一种基于组件化的计算引擎数据处理方法及系统与流程
本发明涉及数据处理,具体涉及一种基于组件化的计算引擎数据处理方法及系统。
背景技术:
1、近年来,计算引擎构建得到了各大互联网公司以及国内外研究人员的重视,围绕着计算引擎构建展开了多个相关技术领域的探索和尝试,其中最为流行的要属分布式计算引擎。随着我国大数据领域的快速发展,针对大数据计算,所产生的计算引擎工具应接不暇,计算引擎的应用前景十分广阔。对于用户来讲,数据库中已经存储了大量的数据,包括结构化的和非结构化的,但是分布在不同的系统,各个业务系统从这些数据库中取数据的需求和情况越来越多,已经形成了难以维护管理的“蜘蛛网”,需要建立统一的数据管理和访问平台,便于统一维护和管理,提供一站式的数据访问服务。
2、引擎数据架构的主要思想是将大数据系统架构分为多个层次,分别为离线处理层batch layer、实时处理层speed layer、服务层serving layer。而且,对于离线处理层和实时处理层的数据处理是基于各自不同的函数实现。但是,该不同的函数在现有技术中没有统一的逻辑层,为保证函数逻辑相同,离线处理层和实时处理层需要开发人员进行人为控制,以维护至少两套不同的核心代码逻辑,而这会增加系统维护难度及成本,还会造成处理层的处理结果的质量差异。能强大的管理平台也仍然存在一些不足:
3、1、在数据处理层面,单一数据计算引擎计算框架往往总存在对某种数据处理场景下的数据处理的不适应。
4、2、在数据存储层面,企业的生产数据类型多种多样,一种存储平台很难满足企业所有类型的数据的高并发、高吞吐、低时延读写访问的需求。
5、3、在平台易用性层面,用户掌握某种数据处理工具有着较高的技术门槛,往往需要专业人士经过长时间的学习才能掌控一种大数据平台的使用。且通过大数据平台构建一种数据处理任务往往需要复杂的过程,耗时、耗力。
技术实现思路
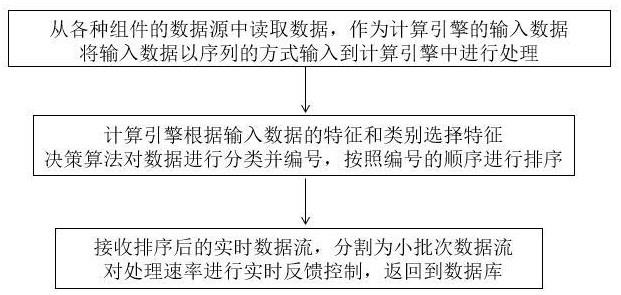
1、为了解决上述技术问题,本发明提出了一种基于组件化的计算引擎数据处理方法,包括如下步骤:
2、s1、从各种组件的数据源中读取数据,作为计算引擎的输入数据,将输入数据以序列的方式输入到计算引擎中进行处理;
3、s2、计算引擎根据输入数据的特征和类别选择特征决策算法对数据进行分类并编号,按照编号的顺序进行排序;
4、s3、接收按类别排序后的实时数据流,分割为小批次数据流输出,对输出的处理速率进行实时反馈控制,返回到数据库。
5、进一步地,步骤s2中:对于具有特征a的数据集合z1,在数据集合z1中里抽取任意样本r,同时随机抽取相同类别的邻近样本s,以及不同类别的异类样本d,如果任意样本r和邻近样本s的距离小于任意样本r和异类样本d的距离,则说明该特征a对区分同类和不同类的最近邻是有益的,则增加特征a的权重;反之,任意样本r和邻近样本s的距离大于样本r和异类样本d的距离,说明该特征a对区分同类和不同类的最近邻起负面作用,则降低特征a的权重。
6、进一步地,重新抽取任意样本r,过程重复m次,最后得出特征a的平均权重w(a),公式为:
7、;
8、diff(a,r,s)表示任意样本r和邻近样本s在特征a上的差值, diff(a,r,d)表示任意样本r和异类样本d在特征a上的差值。
9、进一步地,提取数据集合z1中具有相同类别c的k个样本构成数据集合z2,在数据集合z2中抽取任意样本b,得到类别c的权重w(c)为:
10、;
11、其中,p(c)为数据集合z2中类别为c的数据个数与数据集合z1的总数据个数的比值,p(b)为数据集合z2中样本b的个数与数据集合z2的总数据个数的比值,代表的是不在样本b中的类别为c的样本j,样本j的个数为k。
12、进一步地,步骤s3包括:
13、s3.1、接收按类别排序后的实时数据流,按照不同数据类别将排序后的实时数据流分割为小批次数据流,向外输出;
14、s3.2、对输出数据流的处理速率进行实时监测,按照数据处理速率上限处理数据流;
15、s3.3、在本批次数据流处理完成之后,将处理后的数据流批次返回到数据库。
16、进一步地,步骤s31中,接收按类别排序后的实时数据流,按照不同数据类别分段为l1、l2、l3、…、ln-1、ln,其中,上述n个分段中每段的数据量分别为r1、r2、r3、…、rn-1、rn,其中最小数据量为rmin,最大数据量为rmax。
17、设定单段的数据量不低于r0,设定单段中的数据量满足以下公式:
18、。
19、进一步地,步骤s32中,在批次开始时,提交当前批次的开始时间t1给速率控制器;
20、在批次完成时,提交当前批次的处理结束时间t2给速率控制器,处理该批次用时为t,设该批次在批次队列中的等待时间为tw,该批次处理数据的数据量为nrn;
21、在当前批次提交时,对当前批次的数据处理速率上限v进行计算:
22、v=vlate-kp×er-ki×er-kd×dr;
23、vlate=(t+tw)/nrn;
24、其中,vlate为最新处理完成批次的数据输出速率上限;kp为比例系数,er为数据处理速率的估计误差;ki为积分系数;er为数据处理速率的累积误差;kd为微分系数,为了减小噪声数据对系统的影响;dr为处理速率变化率。
25、本发明还提出了一种基于组件化的计算引擎数据处理系统,用于实现计算引擎数据处理方法,包括:多个微引擎,特征决策单元,控制单元和数据库;
26、多个微引擎对应多个组件,从各种组件的数据源中读取数据,作为计算引擎的输入数据,将输入数据以序列的方式输入到计算引擎中进行处理;
27、计算引擎根据输入数据的特征和类别通过特征决策单元对数据进行分类并编号,按照编号的顺序进行排序;
28、控制单元接收按类别排序后的实时数据流,分割为小批次数据流输出,对输出的处理速率进行实时反馈控制,返回到数据库。
29、进一步地,所述控制单元还包括:分割模块和速率控制器;
30、所述分割模块接收按类别排序后的实时数据流,按照不同数据类别将排序后的实时数据流分割为小批次数据流,向外输出;
31、所述速率控制器对输出数据流的处理速率进行实时监测,按照数据处理速率上限处理数据流。
32、相比于现有技术,本发明具有如下有益技术效果:从各种组件的数据源中读取数据,作为计算引擎的输入数据,将输入数据以序列的方式输入到计算引擎中进行处理;计算引擎根据输入数据的特征和类别选择特征决策算法对数据进行分类并编号,按照编号的顺序进行排序;接收排序后的实时数据流,分割为小批次数据流,对处理速率进行实时反馈控制,返回到数据库,本发明将输入数据更快地分类处理,提高计算引擎的处理效率。
技术特征:
1.一种基于组件化的计算引擎数据处理方法,其特征在于,包括如下步骤:
2.根据权利要求1中所述的计算引擎数据处理方法,其特征在于,步骤s2中:对于具有特征a的数据集合z1,在数据集合z1中里抽取任意样本r,同时随机抽取相同类别的邻近样本s,以及不同类别的异类样本d,如果任意样本r和邻近样本s的距离小于任意样本r和异类样本d的距离,则说明该特征a对区分同类和不同类的最近邻是有益的,则增加特征a的权重;反之,任意样本r和邻近样本s的距离大于样本r和异类样本d的距离,说明该特征a对区分同类和不同类的最近邻起负面作用,则降低特征a的权重。
3.根据权利要求2中所述的计算引擎数据处理方法,其特征在于,重新抽取任意样本r,过程重复m次,最后得出特征a的平均权重w(a),公式为:
4.根据权利要求3中所述的计算引擎数据处理方法,其特征在于,提取数据集合z1中具有相同类别c的k个样本构成数据集合z2,在数据集合z2中抽取任意样本b,得到类别c的权重w(c)为:
5.根据权利要求1中所述的计算引擎数据处理方法,其特征在于,步骤s3包括:
6.根据权利要求5中所述的计算引擎数据处理方法,其特征在于,步骤s31中,接收按类别排序后的实时数据流,按照不同数据类别分段为l1、l2、l3、…、ln-1、ln,其中,上述n个分段中每段的数据量分别为r1、r2、r3、…、rn-1、rn,其中最小数据量为rmin,最大数据量为rmax,设定单段的数据量不低于r0,设定单段中的数据量满足以下公式:
7.根据权利要求5中所述的计算引擎数据处理方法,其特征在于,步骤s32中,在批次开始时,提交当前批次的开始时间t1给速率控制器;
8.一种基于组件化的计算引擎数据处理系统,用于实现如权利要求1-7任意一项所述的计算引擎数据处理方法,其特征在于,包括:多个微引擎,特征决策单元,控制单元和数据库;
9.根据权利要求8中所述的计算引擎数据处理系统,其特征在于,所述控制单元还包括:分割模块和速率控制器;
技术总结
本发明提出了一种基于组件化的计算引擎数据处理方法及系统,涉及数据处理技术领域,从各种组件的数据源中读取数据,作为计算引擎的输入数据,将输入数据以序列的方式输入到计算引擎中进行处理;计算引擎根据输入数据的特征和类别选择特征决策算法对数据进行分类并编号,按照编号的顺序进行排序;接收排序后的实时数据流,分割为小批次数据流,对处理速率进行实时反馈控制,返回到数据库,本发明将输入数据更快地分类处理,提高计算引擎的处理效率。
技术研发人员:王心安
受保护的技术使用者:北京智麟科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!