一种文本识别方法及相关装置与流程
本申请涉及人工智能,尤其涉及一种文本识别方法及相关装置。
背景技术:
1、光学字符识别(optical character recognition,ocr)是指电子设备检查文件中的字符,通过检测亮、暗的模式确定其形状,然后采用字符识别算法将形状翻译成计算机文字的过程。
2、相关技术中,常采用ocr技术,针对包括文本的图像识别其中的文本;具体的,可以将待识别的文本图像输入预先训练的文本识别模型,文本识别模型通过对该文本图像进行相应处理,将输出该文本图像中包括的文本内容。通常情况下,文本识别模型的输入图像的尺寸是固定的,为了兼容所包括的文字较多的文本图像,一般会针对输入图像设置一个较大的固定尺寸;对于所包括的文字较少的文本图像而言,需要填充背景图像使其达到该固定尺寸。利用文本识别模型处理上述文字较少的文本图像时,将浪费较多的计算资源处理无意义的背景图像,这既会造成性能损失,又会影响文本识别效率。
技术实现思路
1、本申请实施例提供了一种文本识别方法及相关装置,以降低性能损失,提高文本识别效率。
2、本申请第一方面提供了一种文本识别方法,方法包括:
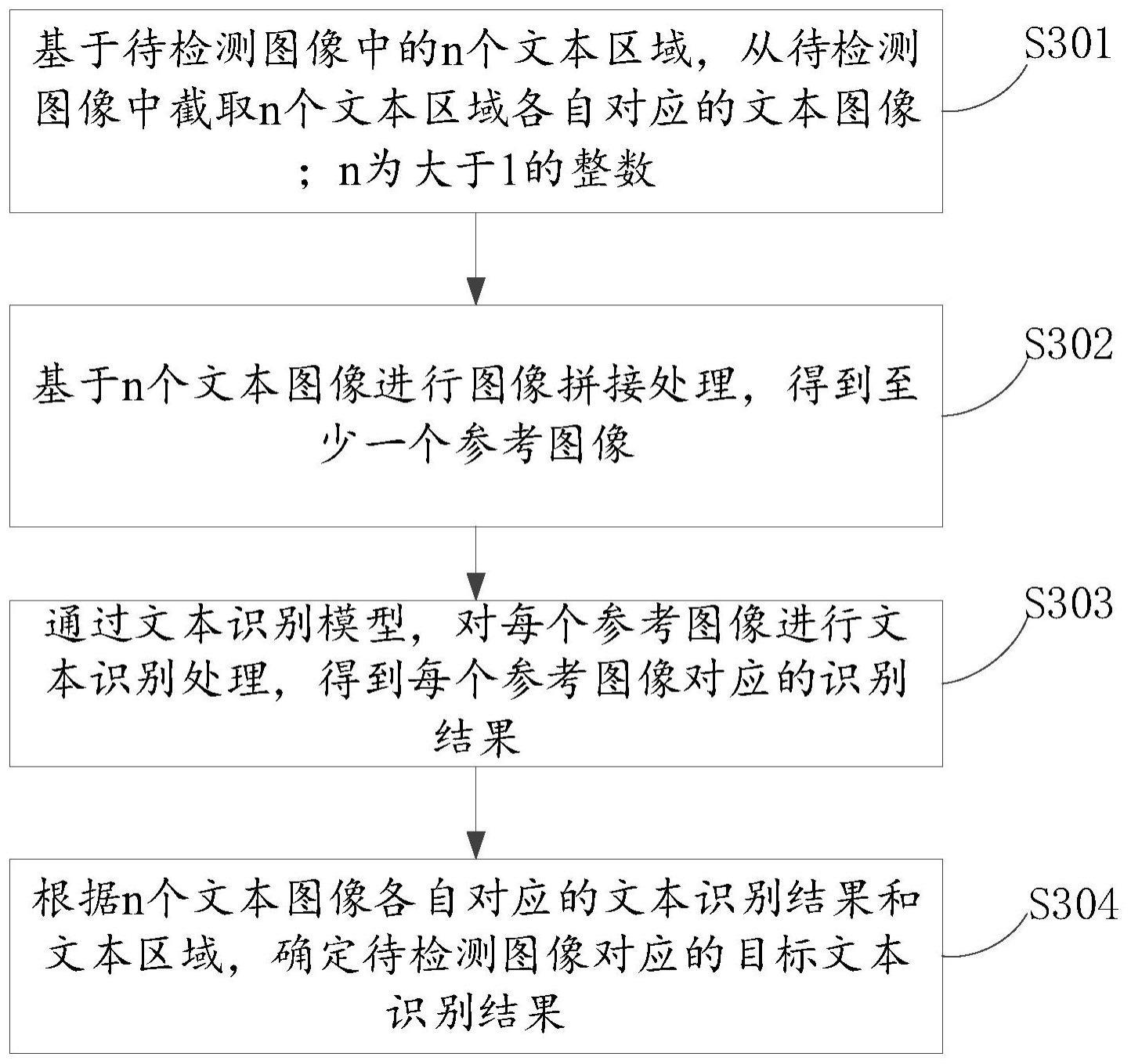
3、基于待检测图像中的n个文本区域,从待检测图像中截取n个文本区域各自对应的文本图像;n为大于1的整数;
4、基于n个文本图像进行图像拼接处理,得到至少一个参考图像;参考图像的尺寸小于或等于文本识别模型的输入图像尺寸,且若参考图像是由多个文本图像拼接得到的,则参考图像中两个相邻的文本图像之间插入有分隔符图像;
5、通过文本识别模型,对每个参考图像进行文本识别处理,得到每个参考图像对应的识别结果;参考图像对应的识别结果包括参考图像中的文本图像对应的文本识别结果;
6、根据n个文本图像各自对应的文本识别结果和文本区域,确定待检测图像对应的目标文本识别结果。
7、本申请第二方面提供了一种文本识别装置,装置包括:
8、图像截取模块,用于基于待检测图像中的n个文本区域,从待检测图像中截取n个文本区域各自对应的文本图像;n为大于1的整数;
9、图像拼接模块,用于基于n个文本图像进行图像拼接处理,得到至少一个参考图像;参考图像的尺寸小于或等于文本识别模型的输入图像尺寸,且若参考图像是由多个文本图像拼接得到的,则参考图像中两个相邻的文本图像之间插入有分隔符图像;
10、文本识别模块,用于通过文本识别模型,对每个参考图像进行文本识别处理,得到每个参考图像对应的识别结果;参考图像对应的识别结果包括参考图像中的文本图像对应的文本识别结果;
11、结果确定模块,用于根据n个文本图像各自对应的文本识别结果和文本区域,确定待检测图像对应的目标文本识别结果。
12、本申请第三方面提供了一种计算机设备,所述设备包括处理器和存储器:
13、所述存储器用于存储计算机程序;
14、所述处理器用于根据所述计算机程序,执行如上述第一方面所述的文本识别方法的步骤。
15、本申请第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行上述第一方面所述的文本识别方法的步骤。
16、本申请第五方面提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述第一方面所述的文本识别方法的步骤。
17、从以上技术方案可以看出,本申请实施例具有以下优点:
18、本申请实施例提供的文本识别方法,在利用文本识别模型对待检测图像进行文本识别处理前,基于待检测图像中多个文本区域各自对应的文本图像进行图像拼接处理,得到参考图像,进而,利用文本识别模型对参考图像进行处理,得到参考图像中的文本图像对应的文本识别结果,最终,利用待检测图像中各个文本图像各自对应的文本结果,确定待检测图像对应的目标文本识别结果。其中,通过将多个文本图像拼接起来作为文本识别模型的处理对象,可以增加文本识别模型每次工作时所需处理的有效信息,使得文本识别模型每次工作时可以识别尽可能多的文本,从而减少性能损失,提高识别效率。
技术特征:
1.一种文本识别方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于n个所述文本图像进行图像拼接处理,得到至少一个参考图像,包括:
3.根据权利要求1或2所述的方法,其特征在于,所述通过所述文本识别模型,对每个所述参考图像进行文本识别处理,得到每个所述参考图像对应的识别结果,包括:
4.根据权利要求3所述的方法,其特征在于,所述通过所述文本识别模型,对每个所述目标参考图像进行文本识别处理,得到每个所述目标参考图像对应的识别结果,包括:
5.根据权利要求1所述的方法,其特征在于,所述参考图像对应的识别结果还包括所述参考图像中的所述分隔符图像对应的分隔符识别结果,在所述根据n个所述文本图像各自对应的文本识别结果和文本区域,确定所述待检测图像对应的目标文本识别结果之前,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述文本识别模型是通过以下方式训练的:
7.根据权利要求6所述的方法,其特征在于,所述基于所述训练样本集合中多个训练样本各自包括的训练文本图像进行图像拼接处理,得到训练参考图像,包括:
8.一种文本识别装置,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,所述计算机设备包括处理器及存储器;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行权利要求1至7中任一项所述的文本识别方法。
技术总结
本申请实施例公开了一种文本识别方法及装置,该方法包括:在利用文本识别模型对待检测图像进行文本识别处理前,基于待检测图像中多个文本区域各自对应的文本图像进行图像拼接处理,得到参考图像,进而,利用文本识别模型对参考图像进行处理,得到参考图像中的文本图像对应的文本识别结果,最终,利用待检测图像中各个文本图像各自对应的文本结果,确定待检测图像对应的目标文本识别结果。其中,通过将多个文本图像拼接起来作为文本识别模型的处理对象,可以增加文本识别模型每次工作时所需处理的有效信息,使得文本识别模型每次工作时可以识别尽可能多的文本,从而减少性能损失,提高识别效率。
技术研发人员:郑岩
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!