动作策略生成模型训练方法、装置、设备及介质与流程
本发明涉及人工智能及医疗健康,尤其涉及一种动作策略生成模型训练方法、装置、设备及介质。
背景技术:
1、随着社会的进步和科技的发展,人们生活水平的不断提高,医疗健康也逐渐引起了人们的重视,其中,抗生素使用策略、药品管理策略、患者管理策略、疫情管理策略等医疗动作策略在医疗健康领域的各个方面向用户进行审视、评估,从而提供指导,例如,现有的抗生素使用策略通常先采用广谱抗生素,获取到菌培养结果之后,根据菌培养结果实施对应的药物使用方案,不仅能够帮助用户提高药品的使用效率和治疗效果,延缓患者对药品产生耐药性,而且能够提高管理效率。
2、但是,相较于其他行业,由于医疗健康领域的涉及广泛,患者、药品、疫情等策略对象的状态存在不确定性,对行业人员的经验、阅历要求又高,往往通过医生、护士等医护人员根据个人经验总结得到的医疗动作策略具有较强局限性,使得动作策略的针对性较弱,降低动作策略的实施效果。
技术实现思路
1、本发明提供一种人工智能的动作策略生成模型训练方法、装置、计算机设备及介质,以加强动作策略的针对性,提高动作策略的实施效果。
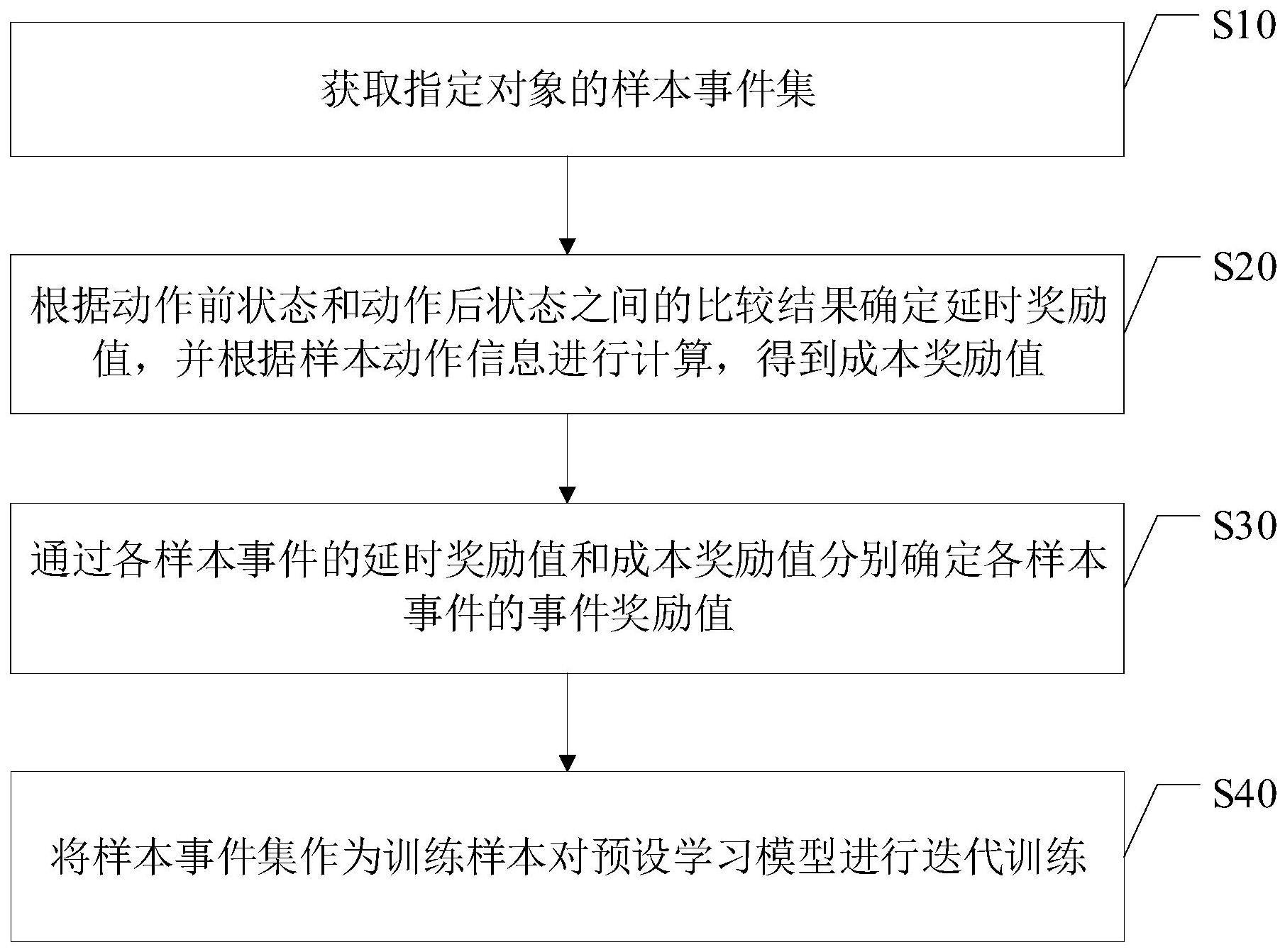
2、第一方面,提供了一种动作策略生成模型训练方法,包括:
3、获取指定对象的样本事件集,其中,所述样本事件集包括多个样本事件,所述样本事件包括动作前状态、样本动作信息、动作后状态;
4、根据所述动作前状态和所述动作后状态之间的比较结果确定延时奖励值,并根据所述样本动作信息进行计算,得到成本奖励值;
5、通过各所述样本事件的延时奖励值和成本奖励值分别确定各所述样本事件的事件奖励值;
6、将所述样本事件集作为训练样本对预设学习模型进行迭代训练,以根据各所述样本事件对应的事件奖励值确定所述预设学习模型是否训练完成,并将训练完成的预设学习模型确定为所述指定对象对应的动作策略生成模型。
7、第二方面,提供了一种动作策略生成模型训练装置,包括:
8、获取模块,用于获取指定对象的样本事件集,其中,所述样本事件集包括多个样本事件,所述样本事件包括动作前状态、样本动作信息、动作后状态;
9、计算模块,用于根据所述动作前状态和所述动作后状态之间的比较结果确定延时奖励值,并根据所述样本动作信息进行计算,得到成本奖励值;
10、确定模块,用于通过各所述样本事件的延时奖励值和成本奖励值分别确定各所述样本事件的事件奖励值;
11、训练模块,用于将所述样本事件集作为训练样本对预设学习模型进行迭代训练,以根据各所述样本事件对应的事件奖励值确定所述预设学习模型是否训练完成,并将训练完成的预设学习模型确定为所述指定对象对应的动作策略生成模型。
12、第三方面,提供了一种计算机设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述动作策略生成模型训练方法的步骤。
13、第四方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述动作策略生成模型训练方法的步骤。
14、上述动作策略生成模型训练方法、装置、设备及介质所实现的方案中,通过采集指定对象的样本事件,从而根据样本事件中的动作前状态、动作后状态、样本动作信息分别确定延时奖励值和成本奖励值,进而确定样本事件的事件奖励值,再将样本事件作为训练样本进行模型迭代训练,得到动作策略生成模型。这样,相较于凭借个人经验确定动作策略,通过样本事件确定延时奖励值和成本奖励值,基于表征动作效果的延时奖励值、表征动作成本的成本奖励值确定事件奖励值,并基于事件奖励值训练得到动作策略生成模型,基于强化学习算法得到的动作策略生成模型将动作效果和动作成本相结合,使得生成的动作策略不再局限于个人经验,更具有针对性,提高动作策略的实施效果,同时,提高了动作策略的生成效率。
技术特征:
1.一种动作策略生成模型训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,获取指定对象的样本事件集,包括:
3.根据权利要求1所述的方法,其特征在于,根据所述动作前状态和所述动作后状态之间的比较结果确定延时奖励值,包括:
4.根据权利要求1所述的方法,其特征在于,根据所述样本动作信息进行计算,得到成本奖励值,包括:
5.根据权利要求1所述的方法,其特征在于,动作策略生成模型通过以下方法生成动作策略:
6.根据权利要求1至5任一项所述的方法,其特征在于,将所述样本事件集作为训练样本对预设学习模型进行迭代训练,包括:
7.根据权利要求1至5任一项所述的方法,其特征在于,将所述样本事件集作为训练样本对预设学习模型进行迭代训练,包括:
8.一种动作策略生成模型训练装置,其特征在于,包括:
9.一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述动作策略生成模型训练方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述动作策略生成模型训练方法的步骤。
技术总结
本发明涉及人工智能及医疗健康技术领域,公开了一种动作策略生成模型训练方法、装置、设备及介质,包括:通过采集指定对象的样本事件,从而根据样本事件中的动作前状态、动作后状态、样本动作信息分别确定延时奖励值和成本奖励值,进而确定样本事件的事件奖励值,再将样本事件作为训练样本进行模型迭代训练,得到动作策略生成模型,通过样本事件确定延时奖励值和成本奖励值,基于表征动作效果的延时奖励值、表征动作成本的成本奖励值确定事件奖励值,并基于事件奖励值训练得到动作策略生成模型,基于强化学习算法得到的动作策略生成模型将动作效果和动作成本相结合,使得生成的动作策略不再局限于个人经验,提高动作策略的实施效果。
技术研发人员:张渊
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!