一种基于量化压缩的Yolov2-Tiny的目标检测FPGA加速器
本发明涉及yolov2-tiny网络计算加速领域,尤其涉及一种基于yolov2-tiny的目标检测用fpga加速器。
背景技术:
1、随着计算机视觉领域的快速发展,目标检测技术在道路监控、无人驾驶汽车、医学图像分析和国防安全等领域发挥着重要作用。yolov2-tiny(you only look once,yolo)目标检测算法模型将目标类别判定和位置信息结合在一个卷积神经网络中,加快检测速度的同时保持了检测精度。
2、在大多数实际应用中,目标检测技术都需要应用到嵌入式设备,目前市场主要使用gpu处理器,其效率远高于cpu处理器,但其功耗过高且价格昂贵,难以广泛适用于各种环境。针对目标检测的具体应用场景,终端设备离线小型化,研究方向逐渐转向asic和fpga。在asic上实现的神经网络具有较高的计算性能和较低的功耗,但其研发成本高,设计周期长,且不能通过重新编程来调整硬件结构,增加了设计的风险和成本。fpga作为一种现场可编程的逻辑器件,具有强大的可重构能力,极大地缩短了设计周期,且fpga具有高性能、低功耗、速度快的优点,是实现目标检测算法的良好选择。
3、然而采用fpga加速神经网络也面临着一些挑战,对于实时目标检测系统,yolov2-tiny网络结构相对较大,目标检测卷积神经网络计算访存密集,在推理预测过程将消耗大部分的计算时间、硬件资源和功耗,所以在资源有限的fpga上部署存在一定限制。
技术实现思路
1、发明目的:针对上述现有技术,提出一种基于量化压缩的yolov2-tiny目标检测卷积神经网络的fpga加速器,以保持精度为前提,减少神经网络模型的计算量或带宽要求,便于在pfga上完成部署。
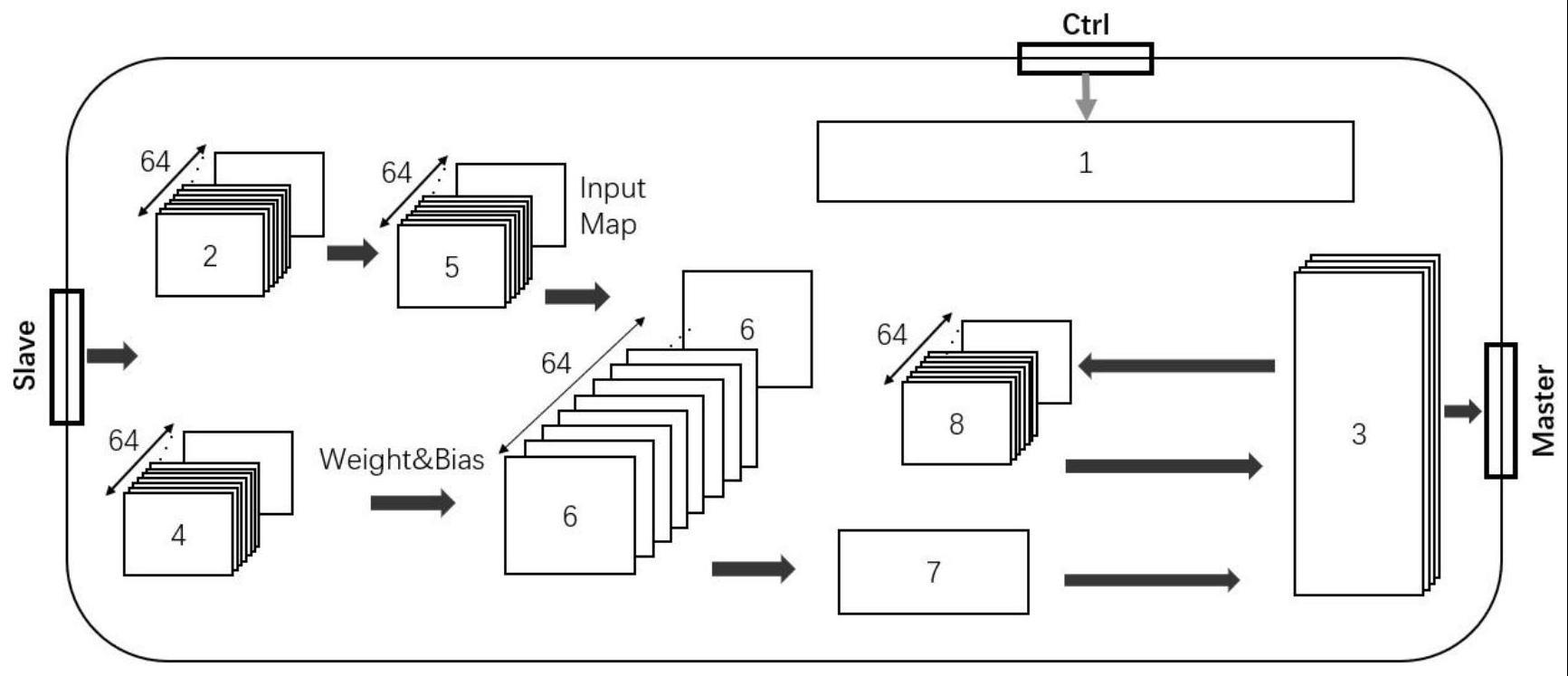
2、技术方案:一种基于量化压缩的yolov2-tiny的目标检测fpga加速器,包括状态控制单元、输入特征图缓存单元、输出特征图缓存单元、输入权重参数缓存单元、数据整形单元、卷积计算核心单元、通道累加单元、池化计算单元;其中,输入特征图缓存单元的输出连接数据整形单元,数据整形单元和输入权重参数缓存单元的输出连接卷积计算核心单元,卷积计算核心单元的输出连接通道累加单元,通道累加单元的输出连接输出特征图缓存单元,池化计算单元与输出特征图缓存单元连接,状态控制单元用于对各个单元进行状态控制;
3、所述基于量化压缩的yolov2-tiny中,每一层卷积层后都引入批归一化层,并将批归一化层与卷积层进行融合,融合后的权重参数和偏置参数通过软件预处理来进行更新;算法执行过程中,采用均匀量化的方式对权重参数进行逐层量化。
4、进一步的,算法执行过程中,将输入特征图分块,先按输入通道,再按输入特征图的宽,最后按输入特征图的高,依次获取输入特征图以及相应的权重参数和偏置参数,在进行卷积计算和池化计算后输出滑动立方体,直到整个层的卷积计算完成;对于连接到池化层的conv层,在输出滑动立方体写入片外存储器之前执行最大池化。
5、进一步的,采用特征图权重重用策略从ps端向pl端搬运数据,在卷积1-3层采用权重参数复用方式,后面层采用输入特征图复用方式;其中,对于权重参数数据,将每个卷积核的权重按照输出通道的顺序展开,首先将每个卷积核的权重展开为w0-w8,并附上对应通道的卷积核,再按照输出通道的顺序展开,并通过dma将该块数据从ddr中搬运到输入权重参数缓存单元的第一块权重缓存区,再重复上述过程,搬运后续的参数。
6、进一步的,所述数据整形单元采用4个移位寄存器,分别是:深度为20的移位寄存器一、深度为22的移位寄存器二、深度为20的移位寄存器三、深度为22的移位寄存器四;
7、当输入特征图长度配置为40时,输入特征图缓存单元的输出连接移位寄存器四的输入,移位寄存器四的输出连接移位寄存器三的输入,移位寄存器三的输出连接移位寄存器一的输入,移位寄存器一的输出连接移位寄存器二的输入,第一行数据从移位寄存器二输出,第二行数据从移位寄存器三输出,第三行数据直接从输入特征图缓存单元输出;
8、当输入特征图长度配置为20时,输入特征图缓存单元的输出连接移位寄存器四的输入,移位寄存器四的输出连接移位寄存器二的输入,第一行数据从移位寄存器二输出,第二行数据从移位寄存器四输出,第三行数据直接从输入特征图缓存单元输出。
9、进一步的,所述卷积计算核心单元采用流水线并行方式,卷积计算单元每次取出特征图的一列,对该列数据进行卷积计算,计算结果暂存在缓存中,等待下一次计算;在输入特征图开始输入三个周期后,形成流水线,即在接下来的每个时钟周期计算出下一个卷积核的计算结果。
10、进一步的,输入特征图缓存单元、输出特征图缓存单元、输入权重参数缓存单元均采用双端口block-ram,输入位宽64bit,输出位宽8bit,对所述输出特征图缓存单元做以下四组状态配置模式:当输出特征图缓存单元处于空闲状态时,没有数据的写入和读取,缓存模块不工作;当输出特征图缓存单元处于通道累加状态时,将上一次卷积计算对应的结果取出,与当前计算结果进行累加,并写回对应的存储地址,将原来的中间值覆盖;当输出特征图缓存单元处于池化状态时,将相应的卷积计算结果取出,进行relu函数激活,将小于零的数据清零,再经过数据整形后进行池化计算,池化计算的结果覆盖卷积计算的结果;当输出特征图缓存单元处于输出结果状态时,将每八个输出通道分为一组,安照分组顺序进行合并输出。
11、有益效果:1、将bn层与卷积层合并可以减少计算和通信开销,并且可以在一定程度上降低模型的复杂度。卷积神经网络具有较强的鲁棒性,即在降低数据位宽的情况下,网络也能保持一定的精度。通过降低神经网络模型的位宽,可以减少其资源开销。
12、2、权重参数和输入特征图结合的复用方式极大地减少了参数的传输量,有效降低硬件的存储功耗和卷积的推理时间。
13、3、arm-fpga可以实现高度并行的数据处理,在大规模数据处理和实时信号处理方面具有明显优势。
14、4、通过设计数据整形单元来代替地址产生器,使得能够在一个周期读取一列参与卷积计算的特征图,利用卷积数据复用的特点解决访问存储器的限制,从而提高卷积计算速度。
15、5、核心卷积计算模块采用流水线并行的设计方式,在输入特征图开始输入三个周期后,形成流水线,是整个硬件实现高吞吐量的关键。卷积计算单元可以实现高效的计算,提高卷积神经网络的计算速度。yolov2-tiny目标检测卷积神经网络可以在较短的时间内完成目标检测任务。
16、本发明从提高加速器吞吐量的角度出发,采用软硬件联合优化设计的方案,在算法实现的复杂性层面对网络进行压缩,采用卷积层融合、参数量化方式优化网络结构;在硬件实现层面,合理分配计算任务,设计高效的数据通路,优化硬件单元,以达到最优的计算性能。在保证精度损失的同时,也提高了硬件的能效比。
技术特征:
1.一种基于量化压缩的yolov2-tiny的目标检测fpga加速器,其特征在于,包括状态控制单元(1)、输入特征图缓存单元(2)、输出特征图缓存单元(3)、输入权重参数缓存单元(4)、数据整形单元(5)、卷积计算核心单元(6)、通道累加单元(7)、池化计算单元(8);其中,输入特征图缓存单元(2)的输出连接数据整形单元(5),数据整形单元(5)和输入权重参数缓存单元(4)的输出连接卷积计算核心单元(6),卷积计算核心单元(6)的输出连接通道累加单元(7),通道累加单元(7)的输出连接输出特征图缓存单元(3),池化计算单元(8)与输出特征图缓存单元(3)连接,状态控制单元(1)用于对各个单元进行状态控制;
2.根据权利要求1所述的基于量化压缩的yolov2-tiny的目标检测用fpga加速器,其特征在于,算法执行过程中,将输入特征图分块,先按输入通道,再按输入特征图的宽,最后按输入特征图的高,依次获取输入特征图以及相应的权重参数和偏置参数,在进行卷积计算和池化计算后输出滑动立方体,直到整个层的卷积计算完成;对于连接到池化层的conv层,在输出滑动立方体写入片外存储器之前执行最大池化。
3.根据权利要求1所述的基于量化压缩的yolov2-tiny的目标检测用fpga加速器,其特征在于,采用特征图权重重用策略从ps端向pl端搬运数据,在卷积1-3层采用权重参数复用方式,后面层采用输入特征图复用方式;其中,对于权重参数数据,将每个卷积核的权重按照输出通道的顺序展开,首先将每个卷积核的权重展开为w0-w8,并附上对应通道的卷积核,再按照输出通道的顺序展开,并通过dma将该块数据从ddr中搬运到输入权重参数缓存单元(4)的第一块权重缓存区,再重复上述过程,搬运后续的参数。
4.根据权利要求1-3任一所述的基于量化压缩的yolov2-tiny的目标检测用fpga加速器,其特征在于,所述数据整形单元(5)采用4个移位寄存器,分别是:深度为20的移位寄存器一(51)、深度为22的移位寄存器二(52)、深度为20的移位寄存器三(53)、深度为22的移位寄存器四(54);
5.根据权利要求4所述的基于量化压缩的yolov2-tiny的目标检测用fpga加速器,其特征在于,所述卷积计算核心单元(6)采用流水线并行方式,卷积计算单元每次取出特征图的一列,对该列数据进行卷积计算,计算结果暂存在缓存中,等待下一次计算;在输入特征图开始输入三个周期后,形成流水线,即在接下来的每个时钟周期计算出下一个卷积核的计算结果。
6.根据权利要求5所述的基于量化压缩的yolov2-tiny的目标检测用fpga加速器,其特征在于,输入特征图缓存单元(7)、输出特征图缓存单元(8)、输入权重参数缓存单元(4)均采用双端口block-ram,输入位宽64bit,输出位宽8bit,对所述输出特征图缓存单元(8)做以下四组状态配置模式:当输出特征图缓存单元处于空闲状态时,没有数据的写入和读取,缓存模块不工作;当输出特征图缓存单元处于通道累加状态时,将上一次卷积计算对应的结果取出,与当前计算结果进行累加,并写回对应的存储地址,将原来的中间值覆盖;当输出特征图缓存单元处于池化状态时,将相应的卷积计算结果取出,进行relu函数激活,将小于零的数据清零,再经过数据整形后进行池化计算,池化计算的结果覆盖卷积计算的结果;当输出特征图缓存单元处于输出结果状态时,将每八个输出通道分为一组,安照分组顺序进行合并输出。
技术总结
本发明公开了一种基于量化压缩的Yolov2‑Tiny目标检测FPGA加速器,该加速器包括:Yolov2‑Tiny网络层融合与量化部分、软硬件协同设计部分、数据流设计部分、硬件架构设计部分、状态控制单元、输入特征图缓存单元、输出特征图缓存单元、输入权重参数缓存单元、数据整形单元、卷积计算核心单元、池化计算单元。从提高加速器的能效比出发,采用软硬件联合优化设计的方案,在算法层面对网络进行压缩,采用卷积层融合、参数量化方式优化网络结构;在硬件实现层面,合理分配计算任务,设计高效的数据通路,优化硬件单元,在保证精度损失的同时,提高硬件的能效比。
技术研发人员:刘昊,王丽洁,陈健
受保护的技术使用者:东南大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!