一种基于自加权多视图k均值的聚类方法
本发明涉及数据处理,更具体的说是涉及一种基于自加权多视图k均值的聚类方法。
背景技术:
1、信息传播和收集的速度和规模已达到前所未有的水平,各种数据已开始激增。这些数据通常以不同的方式或透视图来描述,例如将每个类的特征表示称为视图。由多个视图描述的数据信息更丰富,其中许多信息可能有助于构建可靠和健壮的聚类模型。然而,信息越多,涉及噪声和冗余的概率就越高。这种维数的诅咒以及多视图的无效特征和噪声给大规模的、有噪声的多视图数据聚类带来了巨大的挑战。
2、为了解决这一挑战,许多视图集群(mvc)方法通过从多个视图的互补信息融合到将数据点集群到不同的集群中,在现实应用中发挥了关键作用。由于具有不同的相似结构,将基于判别方法的mvc方法应用于公共特征向量矩阵、公共系数矩阵和公共指标矩阵。前两种方法都是基于视图的聚类方法,因此视图的构造是一个关键问题。使用不同的内核构建视图极大地影响最终的聚类性能。此外,对于某些特定的内核,必须考虑参数选择的影响,从而使聚类结果对参数调优很敏感。更重要的是,这些基于视图的方法不能用于解决大规模的数据聚类问题,因为其无法解决大量的数据聚类问题。最具代表性的第三种方法是多视图k-means聚类,由于其高效、简单的性质,更适合于处理大数据集。
3、因此,如何提出一种基于自加权多视图k均值的聚类方法,具有优化性和收敛性,通过无监督学习有效地解决目标函数,实现多视图聚类过程中的鲁棒性和高效离群点抑制,是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于自加权多视图k均值的聚类方法,通过添加一个投影矩阵来实现子空间的学习。同时通过引入投影矩阵的l2,1范数惩罚项,实现特征选择和噪声抑制,将聚类中心矩阵表示为数据矩阵的凸组合,在加权特征的子空间中同步可以快速得到较好的聚类结果,为了实现上述目的,本发明采用如下技术方案:
2、一种基于自加权多视图k均值的聚类方法,包括:
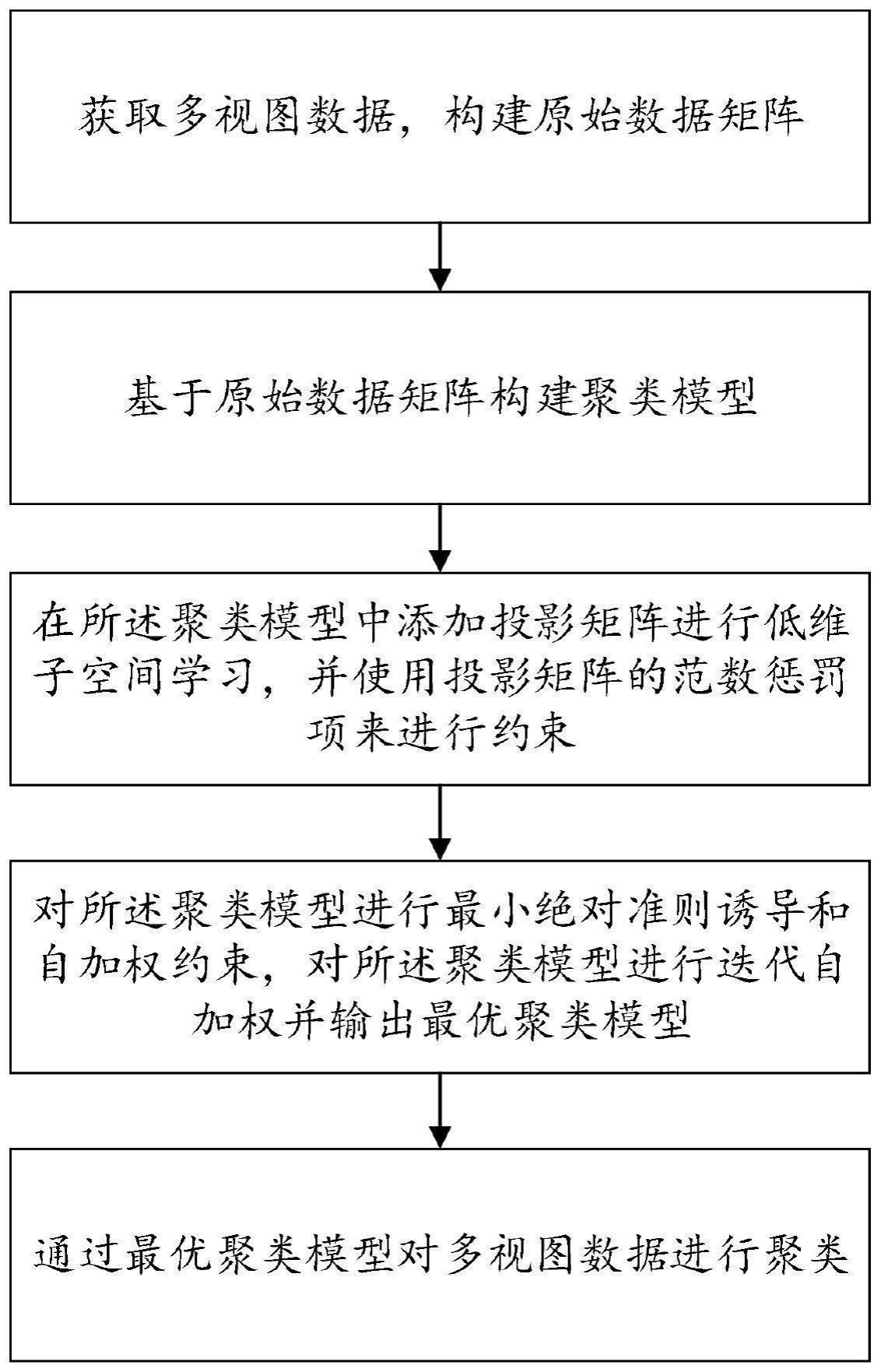
3、获取多视图数据,构建原始数据矩阵;
4、基于原始数据矩阵构建聚类模型;
5、在所述聚类模型中添加投影矩阵进行低维子空间学习,并使用投影矩阵的范数惩罚项来进行约束;
6、对所述聚类模型进行最小绝对准则诱导和自加权约束,通过迭代自加权输出最优聚类模型;
7、通过最优聚类模型对多视图数据进行聚类。
8、可选的,所述多视图数据包括多视图和高维数据。
9、可选的,所述基于原始数据矩阵构建聚类模型包括:
10、基于原始数据矩阵x构建多视图k均值聚类模型;
11、通过最小绝对准则诱导所述多视图k均值聚类模型的鲁棒性,获得鲁棒的k均值聚类模型;
12、对所述鲁棒的k均值聚类模型进行非负矩阵分解,在非负矩阵分解中定义基向量f位于原始数据矩阵x的列空间的凸组合中,得到nmf形式的聚类模型。
13、可选的,所述nmf形式的聚类模型为:
14、
15、
16、其中,d∈rn×k为聚类质心捕获矩阵,xd∈rm×k为聚类质心矩阵,s∈rk×n为聚类分配矩阵。
17、可选的,在所述聚类模型中添加投影矩阵进行低维子空间学习,并使用投影矩阵的范数惩罚项来进行约束包括:
18、将原始数据矩阵x的第v个视图投影到一个低维子空间,在所述聚类模型中引入一个新的投影矩阵w,定义投影矩阵d(v)'≤d(v);其中,d(v)'是低维子空间的特征维数,低维子空间表示为w(v)tx(v)。
19、可选的,所述低维子空间的优化目标为:
20、
21、
22、其中,β是调优参数,||w(v)||2,1是投影矩阵w的l2,1范数,d∈rn×k为聚类质心捕获矩阵,s∈rk×n为聚类分配矩阵。
23、可选的,对所述聚类模型进行最小绝对准则诱导和自加权约束,通过迭代自加权输出最优聚类模型包括:
24、对低维子空间的优化目标进行变化得到:
25、
26、
27、定义通过l2,1范数计算聚类指标矩阵,其中,α(v)为视图权重系数度,s为矩阵,d为亲和矩阵,w为投影矩阵。
28、可选的,所述计算聚类指标矩阵包括:
29、步骤一:计算α(v),更新每个视图的权重αk,给更高的权重分配更具判别性的图像特征,得到α(v)的封闭形式解;
30、步骤二:计算w(v),固定其他变量,通过公式计算w(v);
31、步骤三:计算d,固定其他变量,通过公式来计算d;
32、步骤四:计算s,固定其他变量,通过得出s的解;
33、步骤五:迭代重复步骤一至步骤四,直到目标函数值收敛。
34、可选的,还包括初始化,所述初始化为对聚类指示矩阵进行初始化:
35、
36、其中,ic∈rec×c为单位矩阵,zc∈rec×c为二进制矩阵的随机排序ic的行,1∈re[n÷c]×1为包含所有元素的列向量,利用向量1和矩阵zc的直接乘积来初始化g,如果n不能被c整除,则从zc中额外选择行,随机填充不可分割的部分。
37、可选的,对所述多视图数据进行降维设置,所述降维设置为:降低所述多视图数据的维数d,β是调优参数,参数β在10-6到106之间搜索,步长为0.5,通过搜索原始数据矩阵中每个视图的所有维数来搜索最佳聚类结果对应的维数d。
38、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于自加权多视图k均值的聚类方法,具有如下有益效果:
39、本发明通过添加一个投影矩阵来实现子空间的学习,同时通过引入投影矩阵的l2,1范数惩罚项,实现特征选择和噪声抑制,将聚类中心矩阵表示为数据矩阵的凸组合,在加权特征的子空间中同步可以快速得到较好的聚类结果。本发明提出了一种新颖的无监督聚类框架,实现了多视图聚类过程中的鲁棒性和高效离群点抑制,并实现了降维。采用迭代自加权方法,使用投影矩阵的2,1-范数惩罚项来抑制噪声,并以迭代重新加权的方式自适应地控制多个视角之间的协调。在不同的合成数据集和真实世界数据集上的大量实验结果表明,该程序算法在聚类性能和鲁棒性方面优于其他方法。
技术特征:
1.一种基于自加权多视图k均值的聚类方法,其特征在于,包括:
2.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,所述多视图数据包括多视图和高维数据。
3.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,所述基于原始数据矩阵构建聚类模型包括:
4.根据权利要求3所述的一种基于自加权多视图k均值的聚类方法,其特征在于,所述nmf形式的聚类模型为:
5.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,在所述聚类模型中添加投影矩阵进行低维子空间学习,并使用投影矩阵的范数惩罚项来进行约束包括:
6.根据权利要求5所述的一种基于自加权多视图k均值的聚类方法,其特征在于,所述低维子空间的优化目标为:
7.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,对所述聚类模型进行最小绝对准则诱导和自加权约束,通过迭代自加权输出最优聚类模型包括:
8.根据权利要求7所述的一种基于自加权多视图k均值的聚类方法,其特征在于,所述计算聚类指标矩阵包括:
9.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,还包括初始化,所述初始化为对聚类指示矩阵进行初始化:
10.根据权利要求1所述的一种基于自加权多视图k均值的聚类方法,其特征在于,对所述多视图数据进行降维设置,所述降维设置为:降低所述多视图数据的维数d,β是调优参数,参数β在10-6到106之间搜索,步长为0.5,通过搜索原始数据矩阵中每个视图的所有维数来搜索最佳聚类结果对应的维数d。
技术总结
本发明公开了一种基于自加权多视图k均值的聚类方法,涉及数据处理技术领域,包括:获取多视图数据,构建原始数据矩阵;基于原始数据矩阵构建聚类模型;在所述聚类模型中添加投影矩阵进行低维子空间学习,并使用投影矩阵的范数惩罚项来进行约束;所述聚类模型用了最小绝对准则诱导和自加权约束,对所述聚类模型进行迭代自加权并输出最优聚类模型;通过最优聚类模型对多视图数据进行聚类。本发明采用最小绝对准则来诱导鲁棒性,有效减少了异常值的影响,同时将自加权技术应用于多视图k均值,实现降维和抑制噪声,具有优秀的聚类效果。
技术研发人员:徐慧英,朱信忠,林合川,汪紫莹,刘子洋
受保护的技术使用者:浙江师范大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!