一种基于多任务注意力机制的生成式文本摘要方法与流程
本发明涉及电商应用、新闻应用及搜索引擎应用领域,具体涉及一种基于多任务注意力机制的生成式文本摘要方法。
背景技术:
1、近年来,随着互联网技术的迅速发展,互联网成为人们获取信息的重要平台。互联网正在不断地拉近人们之间的距离,人们获取信息的方式也从传统的报纸、电视等逐渐转变成手机、平板、电脑等。由于互联网用户每天在互联网上分享和传递大量以文本形式展现的信息,互联网上的文本信息出现爆发式增长。当用户浏览海量的互联网文本数据时,很难快速准确地获取其中的关键信息。这导致用户需要花费很多的时间和精力去自行概括文本中的重要内容。因此,如何能够从这些海量的长文本中提取出用户最关注的内容,提升对于信息处理的效率,成为了当下自然语言处理领域迫在眉睫的研究工作。
2、例如,在搜索引擎应用领域,需要为每一个搜索结果提供简短的描述,以便用户可以快速地了解检索内容;在新闻应用领域,对于海量新闻素材需要自动生成其新闻标题,用来辅助优化推荐系统;在电商应用领域,需要从众多评论中挖掘出商品的详细描述,生成产品信息介绍标题,为产品的后续推荐与推广提供数据支撑。上述领域,都离不开文本摘要技术。
技术实现思路
1、本发明的目的是提供一种基于多任务注意力机制的生成式文本摘要方法,通过引入不同的任务,来学习文本不同层面的信息表示,指导算法模型生成更符合原文内容、更加流畅的摘要。同时,使用指针生成网络和覆盖机制来缓解未登录词和重复性生成的问题。
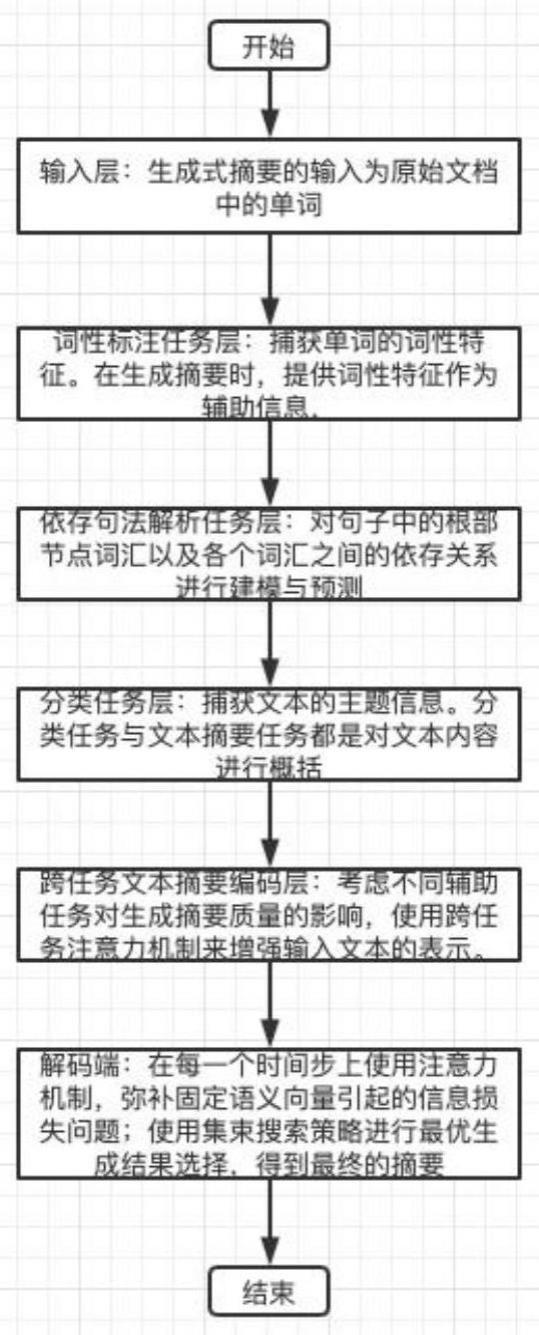
2、为了实现上述目的,本申请的一种基于多任务注意力机制的生成式文本摘要方法,包括如下步骤:
3、s1.输入为原始文档中的单词;
4、s2.捕获单词的词性特征。在生成摘要时,提供词性特征作为辅助信息,指导摘要生成时使用准确的用词;
5、s3.对句子中的根部节点词汇以及各个词汇之间的依存关系进行建模与预测;
6、s4.捕获文本的主题信息;
7、s5.综合考虑不同辅助任务对生成摘要质量的影响,使用跨任务注意力机制来增强输入文本的表示。即:在生成摘要的不同时刻,对编码器端的单词在不同的辅助任务上给予不同的注意力权重;
8、s6.在解码的过程中,在每一个时间步上使用注意力机制,弥补固定语义向量引起的信息损失问题;同时,使用集束搜索策略进行最优生成结果选择,得到最终的摘要。
9、优选地,步骤s2所述将词性标注任务视为一个多分类问题。将文档d进行词嵌入表示得到ew={e1,e2,…,ei,…,en},再将ew输入到词性标注的双向lstm中,得到一组隐藏层输出然后通过分类器对每个单词进行分类,得到每个单词的词性标签
10、优选地,步骤s3所述依存句法任务对于每一个单词,首先,预测其对应的头节点,再预测该单词与其头节点单词之间的依赖弧关系,本方法采用基于图的依存句法解析算法。弧关系预测作为一个分类问题,对于任意两个单词之间的弧关系预测概率表示为:
11、
12、其中,warc,barc为可学习参数。
13、优选地,步骤s4所述分类任务主要是对一篇文章进行类别判断。其作用是判断文本符合哪一个抽象主题,进而更倾向于生成符合主题的单词与句子。本方法分类任务主要从单词层和文档层两个方面来进行衡量文本的归属类别。将句子s的单词和词性标签ypos和弧关系yarc进行嵌入式表示,得到es={e1,e2,…,ei,…,en},和再将hpos,es,epos+0.5*earc拼接后输入到双向lstm中得到随机创建查询向量q和hcat计算注意力机制分布得到将通过分类器得到文本的类别结果ycat。其中,epos+0.5*earc表示每个单词词性标签嵌入表示与弧边关系嵌入表示的和作为分类任务的输入。若单词wi的头节点为wj,弧关系为则这两个单词平均共享其弧关系上的语义信息。
14、优选地,步骤s5所述考虑到编码器端不同任务对于生成式文本摘要的影响不同,本文提出了一种基于多任务学习的注意力机制模型——跨任务注意力机制。在生成摘要的不同时刻,对编码器端的单词在不同的辅助任务上给予不同的注意力权重,即:对每一个单词wi,在词性依存句法和文本分类上给予不同的权重分布。其优点在于,可以很好地捕获在摘要生成的不同时刻,编码器端单词在不同辅助任务上的不同的重要程度及其分布,丰富文本的语义、语法信息。跨任务注意力机制不再依赖于外部信息(查询向量不同),而是使用自身编码端的输出作为查询向量,在不同辅助任务上进行注意力机制的分布计算。同样也与自注意力机制不同,自注意力机制关注的是整个句子的语义信息,旨在消除歧义单词的指代关系,而不是单词本身的属性信息。
15、具体方法是:
16、跨任务注意力机制以作为查询向量qi,以主任务和三个辅助任务的隐状态拼接作为键值k,即,
17、跨任务注意力的计算公式如下:
18、score(qi,kj)=qitkj
19、
20、其中,kj表示键值k中的第j个向量。然后,对注意力机制分布加权求和得到hi,即:
21、
22、优选地,步骤s6所述集束搜索解码是一种启发式搜索算法。该算法首先确定集束大小为b;接着,在每一步解码过程中,选取概率最大的b个单词作为候选单词,然后,将候选单词都到输入到下一步中继续解码,直到产生结束标志符eos,最后,输出概率最大的序列。
技术特征:
1.一种基于多任务注意力机制的生成式文本摘要方法(abssummamtl),其特征在于,
2.根据权利要求1所述的一种基于多任务注意力机制的生成式文本摘要方法,其特征在于,步骤s2所述将词性标注任务视为一个多分类问题。将文档d进行词嵌入表示得到ew={e1,e2,…,ei,…,en},再将ew输入到词性标注的双向lstm中,得到一组隐藏层输出然后通过分类器对每个单词进行分类,得到每个单词的词性标签
3.根据权利要求1所述的一种基于多任务注意力机制的生成式文本摘要方法,其特征在于,步骤s3所述依存句法任务对于每一个单词,首先,预测其对应的头节点,再预测该单词与其头节点单词之间的依赖弧关系,本方法采用基于图的依存句法解析算法。弧关系预测作为一个分类问题,对于任意两个单词之间的弧关系预测概率表示为:
4.根据权利要求1所述的一种基于多任务注意力机制的生成式文本摘要方法,其特征在于,步骤s4所述分类任务主要是对一篇文章进行类别判断。其作用是判断文本符合哪一个抽象主题,进而更倾向于生成符合主题的单词与句子。本方法分类任务主要从单词层和文档层两个方面来进行衡量文本的归属类别。将句子s的单词和词性标签ypos和弧关系yarc进行嵌入式表示,得到es={e1,e2,…,ei,…,en},和再将hpos,es,epos+0.5*earc拼接后输入到双向lstm中得到随机创建查询向量q和hcat计算注意力机制分布得到将通过分类器得到文本的类别结果ycat。其中,epos+0.5*earc表示每个单词词性标签嵌入表示与弧边关系嵌入表示的和作为分类任务的输入。若单词wi的头节点为wj,弧关系为则这两个单词平均共享其弧关系上的语义信息。
5.根据权利要求1所述的一种基于多任务注意力机制的生成式文本摘要方法,其特征在于,步骤s5所述考虑到编码器端不同任务对于生成式文本摘要的影响不同,本文提出了一种基于多任务学习的注意力机制模型——跨任务注意力机制。在生成摘要的不同时刻,对编码器端的单词在不同的辅助任务上给予不同的注意力权重,即:对每一个单词wi,在词性依存句法和文本分类上给予不同的权重分布。其优点在于,可以很好地捕获在摘要生成的不同时刻,编码器端单词在不同辅助任务上的不同的重要程度及其分布,丰富文本的语义、语法信息。跨任务注意力机制不再依赖于外部信息(查询向量不同),而是使用自身编码端的输出作为查询向量,在不同辅助任务上进行注意力机制的分布计算。同样也与自注意力机制不同,自注意力机制关注的是整个句子的语义信息,旨在消除歧义单词的指代关系,而不是单词本身的属性信息。
6.根据权利要求1所述的一种基于多任务注意力机制的生成式文本摘要方法,其特征在于,步骤s6所述集束搜索解码是一种启发式搜索算法。该算法首先确定集束大小为b;接着,在每一步解码过程中,选取概率最大的b个单词作为候选单词,然后,将候选单词都到输入到下一步中继续解码,直到产生结束标志符eos,最后,输出概率最大的序列。
技术总结
本发明提供了一种基于多任务注意力机制的生成式文本摘要方法,过引入不同的任务,来学习文本不同层面的信息表示,指导算法模型生成更符合原文内容、更加流畅的摘要。同时,使用指针生成网络和覆盖机制来缓解未登录词和重复性生成的问题。
技术研发人员:王君,黄宜华
受保护的技术使用者:江苏鸿程大数据技术与应用研究院有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!