一种中英港语混合场景下自适应的地址库建设方法与流程
本发明公开涉及计算机技术与数据科学的交叉,尤其涉及一种中英港语混合场景下自适应的地址库建设方法。
背景技术:
1、随着大数据时代的到来,各行业基于地址数据利用大数据技术赋能行业发展,逐渐改变着人们的生活方式。与此同时人们发现使用语言混杂、写法不一、错误频出的非标准地址进行数据分析,会导致分析效率低、分析精度差、分析结果偏离等问题。因此对地址数据进行标准化并建立标准地址库的需求日益明显。标准地址库建设方面主流的研究成果如下:
2、现有技术1:发明创造名称:用户地理信息分析与文本挖掘方法和装置,申请号:申请号:201910515695.x,申请日:2019-06-14,申请人:哈尔滨哈银消费金融有限责任公司,对英文语句进行分词处理,根据预先规则计算地址相似度。类似的,深圳市小赢信息技术有限责任公司,一种中文地址标准化方法通过对中文地址的相似度分析,实现中文地址的标准化。现有成果仅实现了英语、中文等单一语种情况下的地址数据分析处理。
3、现有技术2:发明创造名称:基础地址库构建方法及系统,申请号:201611259136.x申请日:2016-12-30,申请人:深圳市华傲数据技术有限公司,将地址数据拆分成多个地址要素,并标注地址要素,在已有标准库中关联匹配地址中空缺的部分并补全当前地址,将补全后的标准地址存入基础地址库。仅适用地址可拆分场景下的地址库建设,不适用与带有语义无法对地址拆分条件下的地址提取。
4、现有技术3:发明创造名称:一种判断地址是否标准化、地址标准化的方法及系统,申请号:201910314344.2,申请日:2019-04-18,对汉语地址进行研究,将地址进行层级拆分,拆分后各个层级分别与标准地址库中的地址进行命中分析,以判断所采集地址是否已完成了地址标准化。仅适用地址可拆分且拆分后能够与标准地址库完成对比的场景,无法适应基于语义多语种混合情况下不同地址数据不能对比分析的情况。
5、已有成果在一定程度上能够完成简单场景下的标准数据库建设,但是还存在以下几个方面的问题总结为以下几点:
6、1、现有研究主要对中文、英文双语地址库的建设,仅能解决单一语言或中英混合场景下的标准地址库建设,缺少中文、港语、英语、港拼基于语义混合构成的标准地址库建设方法。
7、2、现有的地址库构建方式是基于标准地址,结合人工制定的规则实现文本中的地址信息提取。对于多语言混合且混合后带有语义的地址信息无法进行提取。如无法提取“chui wah rd sunshine st”地址。
8、3、现有地址库构建主要基于相似度对非标准地址和标准地址进行比对,无法适用于现有地址与标准地址基于语义关联的场景,对相同语义不同语言混合的地址关系无法对应,如无法将chui wah rd与翠華路对应。
技术实现思路
1、为克服相关技术中存在的问题,本发明公开实施例提供了一种中英港语混合场景下自适应的地址库建设方法。所述技术方案如下:
2、该中英港语混合场景下自适应的地址库建设方法,应用于信息数据处理终端,包括以下步骤:
3、步骤一、地址分类转换:根据语言特性不同,对中文、港语、英语、港拼混合构成的地址进行分类;
4、步骤二、地址语义解析:对于地址翻译和地址拆分比对无法处理的基于语义构成的地址数据,通过语义特征及地区语言文化特征解析生成中文地址;
5、步骤三、地址关联比对:对多语言混合数据进行语义层面的关联比对,提取缺失、矛盾的地址数据,同时提炼地址补全素材库,支撑后续地址核准及补全;
6、步骤四、地址核准及补全:对确实和矛盾的地址进行关联关系推理,补全缺失地址,消解矛盾冲突地址信息,形成标准中文地址库。
7、在一个实施例中,在步骤一中,地址分类转换包括以下步骤:
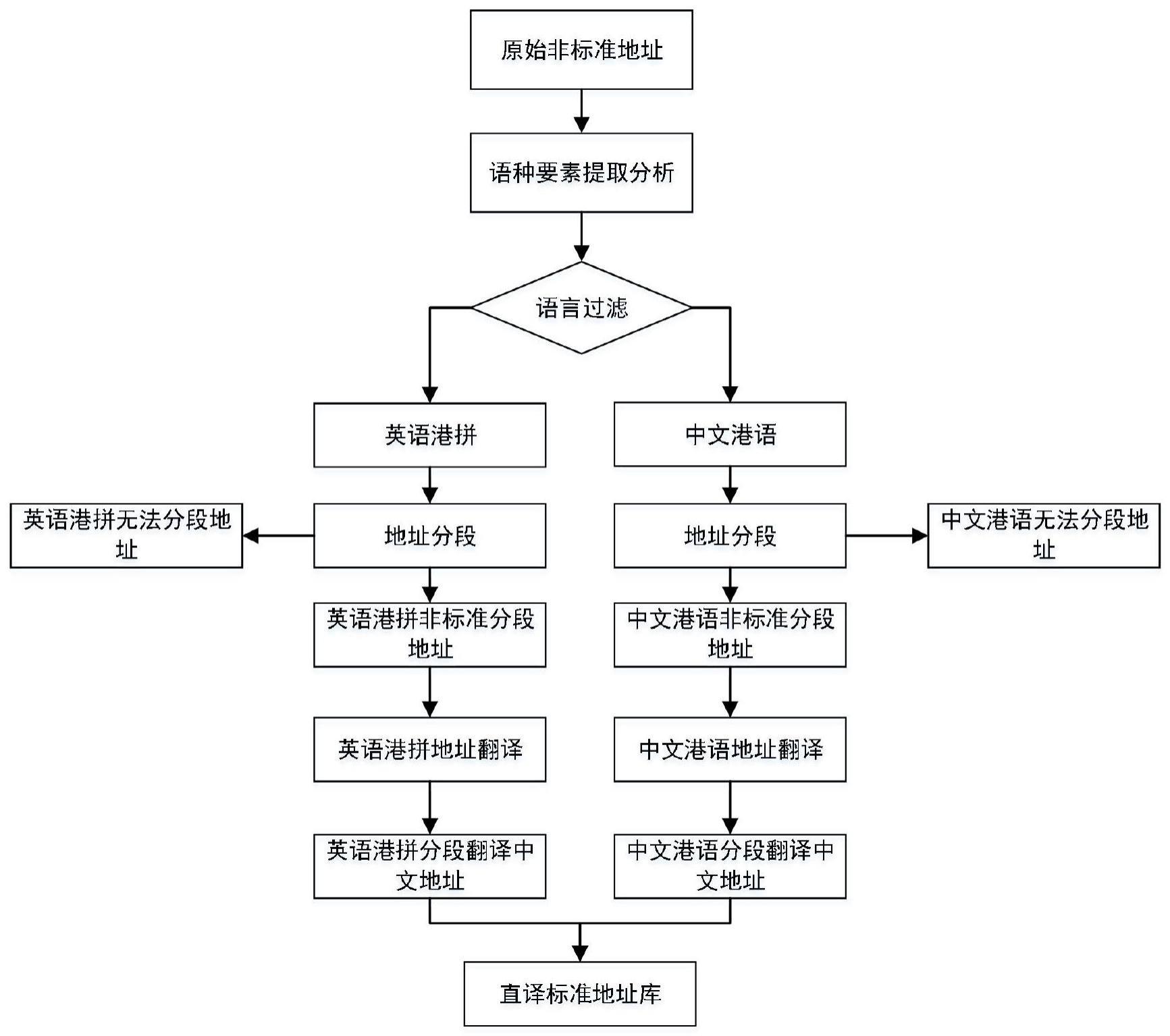
8、(1)对原始非标准数据进行语义要素提取分析;
9、(2)对原始非标准数据进行语言过滤,分为英语港拼地址数据和中文港语地址数据;
10、(3)对英语港拼地址进行分段,生成英语港拼非标准分段地址和英语港拼无法分段地址;
11、(4)对英语港拼非标准分段地址进行英语港拼地址翻译,形成英语港拼分段翻译中文地址;
12、(5)对中文港语地址进行分段,生成中文港语非标准分段地址和中文港语无法分段地址;
13、(6)对中文港语非标准分段地址进行中文港语地址翻译,形成中文港语分段翻译中文地址;
14、(7)结合英语港拼分段翻译中文地址和中文港语分段翻译中文地址生成直译标准地址库。
15、在一个实施例中,在步骤二中,地址语义解析包括以下步骤:
16、(1)根据直译标准地址库,提取数据分段翻译解析前的原始数据作为样本;
17、(2)提取数据的中文语义特征、港语语义特征、英语语义特征、港拼语义特征,构建本批次数据语义特征库;
18、(3)基于已有的单语种语义特征库、本批次数据语义特征库和基于开源情报的语言文化特征库,构建自适应混合语义特征提取模型;
19、(4)借助上述模型对无法进行分段翻译的语义地址进行地址提取,生成语义解析中文地址。
20、在一个实施例中,在步骤三中,地址关联比对包括以下步骤:
21、(1)根据原始数据中的中文地址、语义解析的中文地址和直译标准地址,进行地址关联比对;
22、(2)通过关联比对进行问题地址提取,提取生成需补全的非标准地址库和待核准的矛盾地址库;
23、(3)基于关联关系进行地址素材库提取,生成地址补全素材库。
24、在一个实施例中,在步骤四中,地址核准及补全包括以下步骤:
25、(1)基于地址补全素材库,对需补全的非标准地址库和待核准的矛盾地址库进行地址关联关系推理;
26、(2)基于地址补全素菜对存在缺失的地址片段进行补全;
27、(3)对存在冲突和矛盾的地址数据进行冲突的消解和矛盾地址判定;
28、(4)最终生成补全的标准中文地址库。
29、本发明公开的实施例提供的技术方案可以包括以下有益效果:
30、第一、本发明实现了中文、港语、英语、港拼混合地址场景下的标准地址库构建,突破了现有产品只支持单一语言或中英混合场景下的地址库建设短板。
31、第二、本发明实现了多语言混合场景下基于语义的地址数据提取,突破了现有产品无法对地址数据基于语义提取的短板,解决了中文、港语、英语、港拼基于语义混合场景下的数据提取难题。
32、第三、本发明具备自适应地址数据特征,并基于语义对非标准地址进行自动提取、关联比对和补全的能力。解决了现有产品对相同语义不同语言混合的地址无法进行对比和关联补全的难题。
33、当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
技术特征:
1.一种中英港语混合场景下自适应的地址库建设方法,其特征在于,应用于信息数据处理终端,该方法包括以下步骤:
2.根据权利要求1所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,在步骤一中,地址分类转换包括以下步骤:
3.根据权利要求2所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,地址分类转换还包括:
4.根据权利要求3所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,地址分类转换还包括:
5.根据权利要求1所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,在步骤二中,地址语义解析包括以下步骤:
6.根据权利要求5所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,地址语义解析还包括:
7.根据权利要求1所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,在步骤三中,地址关联比对包括以下步骤:
8.根据权利要求7所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,地址关联比对还包括:
9.根据权利要求1所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,在步骤四中,地址核准及补全包括以下步骤:
10.根据权利要求9所述的中英港语混合场景下自适应的地址库建设方法,其特征在于,地址核准及补全还包括:
技术总结
本发明公开是关于一种中英港语混合场景下自适应的地址库建设方法,涉及机械技术领域。地址分类转换:根据语言特性不同,对中文、港语、英语、港拼混合构成的地址进行分类;地址语义解析:对于地址翻译和地址拆分比对无法处理的基于语义构成的地址数据,通过语义特征及地区语言文化特征解析生成中文地址;地址关联比对:对多语言混合数据进行语义层面的关联比对,提取缺失、矛盾的地址数据,同时提炼地址补全素材库,支撑后续地址核准及补全;地址核准及补全:对确实和矛盾的地址进行关联关系推理,补全缺失地址,消解矛盾冲突地址信息,形成标准中文地址库。
技术研发人员:沈宜,刘汪洋,贾宇,廖伟
受保护的技术使用者:深圳市网联安瑞网络科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!