区域标定。
12、可选的,所述方法还包括:进行出血识别模型训练,包括:在公用数据库中进行眼部图像公用数据集采集,所述公用数据集包括:idrid数据集、drive数据集、stare数据集、chase-db1数据集;采集用户指定的历史图像数据;将所述公用数据集和所述历史图像数据作为训练集,在预设神经网络中进行模型训练,获得出血识别模型。
13、本发明第二方面提供一种视网膜出血区域识别系统,所述系统包括:采集单元,用于采集用户眼部的图像信息;处理单元,用户分别基于视盘识别模型和血管识别模型在所述图像信息中进行视盘和血管识别,获得视盘和血管识别结果;剥离单元,用于基于视盘和血管识别结果,分别在所述图像信息中进行视盘和血管剥离,获得剥离后的图像信息;识别单元,用于对所述剥离后的图像信息进行预处理,基于预处理后的图像信息进行出血区域识别,获得识别结果。
14、另一方面,本发明提供一种计算机可读储存介质,该计算机可读存储介质上储存有指令,其在计算机上运行时使得计算机执行上述的视网膜出血区域识别方法。
15、通过上述技术方案,本发明方案对于采集的眼部图像,首先进行视盘和血管识别,因为这两个组织结构对视网膜出血识别干扰最大,所以基于识别结果进行这两个区域剥离,从而避免其影响后续视网膜出血识别。在完成视盘和视网膜剥离后,在剩余图像中进行视网膜出血识别,保证识别精度。
16、本发明实施方式的其它特征和优点将在随后的具体实施方式部分予以详细说明。
技术特征:
1.一种视网膜出血区域识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述视盘识别模型为unet++模型;所述血管识别模型为dc-unet模型。
3.根据权利要求1所述的方法,其特征在于,完成视盘和血管剥离后,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,利用三维空间坐标中像素的密度对所有像素值进行聚类,所使用的聚类算法为改进的dbscan算法,聚类过程包括:
5.根据权利要求1所述的方法,其特征在于,所述对所述剥离后的图像信息进行预处理,包括:
6.根据权利要求5所述的方法,其特征在于,所述不同的预处理模型包括:
7.根据权利要求1所述的方法,其特征在于,所述基于预处理后的图像信息进行出血区域识别,包括:
8.根据权利要求1所述的方法,其特征在于,所述方法还包括:进行出血识别模型训练,包括:
9.一种视网膜出血区域识别系统,其特征在于,所述系统包括:
10.一种计算机可读储存介质,该计算机可读存储介质上储存有指令,其在计算机上运行时使得计算机执行权利要求1-8中任一项权利要求所述的视网膜出血区域识别方法。
技术总结
本发明实施例提供一种视网膜出血区域识别方法及系统,属于图像处理技术领域。视网膜出血区域识别方法,所述方法包括:采集用户眼部的图像信息;分别基于视盘识别模型和血管识别模型在所述图像信息中进行视盘和血管识别,获得视盘和血管识别结果;基于视盘和血管识别结果,分别在所述图像信息中进行视盘和血管剥离,获得剥离后的图像信息;对所述剥离后的图像信息进行预处理,基于预处理后的图像信息进行出血区域识别,获得识别结果。本发明方案在完成视盘和视网膜剥离后的图像中进行视网膜出血识别,保证了识别精度。
技术研发人员:段孟舸,段俊国,王红军,王桂林
受保护的技术使用者:广州黄埔银海光圈医疗科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!