一种面向语义保持的适应性文本数据压缩方法与流程
本发明属于自然语言处理,具体涉及一种面向语义保持的适应性文本数据压缩方法。
背景技术:
1、在当今的信息时代,互联网上每天都产生着海量的文本数据,其涵盖了各个领域。用户在浏览这些文本数据时,往往需要花费大量的时间和精力来阅读和理解其中的内容和意义。而文本摘要作为一种能够帮助用户快速获取文本主要信息的技术,具有非常重要的应用价值。它可以帮助用户节省阅读时间,提高阅读效率,筛选出感兴趣或有用的信息,增强信息检索和分析能力等。然而,文本摘要的属性具有一定的主观性,其内容的符合度与用户的主观判断呈现正相关。在不同的场景和需求下,用户对文本摘要的长度需求也不尽相同。例如,对于不同的显示设备,如手机、电脑、广告大屏幕等设备的可展示内容的大小各不相同,如果将适配电脑屏幕生成的摘要直接放置到广告大屏幕上则会出现显示问题。此外,摘要的长度控制还体现在对特定的位置进行摘要生成。具体来说,对于长文本用户并不想知道所有的内容,只想关注某一特定区域,而使用通用摘要生成得到的摘要并不能关注到特定区域的内容。如果直接使用当前区域进行摘要生成又会遗漏上下文的信息,此时对摘要的长度控制则显得尤为重要。另外,对于计算机来说,计算机对非结构化的文本无法做到有效的管理,因此可对文本摘要的长度进行控制以得到不同信息密度的文本摘要,而这些摘要可以为后续文本结构化提供语料支持,减轻文本结构化的压力,并提高文本结构化的效率。总体来说,在不同场景和需求下摘要需要不同的长度和焦点。对摘要进行长度控制可以提高摘要的质量和准确性,避免生成不完整或不连贯的摘要,同时也增加了摘要的多样性和灵活性。一个好的摘要不仅需要能够概括原文中的内容,还需要尽可能的保持其语义损失最小化。特别是在信息爆炸的时代,不仅是人们越来越依赖摘要来获取信息,对于计算机来说也越来越需要通过合理的信息压缩来实现对信息的管理。因此,掌握摘要长度控制的技术对于提高文章的可读性和提高信息存储的密度尤为重要。通过合理控制摘要长度,可以让文章更加充实,也更容易对文本进行存储和分析。
技术实现思路
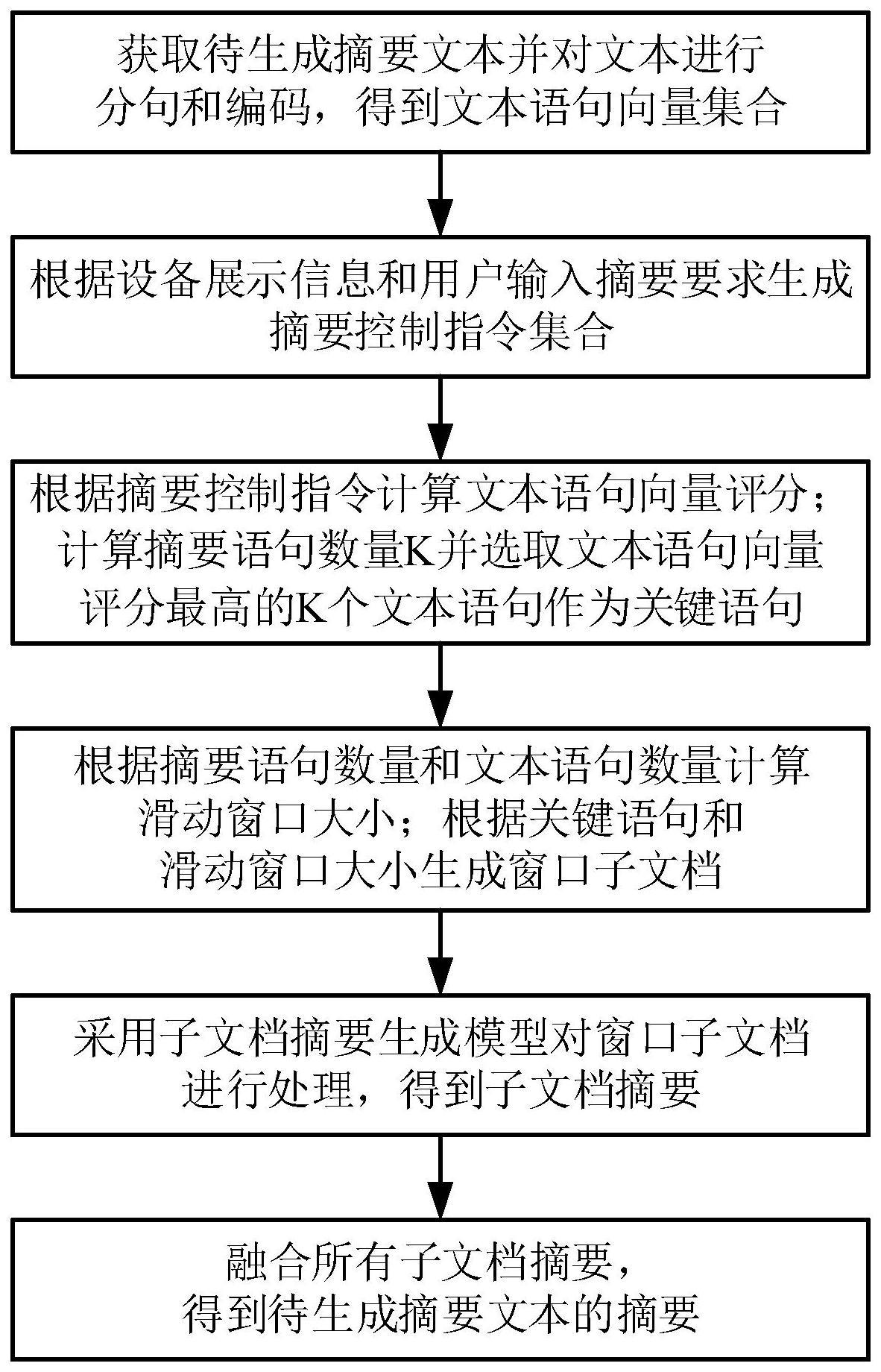
1、针对现有技术存在的不足,本发明提出了一种面向语义保持的适应性文本数据压缩方法,该方法包括:
2、s1:获取待生成摘要文本并对文本进行分句和编码,得到文本语句向量集合;
3、s2:根据设备展示信息和用户输入摘要要求生成摘要控制指令集合;设备展示信息包括设备屏幕大小和设备字体大小;
4、s3:根据摘要控制指令计算文本语句向量评分;计算摘要语句数量k并选取文本语句向量评分最高的k个文本语句作为关键语句;
5、s4:根据摘要语句数量和文本语句数量计算滑动窗口大小;根据关键语句和滑动窗口大小生成窗口子文档;
6、s5:采用子文档摘要生成模型对窗口子文档进行处理,得到子文档摘要;
7、s6:融合所有子文档摘要,得到待生成摘要文本的摘要。
8、优选的,生成摘要控制指令集合的过程包括:将用户输入摘要要求分句,生成用户输入语句序列;根据设备屏幕大小和设备字体大小计算摘要长度;将摘要长度添加到用户输入语句序列中,构成摘要控制序列;对摘要控制序列进行关键词抽取,得到摘要控制关键词集合;去除摘要控制关键词集合中的重复关键词并进行抽象化处理,得到摘要控制指令集合。
9、优选的,计算文本语句向量评分的公式为:
10、
11、其中,imp(hi)表示第i个文本语句向量hi的评分,n表示文本语句向量数量,m表示优化后的摘要控制指令集合中摘要控制指令数量,cj′表示摘要控制指令集合中第j个摘要控制指令向量,score_sentence(hi)表示第i个文本语句向量的句子级评分,score_word(hi)表示第i个文本语句向量的词级评分。
12、优选的,计算摘要语句数量k的过程包括:计算文本的语句平均长度;根据摘要长度和语句平均长度计算摘要语句数量k;计算公式为:
13、
14、其中,pn表示摘要长度,l表示文本的语句平均长度。
15、优选的,计算滑动窗口大小的公式为:
16、
17、其中,q表示滑动窗口大小,s表示源文本的语句集合,len(s)表示源文本的句子数量,k表示摘要语句数量,表示向下取整。
18、优选的,生成窗口子文档的过程包括:截取出关键语句左右两边滑动窗口大小的文字,与关键语句组成窗口子文档;若关键语句一边加上滑动窗口大小后大于文本边界,则只截取另一边滑动窗口大小的文字并与关键语句组成窗口子文档;若两个滑动窗口发生重叠,则将两个窗口子文档合并为一个窗口子文档。
19、优选的,采用子文档摘要生成模型对窗口子文档进行处理的过程包括:
20、抽取窗口子文档中的关键语句,对关键语句中的部分词进行掩码表示;对窗口子文档进行编码并对窗口子文档中的词进行位置编码;
21、将词的位置编码和掩码表示加入编码后窗口子文档对应的语句向量中,根据语句上下文关系添加语句上下文编码,得到模型输入向量;
22、将模型输入向量输入到预训练模型中进行处理,得到输出向量;对输出向量进行解码,得到子文档摘要。
23、优选的,融合所有子文档摘要的过程包括:
24、将子文档摘要按生成顺序整合成一个摘要集合并将其送入编码器进行编码,得到摘要编码;采用解码器对摘要编码进行解码,得到最终生成的完整摘要;其中,在编码阶段融入文本蕴含任务,在解码阶段融入知识图谱任务。
25、本发明的有益效果为:本发明通过获取相应的文本数据和相应的摘要控制指令(用户输入摘要要求),并将二者进行向量化编码,使用自监督的方法对文本中重要信息语句进行抽取,构成相应的窗口子文档,通过计算关键语句的数量来控制子文档数量的多少进而间接的控制生成摘要的长度,使用控制语句来控制用户所偏向的内容。并对子文档进行融合输出,使用文本蕴含和知识图谱来指导子文档摘要的融合。本发明可进一步提高摘要生成的性能,且同时提高了生成摘要内容的灵活性。
技术特征:
1.一种面向语义保持的适应性文本数据压缩方法,其特征在于,包括:
2.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,生成摘要控制指令集合的过程包括:将用户输入摘要要求分句,生成用户输入语句序列;根据设备屏幕大小和设备字体大小计算摘要长度;将摘要长度添加到用户输入语句序列中,构成摘要控制序列;对摘要控制序列进行关键词抽取,得到摘要控制关键词集合;去除摘要控制关键词集合中的重复关键词并进行抽象化处理,得到摘要控制指令集合。
3.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,计算文本语句向量评分的公式为:
4.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,计算摘要语句数量k的过程包括:计算文本的语句平均长度;根据摘要长度和语句平均长度计算摘要语句数量k;计算公式为:
5.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,计算滑动窗口大小的公式为:
6.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,生成窗口子文档的过程包括:截取出关键语句左右两边滑动窗口大小的文字,与关键语句组成窗口子文档;若关键语句一边加上滑动窗口大小后大于文本边界,则只截取另一边滑动窗口大小的文字并与关键语句组成窗口子文档;若两个滑动窗口发生重叠,则将两个窗口子文档合并为一个窗口子文档。
7.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,采用子文档摘要生成模型对窗口子文档进行处理的过程包括:
8.根据权利要求1所述的一种面向语义保持的适应性文本数据压缩方法,其特征在于,融合所有子文档摘要的过程包括:
技术总结
本发明属于自然语言处理技术领域,具体涉及一种面向语义保持的适应性文本数据压缩方法;该方法包括:获取待生成摘要文本并对文本进行分句和编码,得到文本语句向量集合;根据设备展示信息和用户输入摘要要求生成摘要控制指令集合;根据摘要控制指令计算文本语句向量评分;计算摘要语句数量K并选取文本语句向量评分最高的K个文本语句作为关键语句;根据摘要语句数量和文本语句数量计算滑动窗口大小;根据关键语句和滑动窗口大小生成窗口子文档;采用子文档摘要生成模型对窗口子文档进行处理,得到子文档摘要;融合所有子文档摘要,得到待生成摘要文本的摘要本发明可进一步提高摘要生成的性能,且同时提高了生成摘要内容的灵活性。
技术研发人员:常光辉,骆家辉
受保护的技术使用者:重庆安石泽太科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!